مدلهای بینایی-زبانی (Vision-Language Models) دستهای از مدلهای هوش مصنوعی چندرسانهای هستند که به طور همزمان دادههای تصویری و متنی را پردازش کرده و قادر به انجام طیف گستردهای از وظایف هستند. این مدلها با ترکیب یک رمزگذار تصویری (Vision Encoder) و یک مدل زبان (Language Model) ساخته میشوند و بدین ترتیب قابلیت «دیدن» و تحلیل محتوای بصری را به تواناییهای زبانی مدل میافزایند.
برخلاف مدلهای کلاسیک بینایی ماشین که تنها بر روی مجموعهای محدود و از پیش تعریفشده از کلاسها (مثلاً تشخیص گربه یا سگ) آموزش میبینند، VLM ها میتوانند با دریافت یک تصویر و یک پرامپت متنی از کاربر، وظایفی متنوع نظیر توصیف تصویر، پاسخ به پرسشهای مرتبط با تصویر، طبقهبندی انعطافپذیر بدون محدودیت کلاس، تشخیص متن در تصویر (OCR) و بسیاری کاربردهای دیگر را انجام دهند.
یکی از ویژگیهای برجسته این مدلها، توانایی zero-shot است؛ به این معنا که حتی بدون آموزش مستقیم بر روی یک وظیفه خاص، میتوانند آن را با دقت قابلقبولی انجام دهند. این قابلیت، VLM ها را به ابزارهایی قدرتمند و چند منظوره در حوزه پردازش تصویر و زبان تبدیل کرده است.
اجزای اصلی یک مدل بینایی-زبانی
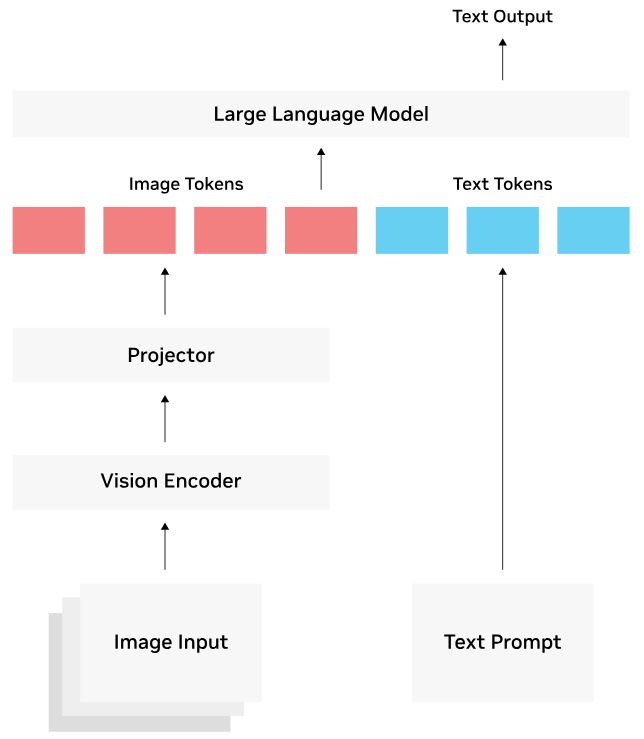
معماری یک مدل بینایی-زبانی معمولاً از سه بخش اصلی تشکیل میشود: رمزگذار تصویری، لایه نگاشت (Projection Layer) و مدل زبانی. در این ساختار، رمزگذار تصویری – که اغلب بر پایه معماریهای پیشآموزشدیدهای مانند CLIP ساخته میشود – تصویر ورودی را دریافت کرده و آن را به بردارهای تعبیه (Embeddings) با ابعاد مشخص تبدیل میکند.
لایه نگاشت، که میتواند شامل یک یا چند لایه ساده و حتی یک شبکه عمیقتر باشد، به عنوان پل ارتباطی میان بخش بینایی و بخش زبانی عمل میکند. این لایه، خروجی رمزگذار تصویری را به شکلی بازنمایی میکند که با قالب ورودی مدل زبان سازگار باشد؛ معمولاً این تبدیل شامل نگاشت بردارهای تصویری به فضای تعبیه توکنهای متنی است.
