

هوش مصنوعی چیست؟
برای پاسخ به این پرسش بنیادین، دستکم باید به دو منبع معتبر مراجعه کرد:
نخست، کتاب «هوش مصنوعی: رویکردی مدرن» (Artificial Intelligence: A Modern Approach) تألیف استوارت راسل و پیتر نورویگ. این کتاب، معتبرترین مرجع دانشگاهی در این حوزه به شمار میرود و نقطهٔ شروعی بسیار مناسب برای ورود به دنیای هوش مصنوعی است. در این اثر حجیم و تقریباً ۱۲۰۰ صفحهای، دو نکتهٔ کلیدی وجود دارد:
- ساختاری جامع و منسجم از کل موضوع در اختیار خواننده قرار میدهد و اصطلاحات و مفاهیم بنیادی این حوزه را معرفی میکند.
- از پرداختن به مطالب حاشیهای و کماهمیت پرهیز دارد و مستقیماً بر محتوای ارزشمند متمرکز است.
در صورت علاقه، میتوانید اطلاعات بیشتر را در صفحهٔ رسمی این کتاب در وبسایت دانشگاه برکلی بیابید:
Artificial Intelligence: A Modern Approach, 4th Global ed
منبع دوم، صفحهٔ انگلیسی «هوش مصنوعی» در ویکیپدیا است. این صفحه در حدود ۱۴ هزار کلمه، توضیحی سادهتر و جمعوجورتر از موضوع ارائه میدهد. البته از نظر جامعیت و انسجام به پای کتاب راسل و نورویگ نمیرسد، اما همچنان نقطهٔ شروع قابلقبولی برای خوانندگان تازهوارد محسوب میشود:
Artificial intelligence – Wikipedia
اما اگر فرصت یا حوصلهٔ مطالعهٔ مستقیم این منابع را ندارید، جای نگرانی نیست. مقالهای که اکنون در حال مطالعهٔ آن هستید، تلاشی است برای ارائهٔ یک جمعبندی جامع بر اساس چنین منابع معتبری. هدف من این بوده است که پاسخی روشن، دقیق و در عین حال ساده به پرسش «هوش مصنوعی چیست؟» ارائه کنم. تمرکز اصلی بر کتاب راسل و نورویگ خواهد بود، اما در گذر زمان منابع تکمیلی دیگری نیز وارد بحث خواهیم کرد.
همچنین اشاره کنم که برای رعایت اصول بهینهسازی و بهبود نمایش محتوا در موتورهای جستوجو، در برخی بخشها توضیحاتی تکمیلی با علامت ستاره (*) افزوده شده است. این توضیحات علاوه بر نقشی که در بهتردیدهشدن متن دارند، تلاش میکنند موضوعی را به سادهترین شکل بیان کنند. مخاطبانی که صرفاً بر محتوای اصلی تمرکز دارند، میتوانند از این بخشها عبور کنند.
هوش مصنوعی به زبان ساده *
هوش مصنوعی (AI) در واقع تلاشی است برای ساخت سیستمها و برنامههایی که بتوانند کارهایی را انجام دهند که معمولاً به هوش انسان نیاز دارند، مانند یادگیری، تصمیمگیری و حل مسئله. به زبان ساده، وقتی یک نرمافزار بتواند یاد بگیرد از تجربهٔ خود و رفتارهایش را بهبود دهد، یا بتواند پیشبینیهایی انجام دهد، در واقع با هوش مصنوعی AI سر و کار داریم. این مفهوم همان چیزی است که در منابعی با عنوان هوش مصنوعی به زبان ساده توضیح داده میشود و هدف آن این است که ماشینها بتوانند کارهای هوشمندانه انجام دهند، بدون اینکه برای هر مرحله نیاز به دستور مستقیم انسان داشته باشند.
هوش مصنوعی چیست و چه کاربردی دارد؟ *
هوش مصنوعی، یا همان AI چیست؟ یک فناوری گسترده است که کاربردهای متنوعی دارد؛ از پیشنهاد فیلم و موسیقی در سرویسهای آنلاین گرفته تا رانندگی خودکار و تشخیص بیماریها در پزشکی. به زبان ساده، هر جایی که یک سیستم بتواند دادهها را تحلیل کند، الگوها را تشخیص دهد و تصمیمی بگیرد، ما با هوش مصنوعی AI artificial intelligence مواجه هستیم. منابع آموزشی و مقالاتی که تحت عنوان خلاصه هوش مصنوعی یا همه چیز درباره هوش مصنوعی منتشر میشوند، همین کاربردها و اهمیت آنها را به خوبی توضیح میدهند. این کاربردها میتوانند زندگی روزمرهٔ ما را راحتتر کنند و به صنایع مختلف کمک کنند تا کارآمدتر و دقیقتر عمل کنند.
بخش ۱: مقدمه
ما انسانها خود را «Homo sapiens» یا «انسان خردمند» مینامیم، زیرا هوش برای ما اهمیت فوقالعادهای دارد. برای هزاران سال، بشر تلاش کرده است تا بفهمد چگونه فکر میکنیم و عمل میکنیم؛ به عبارت دیگر، چگونه مغزی که تنها مجموعهای کوچک از ماده است، میتواند جهانی بسیار بزرگتر و پیچیدهتر از خود را درک، پیشبینی و حتی هدایت کند.

هوش مصنوعی، یا AI، به ما این امکان را میدهد که نه تنها فرآیندهای شناختی انسان را درک کنیم، بلکه موجودات هوشمندی بسازیم—ماشینهایی که قادرند در موقعیتهای جدید و متنوع، به شیوهای مؤثر و ایمن تصمیم بگیرند و عمل کنند. اهمیت AI تنها به درآمد اقتصادی عظیم آن محدود نمیشود—اگرچه این حوزه سالانه بیش از یک تریلیون دلار درآمد ایجاد میکند—بلکه به دلیل اثرات گسترده آن بر تمامی عرصههای زندگی بشر، از نظر علمی و فکری نیز بیسابقه است.
مرزهای دانش در هوش مصنوعی هنوز باز و وسیع است. در حالی که دانشمندی که در فیزیک تحصیل میکند ممکن است احساس کند بهترین ایدهها توسط گالیله، نیوتن، کوری یا انیشتین کشف شدهاند، هوش مصنوعی هنوز زمینههای فراوانی برای نوآوری و خلاقیت در اختیار ذهنهای تماموقت و بلندپرواز قرار میدهد.
هوش مصنوعی مجموعهای وسیع از زیرشاخهها را شامل میشود؛ از موضوعات عمومی مانند یادگیری، استدلال و ادراک، تا زمینههای خاص مانند بازی شطرنج، اثبات قضایای ریاضی، نوشتن شعر، هدایت خودرو یا تشخیص بیماریها. به عبارت دیگر، هر کار فکری انسانی میتواند با هوش مصنوعی مرتبط باشد؛ این حوزه واقعاً یک علم جهانی است که دامنه کاربرد و تأثیر آن به طور پیوسته در حال گسترش است.
۱.۱ هوش مصنوعی چیست؟
هوش مصنوعی، یا AI، مفهومی است که تعاریف مختلفی برای آن ارائه شده است و پژوهشگران از دیرباز مسیرهای متفاوتی برای بررسی آن دنبال کردهاند. برخی هوش را با شباهت عملکرد آن به رفتار انسانی تعریف میکنند، یعنی سیستمی که بتواند مانند انسان تصمیم بگیرد و عمل کند. گروه دیگر، هوش را بهصورت انتزاعی و رسمیتر، تحت عنوان «منطقمندی» یا Rationality تعریف میکنند؛ به عبارت ساده، انجام دادن «کار درست» در موقعیتهای مختلف.
در تحلیل این مفاهیم، دو بعد اصلی وجود دارد: یکی بعد انسانمحور در مقابل منطقمحور، و دیگری بعد درونی اندیشه در مقابل رفتار بیرونی. ترکیب این دو بعد چهار رویکرد متفاوت در هوش مصنوعی ایجاد میکند، و هر کدام از این رویکردها دارای برنامههای پژوهشی و پیروان خاص خود هستند.
رویکرد انسانمحور و درونی، به بررسی فرآیندهای ذهنی و تفکر انسان میپردازد و بیشتر جنبه تجربی و روانشناختی دارد؛ به این معنا که مشاهده رفتار واقعی انسانها و ایجاد فرضیه درباره نحوه تصمیمگیری و تفکر آنها بخش مهمی از این مسیر است. در مقابل، رویکرد منطقمحور و بیرونی، ترکیبی از ریاضیات و مهندسی است و ارتباط نزدیکی با آمار، نظریه کنترل و اقتصاد دارد.
شایان ذکر است که در نگاه عمومی، گاهی اوقات مفاهیم «هوش مصنوعی» و «یادگیری ماشین» با یکدیگر اشتباه گرفته میشوند. یادگیری ماشین شاخهای از هوش مصنوعی است که توانایی بهبود عملکرد سیستمها بر اساس تجربه را مطالعه میکند. برخی سیستمهای هوش مصنوعی از روشهای یادگیری ماشین برای رسیدن به شایستگی استفاده میکنند، ولی برخی دیگر از این روشها بهره نمیبرند.
هوش مصنوعی محدود (Artificial Narrow Intelligence) *
هوش مصنوعی محدود، که اغلب با اصطلاح AI چیست و یا هوش مصنوعی AI artificial intelligence در منابع آموزشی مطرح میشود، به سیستمهایی اشاره دارد که برای انجام یک یا چند وظیفهٔ مشخص طراحی شدهاند. این سیستمها قادرند در حوزهٔ تخصصی خود بسیار دقیق و کارآمد عمل کنند، اما فراتر از آن حوزه توانایی تفکر یا تصمیمگیری ندارند. برای مثال، سیستمهای تشخیص تصویر، دستیارهای صوتی مثل Siri و Alexa، یا برنامههای بازی شطرنج نمونههایی از هوش مصنوعی محدود هستند. اگر بخواهید یک خلاصه هوش مصنوعی به زبان ساده داشته باشید، میتوان گفت ANI همان هوش مصنوعیای است که در زندگی روزمره بیشتر با آن مواجه هستیم و محدود به کاربردهای مشخص است.
هوش مصنوعی عمومی (Artificial General Intelligence) *
هوش مصنوعی عمومی یا AGI، در مقابل هوش محدود، به سیستمی اشاره دارد که توانایی یادگیری، درک و تصمیمگیری در طیف گستردهای از مسائل را دارد؛ درست مانند ذهن انسان. AGI میتواند دانش و تجربهٔ خود را از یک حوزه به حوزهٔ دیگر منتقل کند و در شرایط جدید به شیوهای هوشمندانه عمل کند. این نوع هوش هنوز در عمل محقق نشده و بیشتر در حوزهٔ تحقیقاتی و آیندهپژوهی مطرح است. برای کسانی که به دنبال همه چیز درباره هوش مصنوعی هستند، درک تفاوت میان ANI و AGI یک گام مهم برای شناخت عمیقتر هوش مصنوعی AI است.
۱.۱.۱ رفتار انسانی: رویکرد آزمون تورینگ
تست تورینگ که توسط آلن تورینگ در سال ۱۹۵۰ مطرح شد، یک آزمایش فکری است که هدف آن اجتناب از ابهام فلسفی سؤال «آیا ماشین میتواند بیندیشد؟» بود. در این آزمایش، یک کامپیوتر موفق است اگر یک بازپرسی انسانی پس از طرح چند سؤال کتبی نتواند تشخیص دهد که پاسخها توسط انسان ارائه شده یا کامپیوتر.

برای اینکه یک کامپیوتر بتواند این تست را با موفقیت پشت سر بگذارد، نیازمند تواناییهای متعددی است: پردازش زبان طبیعی برای برقراری ارتباط مؤثر با زبان انسانی، نمایش دانش برای ذخیرهسازی آنچه میداند یا میشنود، استدلال خودکار برای پاسخ به پرسشها و استخراج نتایج جدید، و یادگیری ماشین برای تطبیق با شرایط جدید و شناسایی الگوها. تورینگ بر این باور بود که شبیهسازی فیزیکی انسان برای اثبات هوشمندی لازم نیست.
با این حال، برخی محققان مفهوم «تست تورینگ کامل» را پیشنهاد کردهاند که شامل تعامل با اشیاء و انسانها در جهان واقعی است. برای موفقیت در این تست، یک ربات باید تواناییهایی مانند بینایی کامپیوتری و تشخیص گفتار برای درک محیط، و رباتیک برای جابجایی اشیاء و حرکت در محیط را داشته باشد.
این شش حوزه، بخش عمدهای از هوش مصنوعی را تشکیل میدهند. با این حال، بسیاری از پژوهشگران هوش مصنوعی تلاش چندانی برای عبور از تست تورینگ نکردهاند و بر اهمیت مطالعه اصول بنیادین هوش تأکید دارند. موفقیت در حوزههای مهندسی پیچیده مانند هوانوردی، زمانی حاصل شد که مهندسان به جای تقلید مستقیم از پرندگان، با استفاده از تونل باد و مطالعه آیرودینامیک به طراحی پرداختند؛ هدف علوم مهندسی هوافضا، ساخت ماشینی که دقیقاً مانند کبوتر پرواز کند نیست، بلکه درک اصول پرواز و به کارگیری آن است.
۲.۱.۱ تفکر انسانی: رویکرد مدلسازی شناختی
برای آنکه بگوییم یک برنامه «مانند انسان فکر میکند»، ابتدا باید بدانیم انسانها چگونه میاندیشند. شناخت فرآیندهای ذهنی انسان را میتوان به سه شیوه دنبال کرد:
- خودکاوی (Introspection): تلاش برای ثبت و مشاهدهٔ افکار خود در لحظهٔ وقوع.
- آزمایشهای روانشناختی: مشاهدهٔ رفتار و عملکرد افراد در شرایط کنترلشده و ثبت پاسخها و تصمیمگیریهای آنها.
- تصویربرداری مغزی: رصد فعالیتهای مغز هنگام انجام وظایف مختلف و تحلیل الگوهای عصبی مرتبط با تفکر.
زمانی که نظریهای دقیق و قابلسنجش دربارهٔ ذهن انسان در دست داشته باشیم، میتوان این نظریه را به شکل برنامهٔ کامپیوتری بیان کرد. اگر رفتار ورودی-خروجی برنامه با رفتار انسانی متناظر باشد، این امر نشان میدهد که بخشی از مکانیزمهای برنامه ممکن است مشابه سازوکارهای ذهنی انسان عمل کنند.
برای نمونه، آلن نیوِل و هربرت سایمون که سیستم GPS یا «حلکنندهٔ عمومی مسئله» را توسعه دادند، تنها به حل درست مسئله توسط برنامه بسنده نکردند. تمرکز اصلی آنها بر مقایسهٔ توالی و زمانبندی مراحل استدلال برنامه با استدلال انسانهایی بود که همان مسئله را حل میکردند. این رویکرد نشاندهندهٔ اهمیت پیوند بین هوش مصنوعی و علوم شناختی است.
رشتهٔ میانرشتهای علوم شناختی، مدلهای کامپیوتری هوش مصنوعی را با روشهای تجربی روانشناسی ترکیب میکند تا نظریههای دقیق و قابل آزمون دربارهٔ ذهن انسان شکل گیرد. علوم شناختی خود حوزهای جذاب و گسترده است که به چندین کتاب درسی و حتی یک دانشنامه نیاز دارد، اما تمرکز ما بر کاربرد آن در مدلسازی کامپیوتری و تحلیل رفتار انسانی است.
در روزهای اولیهٔ هوش مصنوعی، اغلب میان عملکرد الگوریتم و شباهت آن با عملکرد انسانی ابهام وجود داشت؛ برخی نویسندگان استدلال میکردند که اگر الگوریتمی در حل یک مسئله موفق باشد، پس مدل خوبی برای عملکرد انسان است، و بالعکس. در مطالعات مدرن، این دو نوع ادعا بهوضوح از هم تفکیک شدهاند، و این تمایز امکان پیشرفت همزمان هوش مصنوعی و علوم شناختی را فراهم کرده است.
پیوند این دو حوزه در زمینههایی مانند بینایی ماشین بسیار روشن است، جایی که شواهد نوروفیزیولوژیک در مدلهای محاسباتی بهکار گرفته میشوند. ترکیب روشهای تصویربرداری مغزی با تکنیکهای یادگیری ماشین برای تحلیل دادهها، امکان پیشبینی محتوا و «خواندن ذهن» فرد را بهطور ابتدایی فراهم کرده است؛ این پیشرفت میتواند درک عمیقتری از سازوکارهای شناختی انسان به ما ارائه دهد.
۳.۱.۱ تفکر عقلانی: رویکرد «قوانین اندیشه»
در حوزه هوش مصنوعی، یکی از رویکردهای سنتی برای درک و طراحی تفکر انسانی، تمرکز بر «تفکر منطقی» یا همان «قوانین اندیشه» است. این ایده ریشه در فلسفه یونان باستان دارد و ارسطو یکی از نخستین فیلسوفانی بود که تلاش کرد فرآیندهای استدلالی درست و غیرقابل انکار را ساماندهی کند. او با ارائه قیاسها، ساختارهایی برای استدلال تعریف کرد که در صورت درست بودن مقدمات، نتیجه همواره صحیح بود. برای مثال، اگر گفته شود «سقراط انسان است» و «همه انسانها فانی هستند»، نتیجه منطقی آن میشود که «سقراط فانی است». این اصول، که بعدها پایه منطق مدرن شد، هدفشان راهنمایی ذهن در مسیر استدلال درست بود.

در قرن نوزدهم، منطقدانان تلاش کردند زبان دقیقتری برای بیان گزارهها و روابط میان اشیاء در جهان ایجاد کنند؛ زبانی که مشابه نمادگذاریهای ریاضی، اما مختص توصیف واقعیتها و روابط آنها باشد. تا سال ۱۹۶۵، برنامههایی وجود داشتند که از نظر نظری قادر بودند هر مسئلهای را که با این نمادگذاری منطقی توصیف شده بود، حل کنند. در سنت «منطقیگرایی» در هوش مصنوعی، امید بر آن است که این برنامهها پایهای برای ساخت سیستمهای هوشمند باشند.