در گام نهایی، مدل زبانی (مانند GPT، LLaMA یا Vicuna) توکنهای حاصل از نگاشت – به همراه هر متن ورودی کاربر – را پردازش کرده و پاسخ متنی تولید میکند. به بیان دیگر، رمزگذار تصویر و لایه نگاشت، محتوای بصری را به «زبان» مدل زبانی ترجمه میکنند و بدین ترتیب مدل زبانی قادر میشود همچون یک دستیار چندرسانهای، به ورودیهای ترکیبی تصویر و متن پاسخ دهد.
نمونهای از کاربردهای مدلهای بینایی-زبانی
مدلهای بینایی-زبانی در حوزههای گوناگونی کاربرد دارند. به طور کلی، هر زمان که نیاز باشد خروجی متنی متناسب با ورودی تصویری تولید شود یا ورودی تصویری بر اساس دستور متنی تحلیل گردد، این مدلها میتوانند نقش مؤثری ایفا کنند. برخی از کاربردهای رایج آنها عبارتاند از:
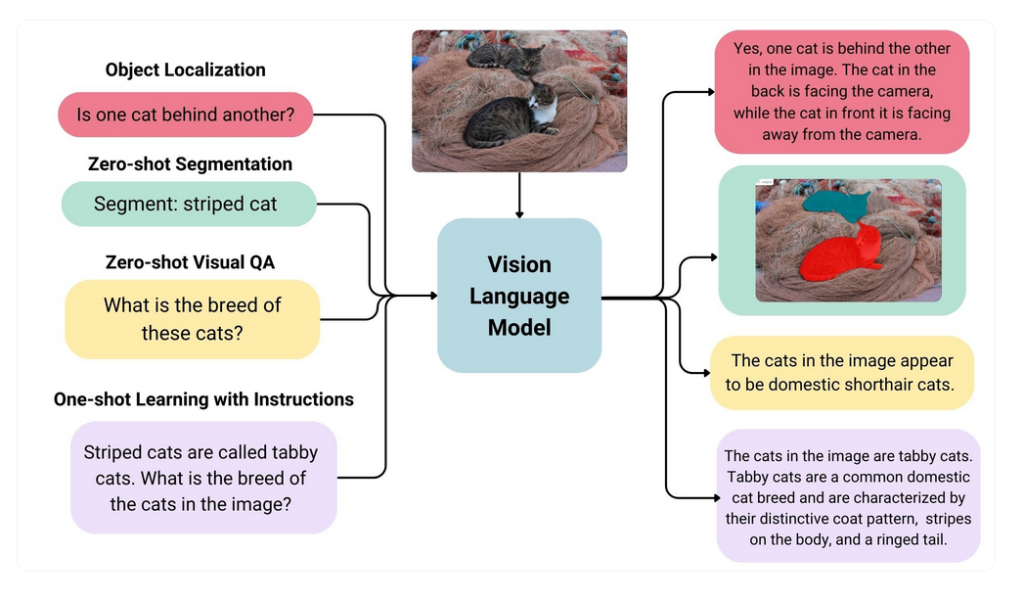
- تشخیص اشیاء (Object Detection): با استفاده از پرامپت متنی میتوان از برخی VLMها خواست تا موجودیت خاصی را در تصویر شناسایی کنند. به عنوان مثال، مدل میتواند با دستور «گربهی راهرونده» مختصات جعبهی مرزی (Bounding Box) آن را ارائه دهد یا با دستور «پرنده روی سقف را پیدا کن» محل پرنده را مشخص کند.
- تقسیمبندی اشیاء (Image Segmentation): این مدلها قادرند ناحیه دقیق مربوط به یک شیء را از تصویر جدا کنند. برخی از آنها حتی خروجی ماسک جداسازی را به صورت توکن تولید کرده و سپس آن را به تصویر تبدیل میکنند.