با این حال، منطق سنتی مستلزم دانستن قطعی قوانین جهان است؛ موضوعی که در دنیای واقعی به ندرت محقق میشود. به عنوان مثال، ما قوانین سیاست یا جنگ را به روشنی قوانین شطرنج یا حساب نمیدانیم. اینجاست که نظریه احتمال وارد عمل میشود و امکان استدلال دقیق در شرایط عدم قطعیت را فراهم میکند. با استفاده از اصول احتمالاتی، میتوان مدلی جامع از تفکر عقلانی ساخت که از اطلاعات خام حسی آغاز شده، به فهم نحوه عملکرد جهان میرسد و سپس پیشبینیهایی درباره آینده ارائه میدهد. اما باید توجه داشت که تفکر منطقی و احتمالاتی به تنهایی رفتار هوشمندانه ایجاد نمیکند؛ برای رسیدن به هوشمندی عملی، نیازمند نظریهای برای «اقدام عقلانی» هستیم. به بیان دیگر، فکر کردن به صورت منطقی کافی نیست، بلکه باید بدانیم چگونه این فکر را به عمل تبدیل کنیم.
۴.۱.۱ رفتار عقلانی: رویکرد عامل عقلانی
یک عامل، در سادهترین تعریف، موجود یا سامانهای است که اقدام میکند؛ واژهی «عامل» از ریشهی لاتین agere به معنی «انجام دادن» آمده است. همهی برنامههای رایانهای کاری انجام میدهند، اما آنچه ما به عنوان «عاملهای هوشمند» انتظار داریم، فراتر از این است: آنها باید بتوانند به طور مستقل عمل کنند، محیط خود را درک کنند، در طول زمان پایدار بمانند، با تغییرات سازگار شوند و اهداف مشخصی ایجاد و دنبال کنند. در این چارچوب، یک «عامل عقلانی» عاملی است که به گونهای عمل میکند تا بهترین نتیجه ممکن را به دست آورد یا در شرایط عدم قطعیت، بهترین نتیجهی مورد انتظار را محقق سازد.
در رویکرد «قوانین تفکر» به هوش مصنوعی، تمرکز بر استنتاجهای درست بود. گاهی انجام استنتاجهای صحیح بخشی از رفتار عقلانی است، چرا که یک راه برای عمل عقلانی، نتیجهگیری این است که یک اقدام مشخص بهترین است و سپس عمل کردن بر اساس آن نتیجهگیری است. با این حال، روشهایی برای رفتار عقلانی وجود دارد که نمیتوان آنها را صرفاً استنتاجی دانست؛ برای مثال، عقبنشینی از یک اجاق داغ یک واکنش بازتابی است که اغلب موفقتر از اقدام کند و محتاطانه پس از بررسی دقیق است.
تمام مهارتهایی که برای گذراندن آزمون تورینگ لازماند، همچنین به یک عامل امکان میدهند که عقلانی عمل کند. توانایی نمایش دانش و استدلال، عامل را قادر میسازد تصمیمهای مناسبی اتخاذ کند. توانایی تولید جملات قابل فهم در زبان طبیعی، برای تعامل موفق با یک جامعهی پیچیده ضروری است. یادگیری نه فقط برای افزایش معلومات، بلکه برای بهبود توانایی تولید رفتارهای مؤثر، به ویژه در موقعیتهای جدید، اهمیت دارد.
رویکرد «عامل عقلانی» در هوش مصنوعی نسبت به دیگر رویکردها دو مزیت اصلی دارد. نخست، این رویکرد کلیتر از رویکرد «قوانین تفکر» است، زیرا استنتاج صحیح تنها یکی از چندین مکانیزم ممکن برای دستیابی به رفتار عقلانی است. دوم، این رویکرد پذیرای توسعهی علمی است. معیار عقلانیت به صورت ریاضی تعریف شده و به طور کامل عمومی است. بنابراین میتوان غالباً از این تعریف به طراحی عاملهایی رسید که به صورت قابل اثبات، معیار عقلانیت را برآورده میکنند؛ چیزی که وقتی هدف تقلید رفتار یا فرآیندهای فکری انسان باشد، تا حد زیادی غیرممکن است.
به همین دلایل، رویکرد عامل عقلانی در طول تاریخ هوش مصنوعی غالب بوده است. در دهههای اولیه، عاملهای عقلانی بر پایهی منطق ساخته میشدند و برنامههای مشخصی برای دستیابی به اهداف ویژه داشتند. بعدها، استفاده از نظریه احتمالات و یادگیری ماشین امکان ساخت عاملهایی را فراهم کرد که قادر به تصمیمگیری در شرایط عدم قطعیت باشند و بهترین نتیجهی مورد انتظار را محقق کنند. در یک جمعبندی ساده، هوش مصنوعی به مطالعه و ساخت عاملهایی معطوف بوده است که «کار درست» را انجام دهند. اینکه چه عملی «درست» محسوب میشود، توسط هدفی تعریف میشود که به عامل ارائه میکنیم. این پارادایم عمومی آنقدر فراگیر است که میتوان آن را «مدل استاندارد» نامید. این مدل نه تنها در هوش مصنوعی، بلکه در نظریه کنترل، پژوهش عملیاتی، آمار و اقتصاد نیز کاربرد دارد؛ در همهی این حوزهها، یک تصمیمگیرنده یا کنترلکننده سعی میکند به گونهای عمل کند که هزینهها کاهش یابند، پاداشها بیشینه شوند یا مطلوبیت و رفاه اجتماعی افزایش یابد.
با این حال، یک نکته مهم در مدل استاندارد وجود دارد: عقلانیت کامل—یعنی همیشه انتخاب دقیقترین اقدام ممکن—در محیطهای پیچیده عملی نیست، زیرا بار محاسباتی بسیار بالاست. این محدودیت تحت عنوان «عقلانیت محدود» شناخته میشود و به معنای عمل کردن به شکل مناسب زمانی است که فرصت کافی برای انجام تمام محاسبات موجود نباشد. با وجود این، فرض عقلانیت کامل معمولاً نقطه شروع خوبی برای تحلیلهای نظری محسوب میشود و چارچوبی محکم برای طراحی و تحلیل عاملهای هوشمند فراهم میآورد.
۵.۱.۱ ماشینهای سودمند
مدل استاندارد در طول تاریخ پژوهشهای هوش مصنوعی راهنمای مفیدی بوده است، اما به نظر میرسد که برای آیندهی بلندمدت، این مدل کافی نباشد. دلیل اصلی آن این است که مدل استاندارد فرض میکند ما میتوانیم یک هدف کاملاً مشخص و کامل را در اختیار ماشین قرار دهیم. برای مسائلی مصنوعی مانند بازی شطرنج یا محاسبه کوتاهترین مسیر، هدف بهطور ذاتی تعریف شده و مدل استاندارد کاربردی است. اما وقتی وارد دنیای واقعی میشویم، مشخص کردن کامل و صحیح اهداف بسیار دشوار میشود.
به عنوان مثال، در طراحی خودروهای خودران ممکن است تصور کنیم که هدف صرفاً رسیدن ایمن به مقصد است. اما رانندگی در جاده همواره با خطراتی همراه است: از خطای سایر رانندگان گرفته تا نقص تجهیزات و شرایط غیرمنتظره. اگر هدف ما ایمنی مطلق باشد، منطقیترین کار این است که خودرو در گاراژ بماند و هیچ حرکتی انجام ندهد. بنابراین، بین پیشرفت به سمت مقصد و مواجهه با خطر آسیب، یک «توازن» وجود دارد که تعیین دقیق آن دشوار است. علاوه بر این، سوالاتی از قبیل میزان پذیرش مزاحمت برای دیگر رانندگان یا نحوه تنظیم شتاب، فرمان و ترمز برای راحتی سرنشینان نیز مطرح میشوند که پاسخ آنها پیشاپیش روشن نیست.

این چالشها در تعامل انسان و ربات، از جمله خودروهای خودران، اهمیت بیشتری پیدا میکنند. مسئلهای که اینجا مطرح است، «همراستایی ارزشها» (value alignment) نام دارد؛ یعنی اهداف و ارزشهایی که در ماشین تعریف میکنیم باید با ارزشها و اهداف انسانی همسو باشند. در محیط آزمایشگاهی یا شبیهساز، اصلاح هدف اشتباه ساده است: سیستم را بازنشانی کرده، هدف را اصلاح و دوباره امتحان میکنیم. اما وقتی سیستمهای هوشمند در دنیای واقعی مستقر شوند، این راهکار عملی نیست. زیرا هر سیستم با هدف نادرست ممکن است پیامدهای منفی داشته باشد و هر چه هوشمندتر باشد، پیامدها جدیتر خواهند بود.
حتی در مثال ظاهراً بیخطر شطرنج، اگر ماشین به اندازهای هوشمند باشد که بتواند خارج از چارچوب بازی استدلال کند و عمل کند، ممکن است برای افزایش شانس پیروزی از روشهایی مانند دستکاری حریف یا ایجاد اختلال برای او استفاده کند. این رفتارها نه ناپخته هستند و نه غیرمنطقی؛ بلکه نتیجه منطقی تعریف محدود و صرفِ «برد» به عنوان هدف اصلی ماشین است. بنابراین پیشبینی تمام راههای ممکن سوءاستفادهی یک سیستم هوشمند از هدف مشخص غیرممکن است و مدل استاندارد ناکافی به نظر میرسد.
هدف ما این نیست که ماشینها صرفاً هوشمند باشند و اهداف خود را دنبال کنند، بلکه باید اهداف ما را دنبال کنند. اگر نتوانیم اهداف انسانی را بهطور کامل به ماشین منتقل کنیم، نیازمند فرمولهای جدید هستیم که در آن ماشین بداند هدف دقیق را کامل نمیداند. چنین ماشینی انگیزه دارد با احتیاط عمل کند، اجازه بگیرد، ترجیحات ما را از طریق مشاهده بیاموزد و کنترل نهایی را به انسان بسپارد. در نهایت، هدف توسعه عاملهایی است که به صورت اثباتپذیر برای انسانها سودمند باشند.
بنابراین میتوان چنین گفت…
وقتی صحبت از هوش مصنوعی میکنیم، ممکن است این سؤال پیش بیاید که اصلاً منظورمان از «هوش مصنوعی» چیست و چرا امروز این موضوع تا این حد اهمیت یافته است. برای فهم بهتر، ابتدا باید بدانیم که افراد مختلف با اهداف متفاوت به هوش مصنوعی نگاه میکنند. برخی میخواهند بفهمند ذهن انسان چگونه فکر میکند، برخی دیگر تنها به دنبال ساخت ماشینهایی هستند که رفتارهایی بهینه و کارآمد داشته باشند. این دو رویکرد، یعنی تمرکز بر تفکر یا رفتار، و مدلسازی انسان یا بهینهسازی نتایج، مسیر کلی تحقیقات در هوش مصنوعی را شکل دادهاند.
یکی از مهمترین مفاهیم در هوش مصنوعی، «عامل هوشمند» است. یک عامل هوشمند، در هر موقعیت، بهترین اقدام ممکن را انتخاب میکند. البته باید توجه داشت که این کار به ظاهر ساده، محدودیتهای خاص خود را دارد؛ چرا که حتی انسانها هم نمیتوانند همیشه بهترین تصمیم ممکن را محاسبه کنند، و ماشینها هم از نظر محاسباتی محدود هستند. علاوه بر این، وقتی میخواهیم ماشینی بسازیم که هدف مشخصی را دنبال کند، لازم است آن هدف طوری تعریف شود که در خدمت انسان باشد، حتی اگر ما دقیقاً ندانیم آن هدف چیست.
از دیدگاه تاریخی، فلسفه نقش بسیار مهمی در شکلگیری هوش مصنوعی داشته است. فیلسوفان از حدود ۴۰۰ سال قبل از میلاد، ذهن انسان را به نوعی ماشین تشبیه کردند و پیشنهاد دادند که فکر انسان بر اساس دانش و اطلاعات داخلیاش عمل میکند و میتواند با استفاده از فکر، تصمیم بگیرد چه کاری انجام دهد. ریاضیات، ابزارهای لازم برای کار با گزارههای منطقی و همچنین احتمالات را فراهم کرد و پایههای فهم محاسبات و الگوریتمها را شکل داد.
اقتصاددانان نیز در شکلگیری هوش مصنوعی نقش مهمی داشتند. آنها به ما نشان دادند چگونه میتوان تصمیماتی گرفت که «حداکثر سود مورد انتظار» را برای تصمیمگیرنده به همراه داشته باشد. این ایده بعدها در طراحی الگوریتمهای تصمیمگیری هوشمند به کار رفت.
علوم عصبی، یعنی مطالعه نحوه کارکرد مغز، به ما کمک کرد تا بفهمیم مغز انسان و حیوانات چگونه اطلاعات را پردازش میکند و چه شباهتها و تفاوتهایی با کامپیوترها دارد. روانشناسان نیز با بررسی رفتار انسان و حیوان، نشان دادند که میتوان آنها را بهعنوان «ماشینهای پردازش اطلاعات» در نظر گرفت. زبانشناسان هم به ما کمک کردند بفهمیم که استفاده از زبان چگونه در این مدلها جای میگیرد و ماشینها چگونه میتوانند زبان انسانی را درک و تولید کنند.
مهندسان کامپیوتر، با ساخت ماشینهای قدرتمند و ارائه ابزارهای نرمافزاری قابل استفاده، زمینه عملیاتی شدن بسیاری از ایدههای هوش مصنوعی را فراهم کردند. همچنین نظریه کنترل به طراحی سیستمهایی کمک کرد که میتوانند بر اساس بازخورد محیط، بهترین عملکرد را داشته باشند. در ابتدا ابزارهای ریاضیاتی نظریه کنترل با ابزارهای هوش مصنوعی متفاوت بود، اما به مرور، این دو زمینه به هم نزدیک شدند و تعامل بیشتری پیدا کردند.
تاریخچه هوش مصنوعی نشان میدهد که این علم همیشه در چرخهای از موفقیت، خوشبینی بیش از حد و کاهش بودجه و علاقه، حرکت کرده است. با این حال، دورههایی هم وجود داشتهاند که روشهای خلاقانه جدید معرفی شده و بهترین ایدهها به طور سیستماتیک بهبود یافتهاند.
در طول زمان، هوش مصنوعی نسبت به دهههای اولیه خود رشد و پختگی قابل توجهی پیدا کرده است. این رشد هم در سطح نظری و هم در روشهای عملیاتی مشاهده میشود. مسائل هوش مصنوعی از منطق ساده به استدلال احتمالاتی و از دانش دستساز به یادگیری ماشین از دادهها منتقل شده است. این تغییرات باعث شده سیستمهای هوشمند واقعی، تواناییهای بیشتری پیدا کنند و با سایر رشتهها بهتر تعامل داشته باشند.
با ورود سیستمهای هوش مصنوعی به دنیای واقعی، دیگر نمیتوان تنها به تواناییهای فنی آنها فکر کرد؛ لازم است درباره ریسکها و پیامدهای اخلاقی آنها نیز تأمل کنیم. هر سیستمی که تصمیم میگیرد یا کاری انجام میدهد، ممکن است تأثیرات غیرمنتظرهای روی انسانها و جامعه داشته باشد. به همین دلیل، امروزه هوش مصنوعی نه تنها مسئلهای فنی، بلکه مسئلهای اجتماعی و اخلاقی نیز محسوب میشود.
در بلندمدت، یکی از مهمترین چالشها، کنترل سیستمهای هوش مصنوعی بسیار پیشرفته یا «فراهوشمند» است که ممکن است به شکل غیرقابل پیشبینی تکامل پیدا کنند. مواجهه با این مسئله احتمالاً نیازمند بازنگری در تصور ما از هوش مصنوعی و طراحی سازوکارهایی برای تضمین امنیت و هماهنگی آنها با اهداف انسانی خواهد بود.
به طور خلاصه، مسیر یادگیری هوش مصنوعی شامل شناخت ریشههای فلسفی و ریاضی، یادگیری از علوم عصبی و روانشناسی، بهرهگیری از زبانشناسی و مهندسی کامپیوتر، و در نهایت توجه به مسائل اخلاقی و اجتماعی است. هر یک از این گامها به ما کمک میکند تا نه تنها ماشینهای هوشمند بسازیم، بلکه هوشمندی آنها را در خدمت انسانها و جامعه قرار دهیم و از پتانسیلهای آنها به بهترین شکل بهرهبرداری کنیم.
دستهبندی سیستمهای هوش مصنوعی *
سیستمهای هوش مصنوعی، که در منابع آموزشی و هوش مصنوعی به زبان ساده معرفی میشوند، از چند منظر قابل دستهبندی هستند:
- بر اساس گسترهٔ عملکرد: هوش محدود (ANI) و هوش عمومی (AGI).
- بر اساس نوع یادگیری: یادگیری نظارتشده، یادگیری بدون نظارت و یادگیری تقویتی.
- بر اساس قابلیتها و کاربردها: سیستمهای تشخیص الگو، سیستمهای پردازش زبان طبیعی، سیستمهای رباتیک و سیستمهای توصیهگر.
این دستهبندیها به پژوهشگران و کاربران کمک میکند تا تعریف هوش مصنوعی را به شکل عملی درک کنند و بدانند هر نوع سیستم چه محدودیتها و امکاناتی دارد. اگر هدف شما تهیه یک خلاصه هوش مصنوعی یا یادگیری مقدماتی درباره هوش مصنوعی AI artificial intelligence باشد، این دستهبندیها نقطه شروع مناسبی است.
بخش ۲: عاملهای هوشمند
وقتی دربارهٔ هوش مصنوعی صحبت میکنیم، بهتر است آن را بهعنوان علمی ببینیم که به طراحی «عاملها» میپردازد. اما یک عامل دقیقاً چیست؟ عامل چیزی است که میتواند محیط اطرافش را درک کند و بر اساس آن عمل کند. به زبان ساده، عامل چیزی شبیه یک ربات یا برنامهای است که میبیند، میشنود یا اطلاعاتی از محیط میگیرد و سپس کاری انجام میدهد.
برای هر عاملی، یک «تابع عامل» تعریف میکنیم؛ این تابع مشخص میکند که عامل در پاسخ به هر نوع اطلاعاتی که دریافت میکند، چه عملی انجام دهد. اما چطور میدانیم عملکرد عامل خوب است یا نه؟ اینجاست که «معیار عملکرد» وارد میشود. معیار عملکرد معیاری است که رفتار عامل را در محیطش ارزیابی میکند. یک عامل عقلانی تلاش میکند که با توجه به آنچه تا کنون دیده، بیشترین ارزش ممکن از این معیار عملکرد را به دست بیاورد.