- شمارش اشیاء: مدلهایی مانند Qwen 2.5-VL توانایی شمارش نمونههای متعدد از یک شیء در تصویر را دارند؛ برای مثال شمارش تعداد افراد حاضر در یک عکس یا تعداد خودروهای موجود در یک خیابان.
- تشخیص متن (OCR) و درک اسناد: VLMها میتوانند متنهای موجود در تصاویر را استخراج کرده و حتی معنا و مفهوم آنها را تحلیل کنند. به طور پیشفرض، بسیاری از این مدلها در تشخیص متن (OCR) عملکرد zero shot قدرتمندی دارند. برای نمونه، مدلهایی مانند Fuyu-8B به طور ویژه برای استخراج متن از تصاویر توسعه یافتهاند.
- توصیف تصویر (Image Captioning): این مدلها میتوانند با مشاهده یک تصویر، توضیحی متنی و روان از محتوای آن ارائه دهند؛ برای مثال جمله «یک کودک در حال دوچرخهسواری در پارک» را برای تصویری با همین محتوا تولید کنند. این قابلیت به ویژه در سامانههای کمک به نابینایان یا جستجوی هوشمند تصاویر کاربرد فراوان دارد.
- پاسخ به سوالات تصویری (Visual Question Answering – VQA): کاربر میتواند پرسشهایی مانند «چه چیزی در این تصویر وجود دارد؟» یا «این شخص چه کاری انجام میدهد؟» را مطرح کند و مدل بر اساس محتوای تصویر پاسخ دهد.
- طبقهبندی تصویر با دستورات آزاد: برخلاف مدلهای قدیمی که تنها روی دستهبندیهای ثابت کار میکردند، VLMها میتوانند بر اساس پرامپت متنی دلخواه، تصاویر را به دستههای مختلف تقسیم کنند. برای مثال «این شی چه رنگی دارد؟» یا «این تصویر چه احساسی را منتقل میکند؟».
- بازیابی تصویر (Image Retrieval): کاربر میتواند یک عبارت متنی را به عنوان جستجو وارد کند و مدل، تصاویر مرتبط را از میان یک مجموعه بازیابی کند. به عنوان نمونه، در فروشگاههای آنلاین میتوان کالایی را با یک توصیف متنی جستجو و تصاویر مرتبط را مشاهده کرد.
این موارد تنها بخشی از کاربردهای گسترده مدلهای بینایی-زبانی هستند. در عمل، انعطافپذیری و توانایی zero shot این مدلها باعث شده است که بتوانند در حوزههای متنوعی از پزشکی و رباتیک گرفته تا تولید محتوا، واقعیت افزوده و دستیارهای هوشمند مورد استفاده قرار گیرند.
چالشهای اصلی
با وجود تواناییهای چشمگیر، مدلهای بینایی–زبانی با چند چالش اساسی مواجهاند که توسعه و استفادهی عملی از آنها را دشوار میکند:
۱. حجم بالای پارامترها و نیاز به منابع محاسباتی سنگین
معماری این مدلها معمولاً از ترکیب چندین شبکه بزرگ تشکیل میشود که گاهی میلیاردها پارامتر دارند. این حجم عظیم باعث میشود آموزش و اجرای آنها به زیرساختهای بسیار قدرتمند مانند خوشههای GPU یا TPU نیاز داشته باشد. در مقابل، کوچکتر کردن مدل برای کاهش مصرف منابع اغلب منجر به افت قابلتوجه دقت میشود؛ بنابراین یک تعادل دشوار بین کارایی و اندازه مدل وجود دارد.
۲. نیاز به دادههای عظیم و فرآوری پرهزینه آنها
برای آموزش مؤثر یک VLM، معمولاً به میلیاردها جفت تصویر–متن نیاز است. جمعآوری چنین حجم بزرگی از داده، پالایش و پیشپردازش آن (مانند حذف دادههای بیکیفیت، تراز کردن توصیفات متنی با تصاویر، و فیلتر محتوای نامناسب) فرآیندی بسیار زمانبر و پرهزینه است. علاوه بر هزینه، در برخی حوزهها مانند دادههای پزشکی یا صنعتی، دسترسی به دادهی کافی و با کیفیت بالا نیز محدود و دشوار است.
۳. کمبود تنوع و کیفیت دادههای آموزشی
دادههایی که برای پیشآموزش این مدلها استفاده میشود اغلب شامل توصیفهای کوتاه و ساده است و کمتر شامل مفاهیم بصری ظریف یا ارتباطات معنایی پیچیده میشود. این موضوع باعث میشود مدلها در وظایف نیازمند استدلال پیشرفته یا تحلیل جزئیات خاص عملکرد ضعیفتری داشته باشند.
۴. دشواری ارزیابی عملکرد
در بسیاری از وظایف چندرسانهای، ارزیابی کیفیت خروجی مدل کار سادهای نیست. برای مثال، یک تصویر ممکن است چندین توصیف معتبر داشته باشد یا پاسخ به یک سوال تصویری بتواند در قالبهای متفاوتی بیان شود. در نتیجه، معیارهای کمی سنتی همیشه نمایانگر دقیق کیفیت واقعی خروجی نیستند و ارزیابی انسانی نیز هزینهبر و زمانبر است.
به طور خلاصه، نیاز به منابع محاسباتی بالا، حجم عظیم داده و هزینههای فرآوری آن، کمبود تنوع دادهها، و دشواری ارزیابی خروجیها از جمله مهمترین موانع پیش روی توسعه و کاربرد گسترده مدلهای بینایی–زبانی هستند.
اهمیت پرامپتنویسی در VLM ها
همانطور که در مدلهای زبانی بزرگ (LLM) کیفیت و دقت پاسخ به شدت به پرامپت مناسب وابسته است، در مدلهای بینایی–زبانی (VLM) نیز طراحی دقیق پرامپت متنی نقش کلیدی دارد. هر VLM ممکن است قالب (Template) یا ساختار ورودی خاص خود را داشته باشد و رعایت همین قالب میتواند تفاوت محسوسی در کیفیت خروجی ایجاد کند.
اما رعایت قالب تنها بخشی از ماجراست؛ پرامپت باید دقیق، شفاف و هدفمند نوشته شود تا مدل دقیقاً همان خروجی را تولید کند که انتظار میرود. بیان مبهم یا کلیگویی در پرامپت اغلب باعث نتایج نامرتبط یا کمکیفیت میشود. به همین دلیل، توضیح کامل جزئیات مورد نظر (مانند نوع شیء، سبک تصویر، زاویه دید، یا زمینهی مورد انتظار) اهمیت زیادی دارد.
همچنین، مطالعهی راهنماها، نمونهها و دستورالعملهای رسمی یا غیررسمی پرامپتنویسی برای هر مدل میتواند به بهبود کیفیت درخواستها کمک کند. این کار نه تنها سرعت رسیدن به خروجی مطلوب را افزایش میدهد، بلکه نیاز به آزمون و خطای زیاد را نیز کاهش میدهد.
دسترسی به بهترین مدلهای VLM
برای مقایسه و انتخاب مدلهای بینایی-زبانی، ابزارهایی مانند Open VLM Leaderboard (در Hugging Face) رتبهبندی مدلها را بر اساس بنچمارکهای استاندارد ارائه میدهند. این پلتفرمها امکان فیلتر کردن بر اساس معیارهایی مثل دقت، تعداد پارامتر، و نوع دسترسی (متنباز یا تجاری) را فراهم میکنند.
مدلها بر اساس عملکرد در وظایف مختلف (مثل OCR، پاسخگویی به پرسش تصویری و استدلال چندرسانهای) مقایسه میشوند. این رتبهبندیها بهروز بوده و شامل مدلهای متنباز و تجاری است، هرچند فقط مدلهایی را پوشش میدهند که توسط توسعهدهندگان ثبت شده باشند.
نمونهای از بهترین و پایهای ترین مدلهای VLM
- CLIP
- Blip3
- Siglip
- Flamingo
- LLAVA
- Kosmos-2
- PaliGemma2
- SmolVLM
- Qwen2.5-VL
- InternVL3