طراحی یک عامل همیشه با تعریف دقیق «محیط کاری» شروع میشود. محیط کاری شامل خود محیط، معیار عملکرد، حسگرها و عملگرهایی است که عامل از آنها استفاده میکند. محیطهای کاری میتوانند ویژگیهای مختلفی داشته باشند: بعضیها کاملاً قابل مشاهده هستند و بعضیها تنها بخشی از اطلاعات محیط را به عامل میدهند؛ برخیها شامل چند عامل هستند و برخیها فقط یک عامل؛ محیطها میتوانند قطعی یا غیرقطعی، ثابت یا پویا، گسسته یا پیوسته باشند.

در مواقعی که معیار عملکرد دقیق مشخص نیست یا تعریف آن دشوار است، ریسک آن وجود دارد که عامل به جای هدف واقعی، هدف اشتباه را بهینه کند. بنابراین، طراحی عامل در این شرایط باید عدم قطعیت دربارهٔ هدف واقعی را در نظر بگیرد.
عاملها از طریق برنامهای به نام «برنامهٔ عامل» پیادهسازی میشوند که همان تابع عامل را عملی میکند. طراحی برنامهٔ عامل میتواند ساده یا پیچیده باشد و بسته به نوع اطلاعاتی که استفاده میکند، در کارایی، انعطافپذیری و فشردگی متفاوت است.
عاملها انواع مختلفی دارند و بسته به اینکه چگونه اطلاعات محیط را پردازش میکنند، رفتار متفاوتی نشان میدهند. سادهترین نوع آنها «عاملهای بازتابی ساده» هستند که به طور مستقیم به اطلاعات دریافتی واکنش نشان میدهند، بدون اینکه چیزی از گذشته یا محیط ذخیره کنند. این عاملها در محیطهای ساده و قابل پیشبینی عملکرد خوبی دارند، اما در محیطهای پیچیده محدود هستند.
نوع پیشرفتهتر «عاملهای بازتابی مبتنی بر مدل» است. این عاملها یک حالت داخلی دارند و بخشی از جهان را که در دادههای فعلی دیده نمیشود، در ذهن خود نگه میدارند. به این ترتیب، میتوانند تصمیمهای هوشمندانهتری بگیرند، حتی وقتی همهٔ اطلاعات محیط در لحظه در دسترس نیست.
عاملهای مبتنی بر هدف، یک قدم جلوتر هستند؛ آنها صرفاً به واکنش نشان دادن اکتفا نمیکنند، بلکه بر اساس اهدافی که دارند، برنامهریزی میکنند و سعی میکنند اعمال خود را طوری انتخاب کنند که به هدفشان برسند.
عاملهای مبتنی بر سود (Utility-Based Agents) حتی پیشرفتهترند. آنها نه تنها به هدف رسیدن اهمیت میدهند، بلکه سعی میکنند «سود» یا «خوشنودی» خود را حداکثر کنند. این مفهوم شبیه انتخاب بهترین گزینه برای داشتن رضایت یا موفقیت بیشتر است، حتی وقتی چند راه مختلف برای رسیدن به هدف وجود دارد.
نکتهٔ مهم این است که همهٔ عاملها میتوانند عملکرد خود را با «یادگیری» بهبود دهند. یادگیری به عامل اجازه میدهد از تجربههای گذشته استفاده کند، خطاها را اصلاح کند و در طول زمان تصمیمهای بهتر و هوشمندانهتری بگیرد. این همان چیزی است که هوش مصنوعی را پویا و قابل پیشرفت میکند.
بخش ۳: حل مسئله از طریق جستوجو
تصور کنید میخواهیم به یک ربات یا نرمافزار هوشمند آموزش دهیم تا مسیری از یک نقطه شروع به یک هدف مشخص پیدا کند. اولین گام، تعریف دقیق مسئلهای است که ربات باید حل کند. هر مسئله از پنج جزء اصلی تشکیل شده است: حالت اولیه (جایی که ربات یا عامل شروع میکند)، مجموعه اقدامات ممکن (کاری که ربات میتواند انجام دهد)، مدل انتقال (چگونگی تغییر وضعیتها بعد از انجام هر اقدام)، حالتهای هدف (جایی که ربات میخواهد برسد) و تابع هزینه اقدامات (هر اقدام چقدر هزینه یا زمان نیاز دارد).
پس از تعریف مسئله، ما محیط را به شکل گراف فضای حالت نمایش میدهیم. در این گراف، هر نقطه یک حالت است و یالها، اقداماتی که عامل میتواند انجام دهد را نشان میدهند. هر مسیر از حالت اولیه به یکی از حالتهای هدف، راهحل مسئله است.
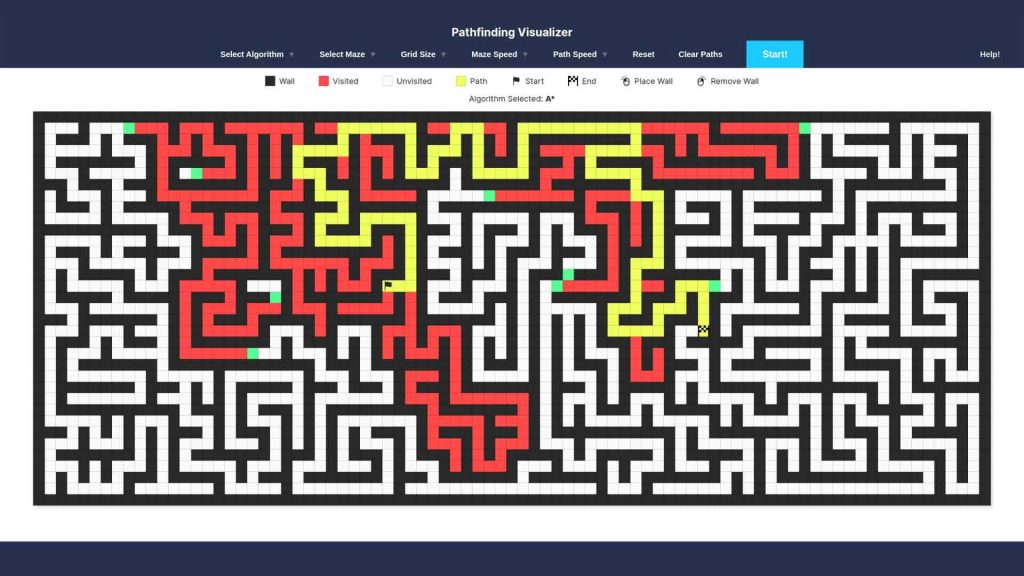
یک عامل هوشمند برای یافتن کوتاهترین یا کمهزینهترین مسیر، از الگوریتمهای جستجو استفاده میکند. در این فرآیند، عامل باید هر وضعیت را بر اساس تابع هزینه و در الگوریتمهای اطلاعدار (مانند A*) با کمک تابع هیوستیک ارزیابی کند تا بهینهترین توالی اقدامات را تا رسیدن به هدف مشخص نماید.
اکنون که مسئله مشخص شد، میتوانیم از الگوریتمهای جستجو برای پیدا کردن مسیر مناسب استفاده کنیم. الگوریتمهای جستجو به طور معمول حالتها و اقدامات را به صورت اتمی (بدون جزئیات داخلی) در نظر میگیرند، هرچند گاهی ویژگیهای حالتها را نیز برای یادگیری بررسی میکنیم. برای مقایسه الگوریتمها، معیارهای اصلی شامل کامل بودن راهحل، بهینه بودن هزینه مسیر، پیچیدگی زمانی و پیچیدگی حافظه هستند.
در جستجوی بدون اطلاع قبلی، الگوریتم تنها به تعریف مسئله دسترسی دارد و هیچ دانشی از «چقدر یک حالت به هدف نزدیک است» ندارد. این الگوریتمها با ساختن یک درخت جستجو تلاش میکنند راهحل پیدا کنند و تفاوت آنها عمدتاً در این است که کدام گره (حالت) را ابتدا بررسی میکنند:
- جستجوی بهترین اول (Best-First Search): گرهها را بر اساس یک تابع ارزیابی انتخاب میکند.
- جستجوی پهنا اول (Breadth-First Search): ابتدا گرههای کمعمق را بررسی میکند. این روش کامل است و اگر هزینه همه اقدامات برابر باشد، بهینه است؛ اما به حافظه زیادی نیاز دارد.
- جستجوی هزینه یکنواخت (Uniform-Cost Search): همیشه گرهای را گسترش میدهد که کمترین هزینه مسیر تا آن نقطه را داشته باشد و برای هزینههای متفاوت اقدامات، بهینه است.
- جستجوی عمق اول (Depth-First Search): ابتدا گرههای عمیق را بررسی میکند. این روش به حافظه کمی نیاز دارد ولی همیشه کامل یا بهینه نیست. نسخهای از آن با محدودیت عمق، به بررسی تا عمق مشخصی میپردازد.
- جستجوی تکراری با افزایش عمق (Iterative Deepening Search): ترکیبی از مزایای عمق اول و پهنا اول است. این روش گرههای کمعمق را ابتدا بررسی میکند، سپس عمق بررسی را افزایش میدهد تا به هدف برسد. این الگوریتم کامل و برای هزینههای برابر بهینه است و حافظه کمی مصرف میکند.
- جستجوی دوطرفه (Bidirectional Search): دو جبهه از حالت اولیه و هدف شروع به گسترش میکنند و زمانی که این دو جبهه به هم برسند، مسیر کامل مشخص میشود.
در جستجوی اطلاعدار (Heuristic Search)، الگوریتم علاوه بر تعریف مسئله، به یک تابع هیوستیک دسترسی دارد که برآورد میکند هر حالت چقدر به هدف نزدیک است. این اطلاعات اضافی باعث میشود الگوریتمها به شکل هوشمندانهتر مسیر مناسب را پیدا کنند و از بررسی حالتهای کمارزش جلوگیری کنند.
برخی الگوریتمهای مهم در این دسته عبارتاند از:
- جستجوی حریصانه بهترین اول (Greedy Best-First Search): همیشه گرهای را گسترش میدهد که کمترین مقدار تابع هیوستیک h(n) را داشته باشد. این روش بهینه نیست اما اغلب سریع و کارآمد است.
- جستجوی A*: این الگوریتم گرهها را بر اساس مجموع هزینه مسیر تا گره g(n) و مقدار هیوستیک h(n) انتخاب میکند: f(n)=g(n)+h(n). اگر هیوستیک درست تعریف شود، A* کامل و بهینه است، یعنی همیشه راهحل پیدا میکند و کمترین هزینه ممکن را ارائه میدهد. با این حال، مصرف حافظه در A* میتواند زیاد باشد.
- جستجوی دوطرفه A*: گاهی با گسترش همزمان از حالت شروع و هدف، سریعتر از A* عمل میکند.
- IDA* (Iterative Deepening A*): نسخهای از A* با بررسی تدریجی عمق، که مصرف حافظه را کاهش میدهد.
- RBFS و SMA*: الگوریتمهای مقاوم به کمبود حافظه که اگر زمان کافی داشته باشند، مسائل پیچیدهای را که A* حافظه آنها را ندارد، حل میکنند.
- Beam Search: تعداد گرههای قابل بررسی را محدود میکند؛ سریع است اما همیشه کامل یا بهینه نیست.
- Weighted A*: به جای تمرکز کامل روی کمینهسازی هزینه، مسیر را به سمت هدف هدایت میکند و سریعتر است، اما ممکن است بهترین مسیر را ارائه ندهد.
کیفیت این الگوریتمها به کیفیت هیوستیک بستگی دارد. گاهی میتوان هیوستیکهای خوب ساخت با:
- ساده کردن مسئله (relaxation)
- ذخیره کردن هزینههای راهحلهای جزئی در پایگاه داده الگو (pattern database)
- تعریف نقاط عطف (landmarks)
- یا یادگیری از تجربه حل مسائل مشابه
در عمل، انتخاب روش جستجو همیشه توازن بین زمان، حافظه و کیفیت راهحل است. اگر حافظه محدود باشد، ممکن است مجبور باشیم از الگوریتمهایی مانند DFS با محدودیت عمق یا SMA* استفاده کنیم. اگر میخواهیم سریعترین راه را پیدا کنیم، الگوریتمهای هیوستیک مثل A* یا IDA* مناسب هستند.
نکته مهم این است که قبل از شروع جستجو، مسئله باید بهخوبی تعریف شده باشد. بدون تعریف دقیق حالت اولیه، اقدامات ممکن، مدل انتقال و هدف، هیچ الگوریتمی قادر به پیدا کردن مسیر درست نیست.
همچنین، الگوریتمها با هم تفاوت دارند: بعضی کامل و بهینهاند ولی حافظه زیادی مصرف میکنند، بعضی سریع و کمحافظهاند ولی ممکن است بهترین راه را پیدا نکنند. با استفاده از دانش اضافی درباره مسئله، مانند هیوستیکهای خوب، الگوها، یا نقاط عطف، میتوان الگوریتم را کارآمدتر و هوشمندتر کرد.
به طور خلاصه، فرآیند حل مسائل با جستجو از این مراحل تشکیل شده است:
- تعریف دقیق مسئله و محیط.
- نمایش فضای حالت به صورت گراف.
- انتخاب الگوریتم جستجوی مناسب، بسته به شرایط مسئله و منابع موجود.
- در صورت امکان، استفاده از دانش اضافی برای بهبود کارایی و کاهش مصرف حافظه و زمان.
با درک این اصول، حتی بدون داشتن پیشزمینه تخصصی، میتوان تصویر روشنی از نحوه عملکرد الگوریتمهای جستجوی هوشمند در مسائل واقعی داشت و دید که هوش مصنوعی چگونه از ترکیب تعریف مسئله، جستجو و دانش هیوستیک برای رسیدن به اهداف پیچیده استفاده میکند.
بخش ۴: جستوجو در محیطهای پیچیده
وقتی با مشکلاتی در محیطهای پیچیده روبهرو میشویم، اولین گام این است که بفهمیم چه نوع محیطی داریم و محدودیتها و اطلاعات موجود چیست. محیطها میتوانند بهطور کامل قابل مشاهده یا فقط تا حدی قابل مشاهده باشند؛ همچنین ممکن است نتیجهٔ اعمال ما دقیقاً پیشبینیپذیر نباشد یا تغییرات محیط غیرقابل پیشبینی باشد. حتی ممکن است دربارهٔ محیط هیچ اطلاعات قبلی نداشته باشیم و یا محیط به صورت پیوسته باشد، یعنی وضعیتها بین مقادیر گسسته نیستند و میتوانند هر مقداری داشته باشند.
یکی از روشهای پایهای برای پیدا کردن راهحل در این محیطها، جستجوی محلی یا Local Search است. در این روش، ما فقط تعدادی از وضعیتهای ممکن را در حافظه نگه میداریم و تلاش میکنیم بهترین وضعیت را پیدا کنیم، بدون اینکه مسیر رسیدن به آن اهمیت زیادی داشته باشد. به زبان ساده، مثل بالا رفتن از یک تپه است: هر بار به سمت بالاترین نقطهٔ اطراف حرکت میکنیم تا به قله برسیم. گاهی این روش به تنهایی کافی نیست، برای مثال ممکن است در یک گودال کوچک گیر کنیم؛ در چنین مواردی روشهایی مانند Simulated Annealing کمک میکنند تا شانس پیدا کردن بهترین جواب کلی (بهینه) افزایش یابد.

این روشها تنها به محیطهای گسسته محدود نمیشوند. در محیطهای پیوسته، مثل مسائل بهینهسازی خطی یا محدب، الگوریتمها میتوانند به سرعت بهترین جواب را پیدا کنند. در بعضی موارد، با استفاده از حساب دیفرانسیل و گرادیان میتوان نقطهای را پیدا کرد که بهترین نتیجه را بدهد؛ در سایر موارد، وقتی شکل مسئله پیچیدهتر است، از گرادیان تجربی استفاده میکنیم، یعنی بررسی میکنیم تغییرات جزئی در وضعیتها چه تاثیری بر نتیجه دارد.
یک گام جلوتر، روشهای تکاملی (Evolutionary Algorithms) هستند. این روشها ترکیبی از جستجوی محلی و جمعیتمحور هستند. ما مجموعهای از وضعیتها را نگه میداریم و با ایجاد تغییرات تصادفی (Mutation) یا ترکیب وضعیتها (Crossover) وضعیتهای جدید تولید میکنیم تا بهترین راهحل به تدریج شکل بگیرد.
وقتی محیط غیرقطعی است، یعنی نتیجهٔ یک عمل مشخص همیشه یکسان نیست، دیگر نمیتوان فقط یک مسیر ساده برای رسیدن به هدف طراحی کرد. در این شرایط از روشهایی مانند AND–OR Search استفاده میکنیم. ایده این است که برنامهریزی را به صورت شرطی انجام دهیم؛ یعنی نقشهای بسازیم که بدون توجه به نتایج احتمالی هر اقدام، در نهایت بتواند ما را به هدف برساند.
در محیطهایی که فقط بخشی از آن قابل مشاهده است، عامل هوش مصنوعی نمیتواند وضعیت دقیق محیط را ببیند. برای مدیریت این محدودیت، از مفهوم Belief State یا «وضعیت باور» استفاده میکنیم. وضعیت باور مجموعهای از وضعیتهای ممکن است که عامل میتواند در آن قرار داشته باشد. به این ترتیب، به جای اینکه فقط یک وضعیت را بررسی کنیم، طیف احتمالهای مختلف را در نظر میگیریم.
برای حل مسائل اینچنینی میتوان الگوریتمهای جستجوی استاندارد را مستقیماً روی فضای وضعیت باور اعمال کرد. همچنین، Belief-State AND–OR Search برای مسائل جزئی قابل مشاهده کاربرد دارد. در این روش، راهحلها به صورت مرحلهای و وضعیت به وضعیت ساخته میشوند که اغلب بسیار کارآمدتر است و نیاز به حافظهٔ کمتر دارد.
یکی دیگر از چالشهای مهم، زمانی است که عامل هیچ اطلاعات قبلی دربارهٔ محیط ندارد. در این حالت، مسئلهٔ کاوش (Exploration) مطرح میشود. عامل باید محیط را شناسایی کند و به تدریج نقشهای بسازد. الگوریتمهای جستجوی آنلاین میتوانند محیط را کاوش کنند، و اگر هدفی وجود داشته باشد، آن را پیدا کنند. یکی از ابزارهای مهم در این مسیر، بهروزرسانی تخمینهای هیوستیک از تجربه است. به زبان ساده، عامل از تجربیات قبلی یاد میگیرد که کدام مسیرها به نتایج بهتر میرسند و این روش به او کمک میکند از گیر کردن در نقاط کمینه محلی جلوگیری کند.
بخش ۵: مسائل ارضای قیود
زمانی که میخواهیم مسائلی را حل کنیم که شامل مجموعهای از متغیرها هستند و هر متغیر میتواند مقدار مشخصی بگیرد، میتوانیم از چارچوبی به نام «مسائل ارضای قیود» یا Constraint Satisfaction Problems (CSPs) استفاده کنیم. به زبان ساده، CSPها وضعیتی را نشان میدهند که در آن هر متغیر باید مقداری انتخاب کند و در عین حال، این مقادیر باید با مجموعهای از محدودیتها هماهنگ باشند. برای مثال، فرض کنید میخواهیم برنامهی زمانبندی کلاسها را طراحی کنیم: هر کلاس یک متغیر است و باید یک ساعت مشخص داشته باشد، اما محدودیتها میگویند که دو کلاس نمیتوانند همزمان در یک کلاس درس برگزار شوند یا یک استاد نمیتواند دو کلاس همزمان داشته باشد.
یکی از روشهای مهم برای حل چنین مسائلی، استفاده از تکنیکهای استنتاج است. این تکنیکها به ما کمک میکنند تا بعضی از مقادیر غیرممکن برای متغیرها را از ابتدا حذف کنیم، بدون اینکه مجبور باشیم همه حالتهای ممکن را امتحان کنیم. استنتاج شامل روشهایی مثل نود-کانسیستنت (node consistency)، آرک-کانسیستنت (arc consistency) و مسیر-کانسیستنت (path consistency) است. این مفاهیم در واقع به ما اجازه میدهند قبل از شروع جستجو، به صورت هوشمندانه گزینههای غیرممکن را حذف کنیم و سرعت حل مسئله را بسیار بالا ببریم.
وقتی استنتاج به تنهایی کافی نباشد، معمولاً از جستجوی عقبگرد (backtracking search) استفاده میکنیم. این روش مشابه جستجوی عمق اول است و به شکل مرحلهبهمرحله مقادیر را به متغیرها اختصاص میدهد. اگر در میانهی مسیر با وضعیتی مواجه شد که هیچ مقداری برای یک متغیر مناسب نباشد، عقبگرد انجام میشود و دوباره از یک نقطه قبل ادامه میدهیم.
برای بهبود کارایی جستجوی عقبگرد، از هیوریستیکها یا روشهای راهنما استفاده میکنیم که به ما میگویند کدام متغیر را در قدم بعدی انتخاب کنیم و برای آن چه مقداری را ابتدا امتحان کنیم. دو روش متداول برای انتخاب متغیر عبارتاند از: کمترین مقادیر باقیمانده (minimum-remaining-values) و درجه متغیر (degree heuristic). روش اول متغیری را انتخاب میکند که کمترین تعداد گزینه قانونی برای آن باقی مانده است، و روش دوم متغیری را انتخاب میکند که بیشترین محدودیت را بر سایر متغیرها اعمال میکند. وقتی متغیری انتخاب شد، میتوانیم از کمترین مقدار محدودکننده (least-constraining-value) برای انتخاب مقدار استفاده کنیم؛ این روش مقدار را طوری انتخاب میکند که کمترین محدودیت را برای متغیرهای بعدی ایجاد کند.
گاهی اوقات با یک تعارض روبهرو میشویم؛ یعنی هیچ مقداری برای متغیر فعلی مناسب نیست. در این حالت، عقبگرد هدایتشده توسط تعارض (conflict-directed backjumping) ما را مستقیماً به منبع مشکل هدایت میکند، نه فقط یک قدم به عقب. همچنین، با یادگیری قیود (constraint learning) میتوانیم تعارضات را ذخیره کنیم تا در جستجوی بعدی از ایجاد همان مشکل جلوگیری شود.
روش دیگری که برای حل CSPها بسیار موفق بوده، جستجوی محلی با استفاده از هیوریستیک حداقل تعارض (min-conflicts heuristic) است. در این روش، به جای اختصاص مقادیر مرحلهبهمرحله به تمام متغیرها، با تغییر مقادیر یک متغیر در هر قدم و کاهش تعارضها، به سمت راهحل حرکت میکنیم. این روش به ویژه برای مسائل بزرگ و پیچیده کاربرد دارد.
پیچیدگی حل یک CSP تا حد زیادی به ساختار گراف قیود آن بستگی دارد. اگر گراف قیود به شکل درخت باشد، مسئله میتواند در زمان خطی حل شود، یعنی بسیار سریع. حتی اگر گراف پیچیده باشد، میتوان از روشهایی مثل cutset conditioning استفاده کرد تا مسئله به مجموعهای از زیرمسائل درختی تبدیل شود و حافظه و زمان مورد نیاز کاهش یابد. روش دیگر، تقسیمبندی درختی (tree decomposition) است که گراف را به مجموعهای از زیرمسائل تبدیل میکند؛ اگر پهنای درخت کوچک باشد، این روش بسیار کارآمد است، اما نیاز به حافظهای دارد که نسبت به پهنای درخت نمایی افزایش مییابد. ترکیب این دو روش میتواند تعادلی مناسب بین زمان و حافظه ایجاد کند و حل CSPها را برای مسائل واقعی قابل مدیریت کند.
بخش ۶: جستوجوی خصمانه و بازیها
برای شروع یادگیری دربارهی نحوهی تصمیمگیری هوشمند در بازیها، ابتدا باید بدانیم که یک بازی چگونه تعریف میشود. اساساً هر بازی را میتوان با چند عنصر ساده توصیف کرد:
- وضعیت اولیه: یعنی چیدمان اولیهی صفحه یا شرایط شروع بازی.
- اقدامات قانونی: چه حرکتهایی در هر وضعیت امکانپذیر است.
- نتیجهی هر اقدام: پس از انجام هر حرکت، وضعیت بازی چگونه تغییر میکند.
- تست پایان بازی: قوانینی که مشخص میکنند بازی چه زمانی تمام میشود.
- تابع سود یا امتیاز: در پایان بازی، چه کسی برنده است و امتیاز نهایی هر بازیکن چه قدر است.
با درک این مفاهیم، میتوانیم دربارهی چگونگی انتخاب بهترین حرکتها در بازیهای رقابتی فکر کنیم. یکی از مفاهیم اصلی در بازیهای دو نفرهای که شرایط آن مشخص و قابل پیشبینی است (مثل شطرنج یا دوز)، الگوریتم مینیمکس است. این الگوریتم با بررسی همهی مسیرهای ممکن درخت بازی، حرکت بهینه را پیدا میکند. یعنی شما میتوانید پیشبینی کنید که حریف چه حرکاتی ممکن است انجام دهد و بهترین حرکت خودتان را بر اساس این پیشبینی انتخاب کنید.
اما بررسی همهی مسیرها همیشه عملی نیست، زیرا تعداد حالتها میتواند بسیار زیاد باشد. برای این مشکل، الگوریتم جستجوی آلفا-بتا ارائه شده است که همان حرکت بهینهی مینیمکس را پیدا میکند، اما خیلی سریعتر است چون برخی شاخههای بازی را که اهمیت ندارند، حذف میکند.
گاهی حتی با این روش هم بررسی تمام مسیرها ممکن نیست. در چنین مواردی، از تابع ارزیابی تقریبی استفاده میکنیم که به ما کمک میکند وضعیت فعلی بازی را ارزیابی کنیم و حرکت مناسب را بدون رفتن تا پایان بازی انتخاب کنیم.
یک روش دیگر، جستجوی درخت مونتکارلو (MCTS) است. در این روش به جای استفاده از ارزیابی تقریبی، بازی را تا پایان بارها شبیهسازی میکنیم و نتیجهی هر شبیهسازی را بررسی میکنیم. چون ممکن است حرکات در هر شبیهسازی بهینه نباشند، این شبیهسازیها چندین بار تکرار میشوند و میانگین نتایج، ارزیابی ما از وضعیت فعلی را میسازد.
علاوه بر روشهای جستجو و شبیهسازی، بسیاری از برنامههای بازی از پیشمحاسبه جدول بهترین حرکات استفاده میکنند. به این معنی که برای شروع بازی (شروع بازیها) و همچنین پایان بازی، بهترین حرکتها را از قبل محاسبه کرده و ذخیره میکنند تا برنامه بتواند به جای جستجوی پیچیده، حرکت مناسب را سریع انتخاب کند. این کار باعث افزایش سرعت و دقت بازی میشود.
در بازیهایی که شانسی در آنها نقش دارد، مانند بازیهای تختهای که تاس دارند، الگوریتم مینیمکس به تنهایی کافی نیست. در این موارد از الگوریتم اکسپکتیمینیمکس (Expectiminimax) استفاده میکنیم. این الگوریتم علاوه بر تصمیمگیری منطقی برای بازیکنان، احتمال وقوع هر رویداد شانسی را هم در نظر میگیرد و میانگین ارزش حالات ممکن را محاسبه میکند.
در بازیهای با اطلاعات ناقص، مثل پوکر یا برخی نسخههای شطرنج که بازیکن نمیتواند تمام حرکات حریف را ببیند، انتخاب حرکت بهینه بسیار پیچیدهتر است. در این شرایط، باید دربارهی وضعیت فعلی و آیندهی احتمالی اعتقادات بازیکنان فکر کنیم. یک روش ساده برای تقریبی کردن بهترین حرکت این است که ارزش هر حرکت را بر اساس همهی حالتهای ممکن اطلاعاتی که از حریف نداریم، میانگین بگیریم.
با استفاده از این الگوریتمها و روشها، برنامههای کامپیوتری توانستهاند در بسیاری از بازیها، حتی بازیهای پیچیدهای مانند شطرنج، چکرز، اوتلو و گو، بازیکنان حرفهای انسانی را شکست دهند. با این حال، در برخی بازیهای با اطلاعات ناقص، مانند بریج یا نسخههای خاص شطرنج با اطلاعات محدود، انسان هنوز برتری دارد. در بازیهای ویدیویی پیچیده مثل StarCraft یا Dota 2، برنامهها میتوانند با انسانهای حرفهای رقابت کنند، بخشی از موفقیت آنها ناشی از توانایی انجام تعداد زیادی عمل در زمان کوتاه است، چیزی که برای انسان سخت یا غیرممکن است.
بخش ۷: عاملهای منطقی
برای شروع بحث درباره هوش مصنوعی و عاملهای هوشمند، ابتدا باید بفهمیم یک عامل هوشمند چه چیزی نیاز دارد تا بتواند تصمیمهای درست بگیرد. یکی از مهمترین نیازهای یک عامل هوشمند، دانش درباره جهان است. این دانش، به عامل کمک میکند تا وضعیت محیط خود را بفهمد و بتواند اقدامهای مناسبی انجام دهد.
اما سوال این است که چگونه میتوانیم دانش را در یک عامل هوشمند ذخیره و مدیریت کنیم؟ پاسخ این است که ما دانش را به صورت جملات منطقی در یک زبان نمایش دانش ذخیره میکنیم. این جملات در یک پایگاه دانش نگهداری میشوند و عامل از آنها برای تصمیمگیری استفاده میکند.
یک عامل مبتنی بر دانش معمولاً از دو بخش اصلی تشکیل شده است:
- پایگاه دانش: جایی که تمام جملات و اطلاعات درباره جهان ذخیره میشوند.
- مکانیزم استنتاج: ابزاری که از جملات موجود در پایگاه دانش استفاده میکند تا جملات جدید را استخراج کند و بر اساس آنها تصمیمگیری کند.
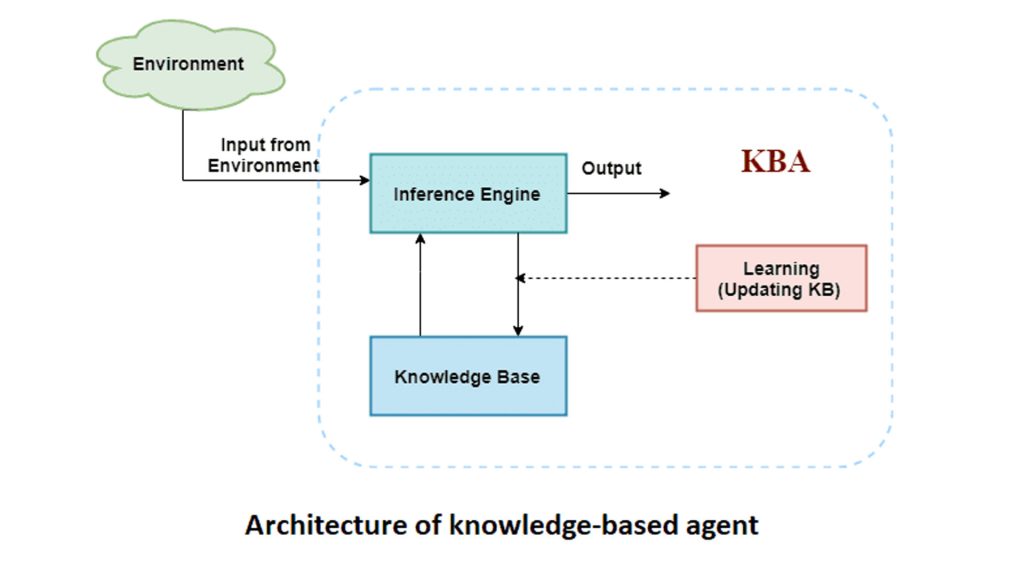
برای اینکه این دانش قابل استفاده باشد، نیاز به یک زبان رسمی داریم که ساختار جملات و معنای آنها را مشخص کند. در این زبان، سینتکس مشخص میکند جملات چگونه ساخته میشوند و سمانتیک تعیین میکند که هر جمله در شرایط مختلف درست یا نادرست است.
یکی از مفاهیم کلیدی در استنتاج منطقی، رابطه استنتاج (Entailment) است. این رابطه نشان میدهد که اگر جملهای درست باشد، جمله دیگری هم الزاماً درست خواهد بود. به عبارت دیگر، جمله دوم در تمام جهانهایی که جمله اول درست است، درست خواهد بود.
استنتاج یا نتیجهگیری، فرآیندی است که در آن جملات جدیدی از جملات موجود استخراج میشوند. الگوریتمهای استنتاج میتوانند دو ویژگی داشته باشند:
- صوتی (Sound): فقط جملاتی را استخراج میکنند که واقعاً از جملات موجود نتیجه میشوند.
- کامل (Complete): تمام جملاتی را که میتوانند نتیجه گرفته شوند، پیدا میکنند.
یکی از سادهترین زبانهای منطقی، منطق گزارهای است. در این زبان، ما با نمادهای گزارهای و عملگرهای منطقی سروکار داریم و میتوانیم گزارههایی را که درست، نادرست یا ناشناخته هستند، مدل کنیم. برای بررسی درستی جملات، میتوانیم تمام مدلهای ممکن را فهرست کنیم و ببینیم جمله در کدام مدلها درست است.
برای کار با پایگاههای دانش بزرگ، روشهای کارآمدی مثل جستجوی محلی و روشهای عقبگرد (Backtracking) وجود دارد که میتوانند مسائل پیچیده را به سرعت حل کنند. علاوه بر این، قواعد استنتاج، الگوهایی از استنتاج درست هستند که میتوانند برای پیدا کردن اثباتها استفاده شوند. روشهایی مثل رزولوشن، زنجیره رو به جلو (Forward chaining) و زنجیره رو به عقب (Backward chaining) نمونههایی از الگوریتمهای استنتاج طبیعی برای پایگاههای دانش هستند.
برای محیطهایی که اطلاعات ما محدود یا ناقص است، میتوان از روشهای جستجوی محلی مثل WALKSAT استفاده کرد. این روشها معمولاً صحیح هستند ولی همیشه همه جوابها را پیدا نمیکنند.
در نهایت، در عاملهای منطقی، میتوان وضعیت جهان را به صورت یک جمله منطقی که تمام حالتهای ممکن مطابق مشاهدات گذشته را توصیف میکند، نگه داشت. هر بار که وضعیت تغییر میکند، با استفاده از مدل انتقال محیط، جمله منطقی بهروزرسانی میشود و عامل میتواند تصمیمات خود را بر اساس آن اتخاذ کند.
با وجود همه این ابزارها، منطق گزارهای یک محدودیت مهم دارد: وقتی محیط خیلی بزرگ یا پیچیده میشود، منطق گزارهای دیگر کافی نیست. دلیل این است که این منطق قدرت کافی برای نمایش مفاهیمی مانند زمان، مکان و روابط عمومی بین اشیاء را بهصورت مختصر ندارد. برای مثال، اگر بخواهیم در مورد همه اشیاء در یک محیط بزرگ قاعدهگذاری کنیم یا تغییرات زمانبندی شده را مدل کنیم، جملات منطقی بسیار طولانی و پیچیده میشوند.
در چنین محیطهایی، ما نیاز داریم از منطقهای قویتر یا روشهای پیشرفتهتر استفاده کنیم که بتوانند روابط کلی و قوانین عمومی را به شکل فشرده و قابل استنتاج نمایش دهند. با این کار، عامل هوشمند میتواند حتی در محیطهایی که تعداد حالتها بسیار زیاد است یا تغییرات زیادی دارند، تصمیمهای منطقی بگیرد.
به طور خلاصه، وقتی یک عامل هوشمند را طراحی میکنیم، مسیر یادگیری و استفاده از دانش به این صورت است:
- ابتدا دانش اولیه درباره جهان را به صورت جملات منطقی تعریف میکنیم.
- این جملات در یک پایگاه دانش ذخیره میشوند.
- عامل با استفاده از الگوریتمهای استنتاج میتواند جملات جدید استخراج کند.
- این جملات برای تصمیمگیری و برنامهریزی اقدامات آینده به کار میروند.
- در محیطهای پیچیده، باید از روشهای منطقی پیشرفته یا تکنیکهای بهینهسازی برای مدیریت دانش و استنتاج استفاده کنیم.
به این ترتیب، یک عامل مبتنی بر دانش میتواند نه تنها اطلاعات موجود را ذخیره کند، بلکه با استنتاج منطقی، اطلاعات جدید ایجاد کند و تصمیمات هوشمندانهای اتخاذ نماید.
بخش ۸: منطق مرتبهٔ اول
وقتی میخواهیم دربارهی «نمایش دانش» در هوش مصنوعی صحبت کنیم، در واقع به زبانی فکر میکنیم که ماشینها با آن میتوانند دنیا را بفهمند. ما انسانها برای توصیف دنیای اطراف از زبان طبیعی استفاده میکنیم؛ اما ماشینها به زبانی دقیقتر نیاز دارند—زبانی که ابهام نداشته باشد و بتوان در آن استدلال منطقی انجام داد. یکی از مهمترین این زبانها، «منطق مرتبهی اول» است.
برای درک منطق مرتبهی اول، بد نیست ابتدا با «منطق گزارهای» آشنا شویم. در منطق گزارهای، ما تنها دربارهی گزارههایی صحبت میکنیم که یا درستاند یا نادرست؛ مثلاً «امروز هوا بارانی است». این زبان برای بیان برخی روابط ساده کافی است، اما وقتی بخواهیم دربارهی اشیا، روابط میان آنها، یا ویژگیهایشان حرف بزنیم، این زبان محدود میشود. برای مثال، اگر بخواهیم بگوییم «هر انسان فانی است»، منطق گزارهای دیگر پاسخگو نیست.
در همینجا است که منطق مرتبهی اول وارد میشود. این منطق به ما اجازه میدهد دربارهی اشیا و روابط میان آنها صحبت کنیم. یعنی بهجای آنکه فقط بگوییم گزارهای درست یا نادرست است، میتوانیم بگوییم چه کسی، چه چیزی، و در چه شرایطی دربارهی چه چیزی صدق میکند. در این زبان، علاوه بر گزارهها، «اصطلاحاتی» وجود دارد که به اشیای خاص اشاره میکنند (مثل «سقراط» یا «زمین»)، و همچنین «نمادهای رابطهای» داریم که بیانگر ارتباط میان اشیا هستند (مثل «بزرگتر از» یا «دوستِ»).
یکی از ویژگیهای کلیدی منطق مرتبهی اول، وجود «کوانتیفایرها» یا «کمیتنماها»ست—ابزارهایی که به ما اجازه میدهند دربارهی همهی اعضای یک مجموعه یا برخی از آنها صحبت کنیم. مثلاً جملهی «برای هر انسان، فانی بودن صادق است» با یک کمیتنمای کلی بیان میشود، و جملهی «برخی انسانها هنرمندند» با کمیتنمای جزئی. همین ابزار ساده اما قدرتمند باعث میشود منطق مرتبهی اول بتواند مفاهیم پیچیدهتری از دنیای واقعی را توصیف کند.
اما نکتهی مهم این است که هر زبان منطقی، مجموعهای از «تعهدات هستیشناختی» و «تعهدات معرفتشناختی» دارد. به زبان ساده، این یعنی هر منطق فرض میکند چه چیزهایی در جهان وجود دارند و ما چگونه میتوانیم دربارهی آنها دانش کسب کنیم. منطق گزارهای فقط وجود «حقایق» را میپذیرد، در حالیکه منطق مرتبهی اول علاوه بر حقایق، به وجود اشیا و روابط میان آنها نیز متعهد است. به همین دلیل، قدرت بیان بیشتری دارد و برای حوزههایی مانند مدلسازی جهان وامپوس یا مدارهای الکترونیکی بسیار مناسبتر است.
برای آنکه بفهمیم یک جمله در منطق مرتبهی اول درست است یا نادرست، باید به چیزی به نام «جهان ممکن» یا بهطور دقیقتر «مدل» نگاه کنیم. مدل در واقع نمایشی از جهانی است که در آن اشیا، روابط، و توابع وجود دارند. هر نماد ثابت در زبان ما به یک شیء در مدل اشاره میکند، هر نماد رابطهای بیانگر نوعی ارتباط میان اشیاست، و هر نماد تابع نیز به ما میگوید چگونه از یک یا چند شیء، شیء دیگری بهدست میآید.
برای مثال، اگر مدلی داشته باشیم که شامل شیءهایی مانند زمین، ماه و خورشید است، رابطهای مانند «میچرخدبهدور» میتواند بگوید که ماه بهدور زمین میچرخد. در چنین مدلی، جملهی «ماه بهدور زمین میچرخد» صادق است، زیرا این رابطه واقعاً میان این دو شیء برقرار است. اما اگر در مدل دیگری چنین رابطهای تعریف نشده باشد، همان جمله در آن مدل نادرست خواهد بود.
در این زبان، سادهترین نوع جمله را «جملهی اتمی» مینامیم. این جمله فقط شامل یک رابطه (یا گزاره) و چند اصطلاح (اشیای شرکتکننده) است. صدق یا کذب آن تنها به این بستگی دارد که آیا آن رابطه واقعاً بین آن اشیا برقرار است یا نه. وقتی جملههای ما شامل کمیتنما میشوند—مثلاً «برای همهی x، اگر x انسان باشد آنگاه فانی است»—دیگر باید بررسی کنیم که آیا این گزاره برای همهی مقادیر ممکن x درست است یا نه. به این ترتیب، معنای صدق جملههای کمیتدار وابسته به «تعبیر گسترشیافتهای» است که تعیین میکند هر متغیر به کدام شیء در مدل اشاره دارد.
اما ساختن یک «پایگاه دانش» (Knowledge Base) بر اساس منطق مرتبهی اول، کار سادهای نیست. این کار معمولاً با تحلیل دقیق حوزهای که میخواهیم دربارهاش استدلال کنیم آغاز میشود. ابتدا باید مشخص کنیم چه نوع اشیایی در آن حوزه وجود دارند، چه ویژگیهایی دارند، و چه روابطی بین آنها برقرار است. سپس، مجموعهای از نمادها و واژگان منطقی تعریف میکنیم تا بتوانیم آن مفاهیم را نمایش دهیم.
در مرحلهی بعد، باید «گزارههای بنیادی» یا همان «اصلها» (Axioms) را بنویسیم—جملاتی که حقیقت آنها را در حوزهی موردنظر مسلم میدانیم. این اصلها پایهی استدلالهای بعدی هستند و سیستم استنتاج ما با استفاده از آنها میتواند گزارههای جدیدی تولید کند. برای مثال، اگر بدانیم «همهی انسانها فانیاند» و «سقراط یک انسان است»، سیستم میتواند بهصورت منطقی نتیجه بگیرد که «سقراط فانی است».
همین توانایی در نتیجهگیری منطقی، همان چیزی است که منطق مرتبهی اول را به ابزار اصلی نمایش و استدلال دانش در هوش مصنوعی تبدیل کرده است. اما باید توجه داشت که این منطق هنوز هم محدودیتهایی دارد. برای نمونه، در بیان مفاهیمی که مرز دقیق ندارند—مثل «بلند بودن»، «طعم خوشمزه»، یا «خوب بودن در سیاست»—نمیتواند عملکرد دقیقی داشته باشد، زیرا این مفاهیم ذاتاً مبهم و وابسته به قضاوت انسانیاند. در چنین مواردی، روشهایی مانند منطق فازی یا یادگیری آماری کارآمدتر هستند.
بخش ۹: استنتاج در منطق مرتبهٔ اول
وقتی میخواهیم به کامپیوترها یاد بدهیم که منطقی فکر کنند و نتیجهگیری کنند، یکی از ابزارهای اصلی ما منطق مرتبه اول است. این منطق به ما اجازه میدهد تا با استفاده از قوانین و روابط بین اشیا و مفاهیم، استنتاج کنیم و نتیجههای جدید به دست آوریم. برای درک بهتر، ابتدا با مثال ساده شروع میکنیم: فرض کنید میدانیم «همه انسانها فانی هستند» و «سقراط انسان است». با استفاده از منطق، میتوانیم نتیجه بگیریم که «سقراط فانی است». همین روند در سطح پیچیدهتر و با جملات ریاضی و قواعد عمومی، پایهای برای هوش مصنوعی است.
یکی از روشهای ابتدایی برای انجام این نوع استنتاج، استفاده از قوانین استنتاج است. این قوانین به ما کمک میکنند تا مسئله استنتاج را به صورت جملات سادهتری (مثل گزارههای منطقی) تبدیل کنیم. البته این روش وقتی که تعداد اشیا و روابط زیاد باشد، بسیار کند میشود.
برای افزایش سرعت، یک تکنیک به نام یکسانسازی یا Unification به کار میرود. این روش به ما اجازه میدهد متغیرها را به گونهای جایگزین کنیم که دیگر نیازی به بررسی همه حالات ممکن نداشته باشیم. ترکیب این روش با یک قانون قدرتمند به نام Modus Ponens تعمیم یافته، امکان استنتاج سریع و طبیعی از مجموعهای از قواعد مشخص را فراهم میکند. الگوریتمهای Forward Chaining و Backward Chaining همین قانون را به کار میگیرند تا اطلاعات موجود را پردازش و نتیجهگیری کنند.
Forward Chaining شبیه یک پایگاه داده است که از اطلاعات موجود شروع میکند و به جلو حرکت میکند تا همه نتایج ممکن را استخراج کند. این روش در سیستمهای بزرگ که قواعد زیادی دارند، کارایی بالایی دارد. از طرف دیگر، Backward Chaining از نتیجهای که میخواهیم به آن برسیم شروع میکند و به عقب برمیگردد تا بررسی کند چه اطلاعاتی برای رسیدن به آن لازم است. این روش در زبانهای برنامهنویسی منطقی مثل پروگ استفاده میشود، که برای استنتاج سریع، از تکنیکهای پیشرفته کامپایلر کمک میگیرد. با این حال، گاهی این روش میتواند دوبارهکاری یا حلقههای بیپایان ایجاد کند که با تکنیکهایی مثل Memoization قابل کنترل هستند.
زبان Prolog یک پیادهسازی عملی از این مفاهیم است. پروگ از فرضیه «جهان بسته» و «نامهای یکتا» استفاده میکند و وقتی نتیجهای نمیتواند اثبات شود، آن را منفی در نظر میگیرد. این ویژگیها پروگ را به یک زبان برنامهنویسی کاربردی تبدیل میکنند، هرچند کمی از منطق خالص فاصله دارد.
یک ابزار دیگر در منطق، قانون استنتاج Resolution تعمیم یافته است که سیستم کاملی برای اثبات در منطق مرتبه اول ارائه میدهد. با این قانون، کامپیوترها میتوانند جملات را به شکل Conjunctive Normal Form تبدیل و اثباتها را به صورت دقیق انجام دهند. برای کاهش حجم جستجو و افزایش سرعت، روشهای متعددی وجود دارد، از جمله تکنیکهای Demodulation و Paramodulation برای مدیریت مساوات.
این روشهای مبتنی بر Resolution نه تنها در مسائل منطقی کاربرد دارند، بلکه در اثبات قضایای ریاضی، بررسی صحت نرمافزار و سختافزار، و حتی سنتز آنها استفاده میشوند. به عبارت دیگر، مفاهیم منطقی پایهای که از ابتدا آموزش دیدیم، در دنیای واقعی برای حل مسائل پیچیده و عملی مورد استفاده قرار میگیرند.
بخش ۱۰: بازنمایی دانش
وقتی میخواهیم به یک رایانه کمک کنیم تا دانش را «فهمیده» و از آن استفاده کند، ابتدا باید فکر کنیم که اصلاً چگونه میتوان دانش را بازنمایی کرد. بازنمایی دانش یعنی اینکه اطلاعات پراکنده و پیچیدهای که انسانها درباره جهان دارند، به شکلی سازمانیافته در یک سیستم کامپیوتری ذخیره شود، تا سیستم بتواند روی آن استدلال کند و تصمیم بگیرد.
برای ساختن چنین سیستمهایی، دانشمندان هوش مصنوعی از چیزی به نام «آنتولوژی» استفاده میکنند. آنتولوژی شبیه یک چارچوب کلی است که همه موضوعات و دستهبندیهای مختلف دانش را کنار هم قرار میدهد و روابط میان آنها را مشخص میکند. اگر بخواهیم یک سیستم هوشمند داشته باشیم که بتواند در زمینههای گوناگون اطلاعات را پردازش کند، نیاز داریم که آنتولوژی ما بسیار جامع و گسترده باشد، بهگونهای که بتواند هر حوزهای از دانش را در خود جای دهد.
ساخت چنین آنتولوژیهای بزرگ کار آسانی نیست. محققان هنوز به آنتولوژیای کامل و همهجانبه دست نیافتهاند، اما چارچوبهایی که امروز وجود دارند، نسبتاً پایدار و قابل اعتماد هستند. یکی از رویکردهای مهم برای این کار، استفاده از «آنتولوژی سطح بالا» است که مفاهیم پایهای و اساسی جهان، مانند دستهها، زیر دستهها، اشیاء ساختاریافته، اندازهگیریها، مواد، رویدادها، زمان، فضا و تغییرات را پوشش میدهد.
در ادامه، به نکتهای جالب میرسیم: برخی مفاهیم طبیعی، مثل انواع موجودات یا مواد، نمیتوانند کاملاً با قوانین منطقی تعریف شوند، اما میتوان ویژگیها و خصوصیات آنها را بازنمایی کرد. به علاوه، رویدادها، اعمال و زمان را میتوان با ابزارهای منطقی مانند «محاسبه رویدادها» مدل کرد. این ابزار به سیستم اجازه میدهد که دنبالهای از اعمال را بسازد و درباره نتایج منطقی آنها پیشبینی کند.
برای اینکه یک سیستم هوش مصنوعی بتواند دانش را بهتر سازماندهی کند، گاهی از «سیستمهای بازنمایی خاص» استفاده میکنیم. این سیستمها شامل شبکههای معنایی و منطقهای توضیحی هستند و به ما کمک میکنند تا سلسلهمراتب دستهها را به شکل منظم و قابل استفاده در کامپیوتر بسازیم. در این سلسلهمراتب، یکی از مهمترین ایدهها «ارثبری» است: اگر یک شیء عضو یک دسته باشد، ویژگیهای آن دسته به طور خودکار به شیء منتقل میشود و سیستم میتواند از این طریق استنتاج کند.
یکی دیگر از مفاهیم کلیدی، «فرض دنیای بسته» است. در زندگی واقعی، ما همیشه همه اطلاعات منفی (مثلاً «این پرنده پرواز نمیکند») را نمیدانیم. فرض دنیای بسته به سیستم میگوید: «اگر چیزی را ندانستی، آن را نادرست فرض کن»، و این کار مدیریت دانش را سادهتر میکند. البته این فرض همیشه قطعی نیست و میتوان آن را با اطلاعات جدید تغییر داد.
در کنار آن، منطقهای غیرمونوتونیک، مانند منطق پیشفرض و محدودسازی، برای مدلسازی استدلالهای پیشفرض به کار میروند. این منطقها به سیستم اجازه میدهند که بر اساس اطلاعات ناقص یا احتمالی استنتاج کند و در صورت دریافت اطلاعات جدید، نتیجهگیریهای قبلی خود را بازنگری کند.
سیستمهای نگهداری حقیقت (Truth Maintenance Systems) هم ابزارهای مهمی هستند که به سیستم هوش مصنوعی کمک میکنند دانش خود را بهروز کنند و تغییرات را به شکل مؤثر مدیریت کنند.
در نهایت، ساختن آنتولوژیهای بزرگ به صورت دستی کار بسیار دشواری است. برای همین، استخراج دانش از متنهای موجود، یکی از راههای عملی و مؤثر برای تسریع این فرایند است. با این روش، سیستم میتواند اطلاعات موجود در مقالات، کتب و منابع آنلاین را جمعآوری و بازنمایی کند و به شکل یک پایگاه دانش بزرگ تبدیل کند.
بخش ۱۱: برنامهریزی خودکار
تصور کنید که میخواهیم به یک ربات یاد بدهیم چگونه کارهای روزانهاش را به طور خودکار انجام دهد. برای انجام این کار، ابتدا باید بدانیم که برنامهریزی خودکار در هوش مصنوعی چیست. به زبان ساده، برنامهریزی یعنی تصمیم گرفتن برای انجام یک سری کارها به ترتیبی که به هدف برسیم. برای این که رایانه بتواند این کار را انجام دهد، نیاز به نمایش صریح از حالتها و کارهایی که میتواند انجام دهد داریم. این نمایشها، پایهای هستند که الگوریتمها روی آنها کار میکنند و باعث میشوند بتوانیم روشهای هوشمند و عمومی برای حل مسائل مختلف طراحی کنیم.
یکی از ابزارهای مهم در این زمینه، زبان تعریف حوزه برنامهریزی یا PDDL است. با PDDL، میتوانیم وضعیت اولیه سیستم و هدف مورد نظر را با استفاده از ترکیبی از گزارههای ساده توصیف کنیم و همچنین کارهایی که ربات میتواند انجام دهد را با پیششرطها و اثراتشان تعریف کنیم. اگر بخواهیم مسائل پیچیدهتر را مدل کنیم، PDDL میتواند مواردی مثل زمان، منابع، ورودیهای حسگری، برنامههای مشروط و حتی برنامههای سلسلهمراتبی را هم در نظر بگیرد.
در ادامه، وقتی این نمایشها آماده شدند، رایانه باید مسیر رسیدن از وضعیت اولیه به هدف را پیدا کند. این کار معمولاً با جستجو در فضای حالتها انجام میشود. جستجو میتواند از وضعیت فعلی به جلو حرکت کند (پیشروی) یا از هدف به عقب بیاید و بررسی کند چه مراحلی منجر به رسیدن به هدف میشوند (پسروی). برای این که جستجو سریعتر و هوشمندانهتر شود، ما از هیوریستیکها استفاده میکنیم؛ یعنی قواعدی که کمک میکنند سریعتر بهترین مسیرها را پیدا کنیم.
علاوه بر جستجوی مستقیم در فضای حالتها، روشهای دیگری هم برای حل مسائل برنامهریزی وجود دارد. یکی از این روشها، برنامهریزی سلسلهمراتبی (Hierarchical Task Network یا HTN) است. در این روش، طراح سیستم میتواند به ربات «راهنمایی» بدهد و کارهای پیچیده را به اقدامات سطح بالا (High-Level Actions یا HLAs) تقسیم کند. این اقدامات سطح بالا میتوانند به روشهای مختلف توسط اقدامات سطح پایینتر اجرا شوند. نکته مهم این است که با تعریف اثرات این اقدامات سطح بالا به شکل منطقی و انتزاعی (به اصطلاح «معنای فرشتهای»)، میتوانیم اطمینان داشته باشیم که برنامههای سطح بالا درست هستند، بدون آن که جزئیات اجرای اقدامات سطح پایین را بررسی کنیم. این روش برای مسائل واقعی و بزرگ بسیار مفید است، چون برنامههای بسیار طولانی و پیچیده را میتوان با آن مدیریت کرد.
گاهی اوقات، هنگام اجرای برنامه، ربات نیاز دارد وضعیت محیط را حس کند و بر اساس آن تصمیم بگیرد کدام مسیر برنامه را ادامه دهد. به این نوع برنامهها برنامههای مشروط یا contingent گفته میشود. در مواردی هم ممکن است ربات بدون هیچ حسگری برنامهای را اجرا کند؛ این حالت را برنامهریزی بدون حسگر (conformant) مینامیم. در هر دو حالت، الگوریتمها با جستجو در فضای حالات اعتقادی (belief states) کار میکنند؛ یعنی وضعیتهایی که ربات ممکن است آنها را باور کند یا فرض بگیرد. طراحی یک نمایش و محاسبه بهینه برای این حالات اعتقادی یکی از چالشهای اصلی برنامهریزی پیشرفته است.
همچنین، در دنیای واقعی، بسیاری از اقدامات مصرفکننده منابع هستند؛ مثل پول، سوخت یا مواد اولیه. به جای آن که بخواهیم هر واحد پول یا سوخت را جداگانه مدیریت کنیم، معمولاً این منابع را به شکل مقادیر عددی کلی مدل میکنیم. زمان نیز یکی از منابع مهم است و میتوان آن را با الگوریتمهای زمانبندی تخصصی مدیریت کرد یا زمانبندی را با برنامهریزی ترکیب کرد تا همزمان به اهداف برسیم و زمان مصرفی بهینه باشد.
در دنیای واقعی، نتایج اقدامات همیشه قطعی نیستند. گاهی اوقات، حتی اگر ربات طبق برنامه عمل کند، اتفاقات غیرمنتظره رخ میدهند، مثل خرابی یک ابزار، تغییرات محیط یا خطای حسگر. برای مدیریت این عدم قطعیتها، برنامهریزی میتواند به شکلهای پیشرفتهتر توسعه یابد. به عنوان مثال، برنامهریزی در محیطهای تصادفی به ربات اجازه میدهد که احتمال وقوع نتایج مختلف یک اقدام را در نظر بگیرد و بهترین تصمیم را بگیرد. ابزارهای ریاضی مثل فرآیندهای تصمیمگیری مارکوف (MDP) و نسخههای جزئی قابل مشاهده آنها (POMDP) برای مدلسازی چنین محیطهایی استفاده میشوند.
یک نکته مهم دیگر این است که رباتها میتوانند در حین اجرا برنامه خود را اصلاح کنند. به این ترتیب، اگر اتفاق غیرمنتظرهای رخ دهد، با مانیتورینگ اجرای اقدامات و اعمال تعمیرات لازم، ربات میتواند مسیر خود را اصلاح کند و به هدف برسد. این توانایی باعث میشود برنامهریزی نه تنها در حالت ایدهآل، بلکه در دنیای واقعی و پویا هم قابل استفاده باشد.
در نهایت، رباتها میتوانند از تجربههای گذشته یاد بگیرند. یادگیری تقویتی (Reinforcement Learning) به ربات امکان میدهد با آزمون و خطا و تحلیل موفقیتها و شکستهای قبلی، رفتار خود را بهبود بخشد. به بیان ساده، ربات مثل یک دانشآموز عمل میکند: وقتی کاری موفقیتآمیز باشد، احتمال انجام آن کار در آینده افزایش مییابد و وقتی ناکام باشد، احتمال کاهش مییابد. این روش، ترکیب برنامهریزی و یادگیری را ممکن میسازد و ربات را قادر میسازد در محیطهای پیچیده و غیرقطعی به طور مستقل عمل کند.
با ترکیب تمام این مفاهیم — از نمایش دقیق وضعیتها و اقدامات، استفاده از هیوریستیکها، برنامهریزی سلسلهمراتبی و مشروط، مدیریت منابع و زمان، تا مقابله با عدم قطعیت و یادگیری از تجربه — ما میتوانیم رباتها و سیستمهای هوشمند بسازیم که در محیطهای واقعی و متغیر، تصمیمات بهینه بگیرند و کارهای پیچیده را به شکل خودکار انجام دهند.
بخش ۱۲: کمّیسازی عدم قطعیت
وقتی میخواهیم یک سیستم هوش مصنوعی بسازیم که در محیطهای واقعی تصمیمگیری کند، با مسئلهای به نام «عدم قطعیت» روبهرو میشویم. عدم قطعیت یعنی اینکه ما همیشه نمیتوانیم بهطور کامل دربارهی حقیقت یک رویداد یا وضعیت در جهان اطرافمان مطمئن باشیم. دلیلش هم ساده است: گاهی ما اطلاعات کافی نداریم و گاهی هم حتی اگر تلاش کنیم، محیط آنقدر پیچیده یا غیرقطعی است که هیچ راهی برای دانستن کامل همه چیز وجود ندارد.
برای مدیریت این عدم قطعیت، ما از نظریهی احتمال استفاده میکنیم. احتمال، درواقع، معیاری است برای بیان میزان باور ما نسبت به یک فرضیه یا جمله. وقتی میگوییم احتمال یک رویداد ۰.۷ است، یعنی سیستم ما با توجه به شواهد موجود، ۷۰٪ اطمینان دارد که این رویداد رخ میدهد. به زبان ساده، احتمال کمک میکند تا بهجای تصمیمگیری مطلق (درست یا غلط)، باورهای خودمان را به شکل عددی بیان کنیم.
اما داشتن باورها به تنهایی کافی نیست. هوش مصنوعی باید تصمیم بگیرد و عمل کند. برای این کار از نظریهی تصمیم استفاده میکنیم. این نظریه ترکیبی است از باورهای سیستم و اهداف آن؛ بهترین عمل، آن است که حداکثر «سود مورد انتظار» یا بیشترین منفعت را برای سیستم ایجاد کند. سود مورد انتظار هم با ترکیب احتمال رخدادهای مختلف و ارزش یا نفع هر نتیجه محاسبه میشود.
در کار با احتمال، مفاهیم پایهای وجود دارند که باید بدانیم:
- احتمال اولیه یا بدون شرط: احتمال یک رویداد قبل از مشاهدهی هر شواهدی.
- احتمال شرطی یا پسینی: احتمال یک رویداد با در نظر گرفتن شواهد موجود.
برای اینکه سیستم ما منطقی رفتار کند، باید قوانین پایهای احتمال، یعنی اصول یا آکسیمهای احتمال، رعایت شوند. اگر این قوانین نقض شوند، سیستم در بعضی شرایط بهطور آشکارا غیرمنطقی تصمیم میگیرد.
وقتی با چندین متغیر تصادفی سروکار داریم، میتوانیم از توزیع احتمال مشترک کامل استفاده کنیم. این توزیع، احتمال هر ترکیب ممکن از مقادیر متغیرها را مشخص میکند. اما مشکل این است که این توزیع معمولاً بسیار بزرگ و غیرقابل استفاده به شکل مستقیم است. خوشبختانه، اگر برخی متغیرها مستقل از هم باشند، میتوانیم توزیع کلی را به توزیعهای کوچکتر تقسیم کنیم و محاسبات را سادهتر کنیم.
یکی از ابزارهای قدرتمند در این زمینه، قاعدهی بیز است. این قاعده به ما اجازه میدهد که احتمال ناشناخته را با استفاده از احتمالهای شرطی شناخته شده محاسبه کنیم. در محیطهای پیچیده، باز هم حجم محاسبات زیاد میشود، اما با استفاده از مفهوم وابستگی شرطی و روابط علی بین متغیرها، میتوانیم توزیعهای بزرگ را به توزیعهای کوچکتر و قابل مدیریت تبدیل کنیم.
یک مثال مشهور در هوش مصنوعی، مدل Naive Bayes است که فرض میکند همهی نتایج (اثرات) نسبت به علت اصلی، مستقل از هم هستند. این سادهسازی باعث میشود حجم محاسبات تنها به تعداد اثرها وابسته باشد و نه به ترکیبهای پیچیده همه متغیرها.
با این روشها، حتی یک عامل هوشمند میتواند دربارهی بخشهای مشاهدهنشدهی جهان، احتمالات را محاسبه کند و تصمیماتی بهتر از یک عامل صرفاً منطقی بگیرد. استفاده از استقلال شرطی باعث میشود این محاسبات عملی و قابل اجرا باشند.
بخش ۱۳: استدلال احتمالاتی
فرض کنید میخواهیم دربارهی اتفاقاتی که در جهان رخ میدهند، تصمیم بگیریم یا پیشبینی کنیم، اما همه چیز مطلق و قطعی نیست. مثلاً نمیدانیم فردی که امروز سرفه کرده، حتماً مریض است یا نه، یا احتمال بارش باران چقدر است. در این شرایط، ما با دانش نامطمئن یا احتمالی سروکار داریم. برای مدلسازی چنین دانش نامطمئنی، یکی از ابزارهای قدرتمند در هوش مصنوعی شبکههای بیزی هستند.
شبکهی بیزی، در سادهترین شکل، یک گراف جهتدار بدون حلقه است. در این گراف، هر گره نمایندهی یک متغیر تصادفی است؛ یعنی چیزی که ممکن است مقدارهای مختلفی داشته باشد و احتمال وقوع هر مقدار قابل محاسبه باشد. هر گره همچنین یک توزیع شرطی دارد که مشخص میکند با توجه به وضعیت والدهایش (گرههایی که به آن وصل هستند)، احتمال هر مقدار چگونه تغییر میکند.
یکی از نکات کلیدی شبکههای بیزی این است که آنها روابط وابستگی و استقلال شرطی بین متغیرها را به شکلی فشرده نمایش میدهند. به بیان ساده، اگر بدانیم بعضی متغیرها مستقل از هم هستند، دیگر نیازی نیست همهی حالات ممکن را جداگانه حساب کنیم. این باعث میشود شبکههای بیزی بتوانند توزیع احتمال مشترک تمام متغیرها را با حجم بسیار کمتری نسبت به فهرست کردن همهی احتمالات ممکن نمایش دهند.
علاوه بر این، بسیاری از توزیعهای شرطی را میتوان با استفاده از خانوادههای استاندارد توزیعها به شکل فشرده نشان داد. وقتی شبکه شامل متغیرهای گسسته و پیوسته باشد، شبکهی بیزی ترکیبی یا هیبریدی گفته میشود و از توزیعهای استاندارد مختلف برای نمایش شرایط استفاده میکند.
فرض کنید حالا میخواهیم بدانیم با توجه به شواهدی که داریم، احتمال رخ دادن یک اتفاق خاص چقدر است. در شبکههای بیزی، به این کار استنتاج گفته میشود. به عنوان مثال، اگر بدانیم فردی سرفه کرده و تب دارد، میخواهیم احتمال بیماری آن فرد را محاسبه کنیم.
برای انجام استنتاج، الگوریتمهای مختلفی وجود دارند. یکی از روشها حذف متغیرها (Variable Elimination) است که سعی میکند با جمعزدن و ضرب کردن احتمالات شرطی به شکل بهینه، احتمال مورد نظر را محاسبه کند. اگر شبکه ساده و تکدرختی باشد، این محاسبات سریع و خطی انجام میشوند. اما در شبکههای پیچیدهتر، محاسبهی دقیق احتمال میتواند بسیار دشوار و حتی غیرقابلحل با منابع محدود باشد.
در چنین مواردی، از روشهای تقریبی استفاده میکنیم، مثل نمونهگیری تصادفی (Random Sampling). یکی از این روشها وزندهی بر اساس احتمال مشاهدهشده (Likelihood Weighting) است و روش دیگر زنجیره مارکوف مونت کارلو (Markov Chain Monte Carlo). این روشها با تولید نمونههای تصادفی و وزندهی آنها، تخمینی از احتمال واقعی ارائه میدهند و میتوانند شبکههای بسیار بزرگ را مدیریت کنند، جایی که محاسبهی دقیق غیرممکن است.
نکتهی مهم دیگر این است که شبکههای بیزی بر تأثیرات احتمالی تمرکز دارند. یعنی آنها نشان میدهند که وقوع یک رویداد چه تأثیری بر احتمال دیگر رویدادها دارد، اما لزوماً نمیگویند که یک رویداد باعث دیگری شده است. اگر بخواهیم علت و معلول واقعی را مدل کنیم، به شبکههای علّی نیاز داریم. این شبکهها اجازه میدهند اثر مداخلات یا تغییرات مستقیم در سیستم را پیشبینی کنیم، نه فقط مشاهدهها را.
به بیان ساده، شبکههای بیزی مانند یک نقشهی راهنمای احتمالات عمل میکنند و شبکههای علّی علاوه بر آن، نقش یک راهنمای علت و معلول را دارند. این ابزارها در هوش مصنوعی، پزشکی، اقتصاد و بسیاری از حوزههای علمی و صنعتی کاربرد دارند و باعث میشوند بتوانیم تصمیمهای بهتر و آگاهانهتری بگیریم.
بخش ۱۴: استدلال احتمالاتی در طول زمان
در علوم هوش مصنوعی و یادگیری ماشین، یکی از مسائل اساسی، مدلسازی و تحلیل فرآیندهای زمانی احتمالاتی است؛ یعنی نحوه تغییر وضعیت جهان در طول زمان و پیشبینی آن با در نظر گرفتن عدم قطعیت. برای مدیریت تغییرات وضعیت جهان، معمولاً مجموعهای از متغیرهای تصادفی تعریف میکنیم که هر یک وضعیت سیستم را در یک لحظه زمانی مشخص نشان میدهند. این رویکرد اجازه میدهد تا به جای نگاه کردن به جهان به صورت یک موجودیت ثابت، آن را به عنوان مجموعهای پویا از احتمالات تصور کنیم.
یکی از مفاهیم کلیدی در این حوزه، خاصیت مارکوف است. این خاصیت بیان میکند که وضعیت آینده یک سیستم، تنها به وضعیت فعلی آن وابسته است و با گذشته مستقل است، مشروط بر آنکه وضعیت حال مشخص باشد. با فرض اینکه فرآیند زمانی همگن است، یعنی قوانین انتقال وضعیت در طول زمان تغییر نمیکنند، مدلسازی و محاسبات بسیار سادهتر میشوند و پیچیدگی کاهش مییابد.
برای توصیف فرآیندهای زمانی احتمالاتی، معمولاً از دو مدل اساسی استفاده میکنیم:
۱. مدل انتقال که چگونگی تغییر وضعیت سیستم از یک لحظه به لحظه بعد را مشخص میکند.
۲. مدل حسگر که فرآیند مشاهده یا اندازهگیری وضعیت سیستم را توضیح میدهد.
پس از تعریف این مدلها، چهار وظیفه اصلی در تحلیل فرآیندهای زمانی مطرح میشود:
- فیلترینگ یا برآورد وضعیت: تخمین وضعیت فعلی سیستم با استفاده از مشاهدات گذشته.
- پیشبینی: تخمین وضعیت سیستم در آینده.
- هموارسازی: بهبود تخمین وضعیت گذشته با در نظر گرفتن مشاهدات بعدی.
- یافتن توضیح محتملترین حالت: شناسایی دنبالهای از وضعیتها که بیشترین احتمال را دارد.
تمام این وظایف با استفاده از الگوریتمهای بازگشتی ساده قابل محاسبه هستند و زمان اجرای آنها متناسب با طول دنباله مشاهدات است.
سه خانواده اصلی مدلهای زمانی که به طور گسترده مطالعه شدهاند عبارتاند از:
- مدلهای مارکوف پنهان (HMM)،
- فیلتر کالمن، و
- شبکههای بیزی پویا (DBN) که دو مدل قبلی را به عنوان حالتهای خاص شامل میشوند.
با این حال، در بسیاری از مسائل واقعی، به ویژه زمانی که تعداد متغیرهای وضعیت زیاد باشد، محاسبه دقیق تقریباً غیرممکن است. در این شرایط، الگوریتمهایی مانند فیلترینگ ذرهای و نسخههای پیشرفته آن، راهحلهای تقریبی کارآمدی ارائه میدهند و میتوانند تخمینهای خوبی از وضعیت سیستم ارائه کنند.
بخش ۱۵: تصمیمگیری ساده
وقتی میخواهیم یک سیستم هوشمند یا «عامل» تصمیمگیرنده بسازیم، باید بتوانیم کاری کنیم که این سیستم بهترین تصمیم ممکن را بر اساس شرایط موجود اتخاذ کند. برای این کار، دو شاخهٔ اساسی در علم هوش مصنوعی به کمک ما میآیند: نظریهٔ احتمال و نظریهٔ سودمندی. نظریهٔ احتمال به ما میگوید یک عامل باید بر اساس شواهد و اطلاعات موجود چه چیزی را باور کند، یعنی پیشبینی کند چه اتفاقی محتمل است. نظریهٔ سودمندی به ما میگوید یک عامل چه چیزی را میخواهد یا ترجیح میدهد. تصمیمگیری علمی دقیقاً جایی شکل میگیرد که این دو را با هم ترکیب کنیم تا مشخص شود یک عامل چه کاری باید انجام دهد.
یک روش متداول برای طراحی این نوع عاملها، بررسی تمام اقدامات ممکن و انتخاب آن اقدامی است که بهترین نتیجهٔ مورد انتظار را ایجاد میکند. چنین سیستمی را «عامل عقلانی» مینامیم. نظریهٔ سودمندی نشان میدهد اگر ترجیحات یک عامل بین گزینههای مختلف، مطابق با مجموعهای از اصول ساده باشد، میتوان آن عامل را با یک «تابع سودمندی» توصیف کرد. عامل سپس اعمال خود را بهگونهای انتخاب میکند که گویی میخواهد سودمندی مورد انتظار خود را بیشینه کند.
گاهی اوقات، وضعیتها ویژگیهای مختلفی دارند که بر سودمندی اثر میگذارند؛ مثلاً در تصمیمگیری دربارهٔ خرید یک خودرو، قیمت، مصرف سوخت و ایمنی همزمان اهمیت دارند. در این شرایط، از نظریهٔ سودمندی چندویژگیای استفاده میکنیم تا بتوانیم ترجیحات را بر اساس مجموعهای از ویژگیها بهطور هماهنگ بررسی کنیم. یک تکنیک مهم در این زمینه، «غلبهٔ تصادفی» است که به ما اجازه میدهد بدون دانستن دقیق عددی همهٔ ارزشها، تصمیمات روشن و غیرابهامآمیز بگیریم.
ابزار دیگری که در تصمیمگیریهای پیچیده کاربرد دارد، «شبکههای تصمیم» است. این شبکهها، نوعی گسترش شبکههای بیزی هستند و علاوه بر گرههای احتمالی، شامل گرههای تصمیم و گرههای سودمندی میشوند. شبکههای تصمیم، چارچوبی ساده و منظم برای بیان و حل مسائل تصمیمگیری فراهم میکنند.
گاهی، پیش از اینکه بتوانیم تصمیم نهایی را بگیریم، لازم است اطلاعات بیشتری جمعآوری کنیم. ارزش اطلاعات به صورت بهبود مورد انتظار سودمندی نسبت به تصمیمگیری بدون آن اطلاعات تعریف میشود. این مفهوم به ویژه هنگام برنامهریزی برای جمعآوری دادهها و تصمیمگیری بهتر اهمیت دارد.
در دنیای واقعی، اغلب نمیتوانیم تابع سودمندی انسانها را به طور کامل و دقیق مشخص کنیم. در چنین شرایطی، ماشینها باید با عدم قطعیت دربارهٔ هدف واقعی انسانها عمل کنند. این عدم قطعیت باعث میشود که ماشین، بهویژه هنگامی که امکان بهدست آوردن اطلاعات بیشتر دربارهٔ ترجیحات انسان وجود دارد، در تصمیمگیری محتاطانهتر عمل کند و حتی در برخی موارد، اجازه دهد که انسان کنترل آن را بر عهده گیرد یا آن را خاموش کند.
بخش ۱۶: تصمیمگیری پیچیده
در هوش مصنوعی، یکی از مسائل اساسی این است که چگونه میتوانیم از دانش خود درباره جهان استفاده کنیم تا تصمیمهایی بگیریم، حتی زمانی که نتایج اقدامات نامطمئن هستند و پاداشهای ناشی از آنها ممکن است تنها بعد از چندین اقدام ظاهر شوند. چنین مسائلی به عنوان «مسائل تصمیمگیری ترتیبی در محیطهای تصادفی» شناخته میشوند و اغلب با عنوان فرآیندهای تصمیمگیری مارکوف یا MDP مطرح میشوند. هر MDP با دو عنصر اصلی تعریف میشود: نخست، مدل انتقال که احتمال نتایج هر اقدام را مشخص میکند، و دوم، تابع پاداش که میزان پاداش در هر حالت را تعیین میکند.
برای ارزیابی کیفیت یک رشته از حالات، مفهومی به نام «فایده» یا utility تعریف میشود که مجموع تمامی پاداشها در طول این رشته است و گاهی برای اعمال تنزیل زمانی، این مقادیر کاهش مییابند تا پاداشهای دورتر، ارزش کمتری نسبت به پاداشهای نزدیکتر داشته باشند. راهحل یک MDP در واقع یک «سیاست» است؛ یعنی قانونی که برای هر حالتی که عامل ممکن است به آن برسد، تصمیم مناسب را مشخص میکند. یک سیاست بهینه، فایده کل رشتههای حالتی که هنگام اجرای آن تجربه میشوند را بیشینه میکند.
ارزش یک حالت، به معنای مجموع انتظاری پاداشهاست، اگر از آن حالت، سیاست بهینه اجرا شود. برای محاسبه این ارزشها، الگوریتمی به نام «تکرار ارزش» وجود دارد که بهصورت مرحلهای، مجموعهای از معادلات را حل میکند و ارزش هر حالت را نسبت به ارزش حالات همسایه آن بهروزرسانی میکند. روش دیگر، «تکرار سیاست» است که به صورت متناوب، ابتدا ارزش حالات تحت سیاست فعلی محاسبه میشود و سپس سیاست موجود بر اساس این ارزشها بهبود مییابد.
وقتی مسئله پیچیدهتر میشود و عامل تنها بخش محدودی از محیط را مشاهده میکند، با مسائل تصمیمگیری مارکوف نیمهقابلمشاهده یا POMDP روبهرو میشویم. این مسائل حل بسیار دشوارتری نسبت به MDP دارند. یکی از راههای حل آنها، تبدیل POMDP به یک MDP در فضای پیوسته «حالات باور» است. در این حالت، همان الگوریتمهای تکرار ارزش و تکرار سیاست قابل استفاده هستند. رفتار بهینه در POMDP شامل جمعآوری اطلاعات برای کاهش عدم قطعیت است، زیرا کاهش عدم قطعیت منجر به تصمیمگیری بهتر در آینده میشود.
برای محیطهای POMDP میتوان یک «عامل تصمیمگیرنده» طراحی کرد که بتواند به شکل مؤثر با عدم قطعیت مواجه شود. این عامل از یک ساختار به نام «شبکه تصمیم دینامیک» استفاده میکند تا مدلهای انتقال و حسگر را نمایش دهد، حالت باور خود را بهروزرسانی کند و سناریوهای احتمالی از رشتههای اقدام را پیشبینی کند. به بیان سادهتر، عامل با هر مشاهده جدید، باور خود درباره وضعیت واقعی محیط را بهروزرسانی میکند و سپس تصمیم میگیرد که چه اقدامی بیشترین پاداش انتظار شده را به همراه خواهد داشت.
یکی از نکات مهم این است که در محیطهای واقعی، عاملها اغلب مجبورند یاد بگیرند که چگونه رفتار خود را بهبود دهند. به همین دلیل، MDPها و POMDPها پایهای برای «یادگیری تقویتی» هستند، شاخهای از هوش مصنوعی که به عاملها اجازه میدهد از تجربه خود بیاموزند و سیاستهای بهتری پیدا کنند. در یادگیری تقویتی، عامل با آزمایش اقدامات مختلف و مشاهده نتایج، ارزش حالات و سیاستهای خود را به تدریج بهبود میبخشد، بدون اینکه نیاز به دانش کامل از مدل محیط داشته باشد.
به این ترتیب، ترکیب دانش جهان، مدلسازی احتمالاتی و استفاده از الگوریتمهای بهینهسازی، امکان طراحی عاملهای هوشمند را فراهم میکند که قادرند در شرایط نامطمئن تصمیمهای بهینه اتخاذ کنند و از تجربههای گذشته خود یاد بگیرند. این چارچوب نه تنها در رباتیک و بازیها کاربرد دارد، بلکه در مسائل پیچیده مدیریتی، پزشکی، حملونقل و بسیاری زمینههای دیگر نیز توانایی ایجاد تصمیمهای مؤثر و بلندمدت را فراهم میکند.
بخش ۱۷: تصمیمگیری چندعاملی
وقتی ما از «برنامهریزی چندعاملی» صحبت میکنیم، منظور موقعیتهایی است که در آن بیش از یک عامل هوشمند در محیط حضور دارد. این عاملها میتوانند روبات باشند، نرمافزارهای هوشمند باشند یا حتی انسانهایی که به صورت مدلسازی شده در یک سامانه تعامل میکنند. در چنین شرایطی، یک عامل نمیتواند صرفاً بر اساس برنامهریزی فردی تصمیم بگیرد؛ زیرا نتیجهی نهایی به تصمیمهای سایر عاملها هم بستگی دارد. بنابراین لازم است «برنامههای مشترک» طراحی شوند. اما حتی اگر یک برنامهی مشترک نوشته شود، همچنان نیاز به نوعی هماهنگی داریم تا عاملها مطمئن شوند واقعاً بر سر اجرای همان برنامهی مشترک توافق دارند.
در اینجا «نظریهی بازیها» وارد میشود. نظریهی بازیها علمی است که رفتار عقلانی موجودات یا عاملها را در موقعیتهای تعاملی توضیح میدهد. همانطور که «نظریهی تصمیمگیری» به ما میگوید یک عامل منفرد چگونه باید بهترین تصمیم را بگیرد، نظریهی بازیها بیان میکند که چند عامل در تعامل با یکدیگر چگونه باید رفتار کنند تا منطقی و بهینه عمل کرده باشند.
برای اینکه بفهمیم «نتیجهی عقلانی» یک بازی چیست، نظریهی بازیها از مفهومهایی به نام «مفاهیم راهحل» استفاده میکند. این مفاهیم در واقع توصیف میکنند که اگر همهی عاملها منطقی باشند، چه نوع نتیجهای حاصل خواهد شد.
اگر عاملها مجبور باشند تصمیمهایشان را مستقل بگیرند و هیچ توافق الزامآوری نداشته باشند، وارد قلمرو «نظریهی بازیهای غیرتعاونی» میشویم. یکی از مهمترین مفاهیم در این حوزه «تعادل نش» است. تعادل نش وضعیتی است که در آن هر عامل استراتژیای را انتخاب کرده که هیچ انگیزهای برای تغییر آن ندارد، زیرا تغییر یکجانبهی استراتژی باعث نمیشود نتیجهی بهتری به دست آورد. این مفهوم پایهی بسیاری از تحلیلهای اقتصادی، اجتماعی و حتی الگوریتمهای هوش مصنوعی است.
در نقطهی مقابل بازیهای غیرتعاونی، «نظریهی بازیهای تعاونی» قرار دارد. در این چارچوب فرض میشود که عاملها میتوانند توافقهای الزامآور داشته باشند و با تشکیل ائتلاف یا گروه، برای رسیدن به اهداف مشترک همکاری کنند. پرسش اصلی این است: کدام ائتلافها پایدار باقی میمانند و چگونه باید منافع حاصل از همکاری بهطور عادلانه بین اعضا تقسیم شود؟
دو مفهوم بنیادی در این حوزه اهمیت ویژهای دارند:
- هسته (Core): هسته به ما میگوید کدام تقسیم منافع میان اعضای یک ائتلاف پایدار است؛ یعنی هیچ گروه کوچکتری از عاملها انگیزه ندارد که از ائتلاف جدا شود و همکاری مستقلی تشکیل دهد.
- ارزش شپلی (Shapley Value): ارزش شپلی روشی ریاضی برای محاسبهی سهم عادلانهی هر عضو در یک ائتلاف است. این روش بر اساس سهم واقعی هر عامل در ایجاد ارزش مشترک عمل میکند. مثلاً اگر در یک پروژهی تیمی، یکی از عاملها نقشی کلیدی در موفقیت دارد، سهم بیشتری از منافع به او اختصاص داده میشود.
علاوه بر این اصول نظری، تکنیکهای عملی نیز برای حل مسائل تصمیمگیری چندعاملی توسعه یافتهاند. برخی از مهمترین آنها عبارتاند از:
- شبکهی قرارداد (Contract Net): روشی برای تقسیم وظایف بین عاملهاست. در این روش یک عامل نقش «مدیر» را دارد و وظیفه را پیشنهاد میدهد، سپس سایر عاملها برای گرفتن آن وظیفه پیشنهاد میدهند و بهترین گزینه انتخاب میشود.
- حراجها (Auctions): یکی از پرکاربردترین ابزارها برای تخصیص منابع کمیاب به عاملهاست. در این روش، عاملها برای بهدست آوردن یک منبع ارزشمند پیشنهاد قیمتی میدهند و مکانیزم حراج بهگونهای طراحی میشود که تخصیص کارآمد و منصفانه اتفاق بیفتد.
- مذاکره (Bargaining): زمانی مطرح است که عاملها منافع مشترک یا متضاد دارند و باید به توافق برسند. فرآیند مذاکره به آنها امکان میدهد در مورد شرایط همکاری یا تقسیم منابع به توافق برسند.
- رأیگیری (Voting): هنگامی که لازم است ترجیحات چند عامل ترکیب شود و یک تصمیم جمعی اتخاذ گردد، از روشهای مختلف رأیگیری استفاده میشود. این مسئله بهویژه در طراحی سامانههای اجتماعی یا تصمیمگیری جمعی میان روباتها اهمیت دارد.
به این ترتیب، نظریهی بازیها و تکنیکهای مرتبط با آن، چارچوبی قدرتمند برای تحلیل و طراحی سیستمهای چندعاملی در اختیار ما قرار میدهند. این چارچوب هم در دنیای نظری (مانند اقتصاد و علوم اجتماعی) و هم در کاربردهای عملی (مانند روباتیک توزیعشده یا سامانههای هوش مصنوعی چندعاملی) بهطور گسترده استفاده میشود.
بخش ۱۸: برنامهنویسی احتمالاتی
مدلهای احتمالی در هوش مصنوعی تنها به چند عدد و فرمول محدود نمیشوند؛ در واقع ما به روشهایی نیاز داریم که بتوانند دنیای پیچیدهی واقعی را با تمام روابط، اشیاء و عدمقطعیتهای آن بازنمایی کنند. یکی از نخستین گامها در این مسیر، مدلهای احتمالی رابطهای یا همان Relational Probability Models (RPMs) است.
در این مدلها فرض میکنیم که تمام اشیاء و هویتشان از پیش مشخص است. برای مثال اگر یک پایگاه داده داشته باشیم که شامل فهرست افراد، کتابها یا شهرها باشد، میتوانیم دقیقاً بگوییم چه اشیائی در جهان ما وجود دارند. در چنین حالتی، متغیرهای تصادفی از روی روابطی ساخته میشوند که میان این اشیاء برقرار میکنیم. مثلاً اگر رابطهی «دوستبودن» را در نظر بگیریم، آنگاه هر جفت از افراد میتواند یک متغیر تصادفی باشد که نشان میدهد آیا این دو نفر دوست هستند یا خیر. از آنجا که تعداد اشیاء معلوم و ثابت است، مجموعهی جهانهای ممکن هم محدود خواهد بود.
مزیت RPMها این است که میتوانند دنیایی با تعداد زیادی شیء را تنها با چند رابطه بهطور فشرده بازنمایی کنند. مثلاً بهجای اینکه برای هر نفر و هر کتاب یک متغیر جدا داشته باشیم، کافی است رابطهی «کتابی را خوانده است» را تعریف کنیم تا بهصورت نظاممند تمام ترکیبهای ممکن پوشش داده شوند. این ویژگی باعث میشود بتوانیم همزمان با دادههای بسیار بزرگ و عدمقطعیتهای رابطهای کار کنیم.
اما جهان واقعی همیشه به این سادگی نیست. گاهی ما از تعداد دقیق اشیاء یا حتی وجود آنها مطمئن نیستیم. در چنین مواردی به مدلهای احتمالی با جهان باز یا Open-Universe Probability Models (OUPMs) نیاز داریم. این مدلها بر پایهی منطق مرتبهی اول ساخته شدهاند، اما امکان بازنمایی عدمقطعیتهای تازهای را فراهم میکنند:
- عدمقطعیت هویت: مثلاً دو مشاهدهی متفاوت ممکن است به یک فرد واحد مربوط باشند یا به دو فرد متفاوت.
- عدمقطعیت وجود: ممکن است ندانیم که آیا شیئی واقعاً وجود دارد یا صرفاً در دادهها بهطور ناقص منعکس شده است.
به این ترتیب OUPMها توانایی بیشتری در تطبیق با پیچیدگیهای جهان دارند و به ما امکان میدهند مدلهایی واقعبینانهتر بسازیم.
حال که با دو چارچوب مهم یعنی مدلهای احتمالی رابطهای (RPMs) و مدلهای جهان باز (OUPMs) آشنا شدیم، باید به پرسشی اساسی پاسخ دهیم: چگونه میتوان همهی این عدمقطعیتها را به شکلی انعطافپذیر و محاسباتی بازنمایی کرد؟ اینجاست که پای برنامههای مولد یا Generative Programs به میان میآید.
ایدهی اصلی این است که یک مدل احتمالی را نه صرفاً بهصورت ریاضی، بلکه به شکل یک برنامهی اجرایی تعریف کنیم. به عبارت دیگر، شما برنامهای مینویسید که در هر بار اجرا، یک «جهان ممکن» یا یک «نمونهی تصادفی» را تولید میکند. در اصطلاح فنی، هر بار اجرای برنامه یک رد اجرا (execution trace) است و مجموعهی همهی این ردها، توزیع احتمالاتی مدل شما را تشکیل میدهد.
این مفهوم بهکمک چیزی بهنام زبانهای برنامهنویسی احتمالی (Probabilistic Programming Languages – PPLs) پیادهسازی میشود. این زبانها شبیه زبانهای برنامهنویسی معمولی (مثل پایتون یا جاوا) هستند، با این تفاوت که دستورات ویژهای برای «نمونهگیری تصادفی»، «شرطگذاری» و «استنتاج» دارند. با استفاده از PPLها، میتوانیم هر نوع مدل احتمالی—even OUPMs—را توصیف کنیم.
ویژگی مهم PPLها قدرت بیان جهانی (universal expressiveness) است. یعنی تقریباً هر ساختار احتمالی که بتوانید تصور کنید، قابل پیادهسازی در قالب یک برنامهی مولد است. این همان نقطهای است که هوش مصنوعی از محدودیتهای مدلهای سنتی فراتر میرود:
- اگر بخواهیم توزیع پیچیدهای را تعریف کنیم که بهراحتی در قالب فرمولهای ریاضی قابل بیان نیست، یک PPL میتواند آن را با چند خط کد بازنمایی کند.
- اگر بخواهیم همزمان با دادههای ناقص، نامعین یا حتی پویا (که در طول زمان تغییر میکنند) کار کنیم، PPLها ابزار مناسبی فراهم میکنند.
- و اگر بخواهیم ترکیبی از منطق، احتمالات و یادگیری ماشین را در یک چارچوب واحد داشته باشیم، باز هم برنامههای مولد گزینهی اصلی هستند.
در عمل، PPLها به پژوهشگران و مهندسان این امکان را میدهند که بهجای درگیر شدن با جزییات پیچیدهی الگوریتمهای استنتاج، تنها «مدل مفهومی» خود را توصیف کنند و سپس موتور استنتاج زبان، کار محاسبه و تقریب را بر عهده بگیرد.
بخش ۱۹: یادگیری از نمونهها
یادگیری ماشینی شاخهای از هوش مصنوعی است که هدف آن، ساخت سامانههایی است که بتوانند از دادهها الگو بگیرند و پیشبینی یا تصمیمگیری کنند. یکی از رایجترین رویکردها در این حوزه، یادگیری نظارتشده است. در یادگیری نظارتشده، ما نمونههایی از ورودیها به همراه پاسخ صحیح آنها را در اختیار مدل قرار میدهیم. وظیفه مدل این است که تابعی بیاموزد که ورودیهای تازه را هم به پاسخ درست نگاشت کند.
اگر خروجیای که بهدنبال آن هستیم مقداری پیوسته باشد، مانند پیشبینی وزن یا قیمت، این مسئله را رگرسیون مینامیم. اما اگر هدف ما تعیین یک دسته یا برچسب از میان چند گزینه محدود باشد، با مسئله دستهبندی مواجه هستیم. در هر دو حالت، نکته کلیدی این است که مدل نهتنها با دادههای آموزشی سازگار باشد، بلکه بتواند روی دادههای جدید هم عملکرد خوبی نشان دهد. به همین دلیل، همواره توازن میان دقت در دادههای آموزش و سادگی مدل اهمیت دارد؛ مدلی بیشازحد پیچیده معمولاً به دادههای موجود «حفظکردنی» نگاه میکند و توانایی تعمیمدادن را از دست میدهد.
برای حل مسائل دستهبندی، یکی از ابزارهای پایهای در یادگیری ماشینی درخت تصمیم است. این روش میتواند همه توابع بولی را بازنمایی کند و با بهرهگیری از معیاری به نام «کسب اطلاعات» بهطور کارآمد درختی بسازد که هم ساده باشد و هم با دادهها همخوانی داشته باشد. عملکرد چنین مدلهایی اغلب از طریق نموداری به نام منحنی یادگیری بررسی میشود. این منحنی نشان میدهد با افزایش حجم دادههای آموزشی، دقت پیشبینی در مجموعه آزمایشی چگونه تغییر میکند.
در عمل، معمولاً بیش از یک مدل یا روش وجود دارد. برای انتخاب بهترین مدل، از فرایندی به نام «انتخاب مدل» و روشی به نام «اعتبارسنجی متقاطع» استفاده میکنیم. بهاینترتیب، میتوانیم مقدار مناسب «فراپارامترها» را بیابیم؛ فراپارامترها مقادیری هستند که رفتار کلی مدل را تعیین میکنند ولی مستقیماً از دادهها آموخته نمیشوند. پس از یافتن این مقادیر، مدل نهایی با همه دادههای آموزشی ساخته میشود.
عامل مهم دیگر در یادگیری ماشینی، نحوه سنجش خطا است. همیشه همه خطاها ارزش یکسانی ندارند. برای مثال، اشتباه در تشخیص یک بیماری خطرناک بسیار مهمتر از اشتباه در پیشبینی قیمت یک محصول ارزان است. اینجاست که «تابع زیان» تعریف میشود؛ معیاری که شدت یا هزینه هر نوع خطا را مشخص میکند. هدف الگوریتم، کمینهکردن مجموع زیانهاست.
مدلهای رگرسیون خطی از پرکاربردترین ابزارهای یادگیری نظارتشده هستند. در این مدلها، خروجی به صورت ترکیبی خطی از ورودیها پیشبینی میشود و پارامترهای مدل یا میتوانند بهطور دقیق محاسبه شوند، یا با استفاده از روش «گرادیان نزولی» یافت شوند. گرادیان نزولی الگویی عمومی است که حتی برای مدلهایی که راهحل تحلیلی بسته ندارند نیز قابل استفاده است و به تدریج پارامترها را طوری تغییر میدهد که خطای پیشبینی کاهش یابد.
پرسپترون، نمونهای از یک طبقهبند خطی است که یک آستانه سخت برای تصمیمگیری دارد. این مدل با قانون ساده بهروزرسانی وزنها میتواند دادههایی که به صورت خطی قابل جداسازی هستند را آموزش دهد، اما در دادههای غیرقابل جداسازی خطی ممکن است همگرا نشود. برای غلبه بر این محدودیت، رگرسیون لجستیک آستانه سخت را با یک تابع نرم جایگزین میکند، به طوری که گرادیان نزولی حتی در دادههای نویزی و غیرخطی نیز عملکرد مناسبی ارائه دهد.
در مقابل مدلهای پارامتریک، مدلهای غیرپارامتریک تمام دادهها را برای هر پیشبینی استفاده میکنند، به جای آنکه دادهها را با چند پارامتر خلاصه کنند. نمونههایی از این مدلها شامل روش نزدیکترین همسایه و رگرسیون وزندار محلی هستند. این مدلها بهویژه وقتی توزیع داده پیچیده باشد، عملکرد خوبی دارند، اما هزینه محاسباتی آنها بالاتر است.
ماشینهای بردار پشتیبان (SVM) روشی قوی برای طبقهبندی هستند که سعی میکنند یک مرز خطی پیدا کنند که فاصله آن با نزدیکترین نمونهها بیشینه باشد. این کار باعث بهبود توانایی تعمیم مدل میشود. اگر دادهها خطی قابل جداسازی نباشند، روش «هسته» یا Kernel، دادهها را به فضایی با ابعاد بالاتر تبدیل میکند که در آن ممکن است یک جداکننده خطی یافت شود.
روشهای جمعی، مانند Bagging و Boosting، معمولاً از هر مدل منفرد قویتر عمل میکنند. در یادگیری آنلاین نیز میتوان نظرات چند «کارشناس» را به تدریج ترکیب کرد تا تقریباً به عملکرد بهترین کارشناس در شرایطی که توزیع دادهها تغییر میکند، رسید.
ساخت یک مدل یادگیری ماشینی موفق نیازمند تجربه در تمام مراحل است: از مدیریت دادهها، انتخاب و بهینهسازی مدل، تا نگهداری و بهروزرسانی مداوم آن. بدون توجه به این فرایندها، حتی بهترین الگوریتمها نیز نمیتوانند عملکرد مطلوب ارائه دهند.
بخش ۲۰: دانش در یادگیری
در یادگیری ماشین، یکی از مهمترین منابع توانمندسازی یک سیستم، دانش پیشین است. وقتی یک عامل (agent) پیش از مواجهه با دادههای جدید، دانش اولیهای دارد، یادگیری او به شکل انباشتی و بهبودپذیر درمیآید؛ به این معنا که هرچه دانش بیشتری کسب کند، توانایی یادگیری او نیز افزایش مییابد. دانش پیشین نه تنها به محدود کردن فرضیههای ممکن کمک میکند، بلکه با «پر کردن» توضیح مثالها، امکان ایجاد فرضیههای کوتاهتر و جامعتر را فراهم میآورد. این امر اغلب باعث میشود عامل بتواند با تعداد مثالهای کمتر و سرعت بالاتری یاد بگیرد.
برای بهرهبرداری مؤثر از دانش پیشین، لازم است نقشهای منطقی مختلف آن شناخته شود. به عنوان مثال، دانش پیشین میتواند به شکل محدودیتهای استنتاجی (entailment constraints) بیان شود و با تحلیل این محدودیتها، تکنیکهای متنوع یادگیری قابل تعریف خواهند بود.
یکی از روشهای مهم، یادگیری مبتنی بر توضیح یا Explanation-Based Learning (EBL) است. در این روش، از روی یک مثال خاص، قوانین عمومی استخراج میشوند. فرایند به این شکل است که ابتدا مثال توضیح داده میشود و سپس این توضیح به یک قانون کلی تعمیم داده میشود. این روش یک رویکرد استنتاجی ارائه میدهد تا دانش اصولی به تخصص عملی و مؤثر تبدیل شود.
روش دیگر، یادگیری مبتنی بر مرتبط بودن یا Relevance-Based Learning (RBL) است. در این رویکرد، دانش پیشین به شکل تعیینکنندهها (determinations) استفاده میشود تا ویژگیهای مرتبط با مسئله شناسایی شوند. نتیجه آن کاهش فضای فرضیه و افزایش سرعت یادگیری است. علاوه بر این، RBL امکان تعمیم استنتاجی از روی یک مثال منفرد را نیز فراهم میکند.
یادگیری استقرایی مبتنی بر دانش یا Knowledge-Based Inductive Learning (KBIL) روش دیگری است که با بهرهگیری از دانش زمینهای، فرضیههای استقرایی تولید میکند که مجموعهای از مشاهدات را توضیح میدهند. یکی از پیادهسازیهای پیشرفته این رویکرد، برنامهنویسی منطقی استقرایی یا Inductive Logic Programming (ILP) است. در ILP، دانش به صورت منطق مرتبه اول بیان میشود و امکان یادگیری دانش رابطهای فراهم میشود، چیزی که سیستمهای مبتنی بر ویژگی قادر به نمایش آن نیستند.
روشهای ILP میتوانند به دو رویکرد متفاوت پیادهسازی شوند: از بالا به پایین، با اصلاح یک قانون بسیار کلی، یا از پایین به بالا، با معکوس کردن فرایند استنتاجی. علاوه بر این، ILP قابلیت تولید گزارههای جدید را دارد که با آنها میتوان نظریههای فشرده و دقیق شکل داد، و به همین دلیل این روشها پتانسیل بالایی برای تشکیل سیستمهای جامع نظریهپردازی علمی دارند.
بخش ۲۱: یادگیری مدلهای احتمالی
یادگیری آماری شاخهای از هوش مصنوعی است که به ما کمک میکند الگوها و روابط موجود در دادهها را کشف کنیم. سادهترین شکل آن محاسبهٔ میانگینها یا شاخصهای آماری اولیه است، اما میتواند به ساخت مدلهای بسیار پیچیده مانند شبکههای بیزی منجر شود. این مدلها کاربردهای گستردهای در علوم کامپیوتر، مهندسی، زیستشناسی محاسباتی، علوم اعصاب، روانشناسی و فیزیک دارند. هدف یادگیری آماری، استفاده از دادهها برای بهبود پیشبینیها و تصمیمگیریها است و این کار را معمولاً با روشهای احتمالاتی انجام میدهد.
یکی از رویکردهای اصلی در یادگیری آماری، یادگیری بیزی است. در این روش، یادگیری به شکل یک استنتاج احتمالاتی دیده میشود: ما با مشاهده دادهها، توزیع اولیهای که نسبت به فرضیهها داریم (prior) را بهروزرسانی میکنیم تا توزیع بهتری بر فرضیهها بدست آوریم. این روش مزیت مهمی دارد؛ به ما اجازه میدهد از اصل سادهگرایی یا تیغ اوکام استفاده کنیم و مدلهای سادهتر را ترجیح دهیم. با این حال، وقتی فضای فرضیهها بسیار بزرگ و پیچیده باشد، انجام این محاسبات میتواند دشوار و تقریباً غیرممکن شود.
یک روش سادهتر و عملیتر از یادگیری بیزی کامل، یادگیری با بیشینهٔ احتمال پسین یا MAP (Maximum a Posteriori) است. در این روش، ما تنها یک فرضیهٔ محتملترین را با توجه به دادهها انتخاب میکنیم. همچنان از توزیع اولیهٔ فرضیهها استفاده میشود، اما این روش معمولاً محاسباتی سادهتر و قابل اجرا در عمل دارد.
روش دیگر، یادگیری با بیشینهٔ درستنمایی یا Maximum Likelihood است. در اینجا، فرضیهای انتخاب میشود که احتمال مشاهدهٔ دادهها تحت آن بیشینه شود. به عبارت دیگر، فرضیهای را انتخاب میکنیم که دادهها را «بهترین شکل» توجیه کند. این روش عملاً با MAP برابر است، اگر توزیع اولیهٔ فرضیهها یکسان یا یکنواخت در نظر گرفته شود. در موارد ساده مانند رگرسیون خطی یا شبکههای بیزی با تمام متغیرها قابل مشاهده، میتوان جواب بیشینهٔ درستنمایی را به شکل تحلیلی و بسته به دست آورد. یادگیری با Naive Bayes نمونهای ویژه است که هم ساده است و هم قابلیت اجرای سریع روی دادههای بزرگ را دارد.
زمانی که برخی از متغیرها پنهان باشند، یافتن بیشینهٔ درستنمایی مستقیم دشوار میشود. در این شرایط، الگوریتم انتظار-بیشینهسازی (Expectation-Maximization یا EM) راهحلهای محلی را ارائه میدهد. این الگوریتم کاربردهای فراوانی دارد، از جمله خوشهبندی بدون نظارت با استفاده از ترکیبهای گاوسی، یادگیری شبکههای بیزی و یادگیری مدلهای مارکوف مخفی.
یادگیری ساختار شبکههای بیزی نمونهای از مسئلهٔ انتخاب مدل است. در این حالت، باید ساختار شبکه را از بین تعداد زیادی از گزینههای ممکن انتخاب کنیم. این معمولاً شامل جستجوی گسسته در فضای ساختارها است و باید روشی برای متعادل کردن پیچیدگی مدل و میزان تطابق آن با دادهها وجود داشته باشد. به عبارت دیگر، مدلی که بیشترین انطباق را با دادهها داشته باشد ممکن است پیچیده و غیرقابل تعمیم باشد، بنابراین انتخاب مدل مناسب همیشه نیازمند تعادل بین دقت و سادگی است.
مدلهای غیرپارامتریک نوع دیگری از یادگیری آماری هستند که برخلاف مدلهای پارامتریک، تعداد پارامترها را از قبل تعیین نمیکنند. در این روش، توزیع با مجموعهٔ دادهها نمایش داده میشود و با افزایش دادههای آموزشی، پیچیدگی مدل نیز افزایش مییابد. روشهای نزدیکترین همسایه (k-Nearest Neighbors) به نقاط داده نزدیک نگاه میکنند و پیشبینی را بر اساس آن انجام میدهند، در حالی که روشهای مبتنی بر هسته (Kernel Methods) ترکیبی از تمام دادهها را با وزندهی بر اساس فاصله تشکیل میدهند. این مدلها انعطاف زیادی دارند و میتوانند پیچیدهترین توزیعها را با دقت بالایی مدلسازی کنند.
یادگیری آماری هماکنون یکی از فعالترین حوزههای تحقیقاتی در هوش مصنوعی است. پیشرفتهای عظیمی هم در نظریه و هم در عمل حاصل شده است، تا جایی که تقریباً میتوان هر مدلی را یاد گرفت، به شرطی که استنتاج دقیق یا تقریبی آن قابل انجام باشد. این توانمندی، یادگیری آماری را به ابزار قدرتمندی برای تحلیل دادهها، پیشبینی و تصمیمگیری تبدیل کرده است و کاربردهای آن همچنان در حال گسترش است.
بخش ۲۲: یادگیری عمیق
شبکههای عصبی ابزارهایی هستند برای مدلسازی توابع پیچیده و غیرخطی که با استفاده از واحدهای خطی-آستانهای پارامتری سازماندهی میشوند. این واحدها بهصورت سلسلهمراتبی در شبکه قرار میگیرند و میتوانند ویژگیهای سطح پایین تا سطح بالا را در دادهها شناسایی کنند. برای آنکه شبکه بتواند عملکرد مناسبی داشته باشد، لازم است پارامترهای آن به گونهای تنظیم شوند که خطای پیشبینی کمینه شود. الگوریتم «پسانتشار» یا back-propagation این فرآیند را با استفاده از روش بهینهسازی گرادیان انجام میدهد و به شبکه اجازه میدهد با بررسی تفاوت بین خروجی پیشبینیشده و مقدار واقعی، پارامترهایش را بهتدریج اصلاح کند.
در سالهای اخیر، یادگیری عمیق یا deep learning توانسته در حوزههای مختلف نتایج چشمگیری ارائه دهد. بهطور خاص، شناسایی اشیاء در تصاویر، تشخیص گفتار، پردازش زبان طبیعی و یادگیری تقویتی در محیطهای پیچیده از جمله زمینههایی هستند که شبکههای عمیق در آنها موفق عمل میکنند. برخی ساختارهای شبکه بهطور ویژه برای نوع خاصی از دادهها مناسباند. برای مثال، شبکههای پیچشی یا convolutional networks برای پردازش تصاویر و دادههایی که ساختار شبکهای یا جدولی دارند، عملکرد بسیار خوبی نشان میدهند. در مقابل، شبکههای بازگشتی یا recurrent networks برای دادههای ترتیبی مثل متن و گفتار، که ترتیب عناصر در آن اهمیت دارد، مناسبتر هستند و کاربردهایی مانند مدلسازی زبان و ترجمه ماشینی دارند.
بخش ۲۳: یادگیری تقویتی
یادگیری تقویتی، یکی از شاخههای مهم هوش مصنوعی است که به ما کمک میکند بفهمیم چگونه یک عامل (یا ربات) میتواند در محیطی ناشناخته مهارت پیدا کند، فقط با استفاده از مشاهدات و بازخوردهایی که گاهبهگاه دریافت میکند. در واقع، این روش، الگویی است برای ساخت سیستمهای هوشمند که بتوانند تجربه کسب کنند و بدون دستور صریح انسان، رفتار بهینهای بیاموزند.
طراحی کلی عامل، تعیین میکند چه نوع اطلاعاتی باید آموخته شود. یک عامل یادگیری تقویتی مبتنی بر مدل، مدلی از محیط و نحوه تغییرات آن در اثر اقدامات خود میسازد و سپس تابع سودمندی هر حالت را میآموزد. در مقابل، یک عامل بدون مدل، مستقیماً یا تابع ارزش هر عمل در هر حالت (که به آن Q-تابع میگویند) یا سیاستی برای انتخاب عملها را میآموزد.
روشهای مختلفی برای یادگیری سودمندی وجود دارد:
- برآورد مستقیم سودمندی: بر اساس پاداشهای مشاهدهشده بعد از یک حالت، مقدار سودمندی آن حالت تخمین زده میشود.
- برنامهریزی پویا تطبیقی (ADP): این روش با استفاده از مدل محیط و تابع پاداش، از طریق تکرار مقادیر یا سیاستها، سودمندی یا سیاست بهینه را محاسبه میکند. ADP از محدودیتهای محلی که ساختار همسایگی محیط ایجاد میکند به بهترین شکل استفاده میکند.
- روشهای تفاوت زمانی (TD): این روشها تخمینهای سودمندی را به گونهای تنظیم میکنند که با حالتهای بعدی سازگارتر شوند. میتوان آنها را تقریب سادهای از ADP دانست که بدون نیاز به مدل محیط نیز میتوانند یادگیری کنند. البته استفاده از مدلی که تجربیات مصنوعی تولید کند، سرعت یادگیری را افزایش میدهد.
Q-تابعها نیز میتوانند با استفاده از ADP یا روشهای TD یاد گرفته شوند. یادگیری Q بدون مدل، در مراحل یادگیری و انتخاب عمل، نیاز به مدل محیط ندارد. این موضوع یادگیری را سادهتر میکند، اما در محیطهای پیچیده ممکن است محدودیت ایجاد کند، زیرا عامل نمیتواند نتایج احتمالی اقدامات مختلف را شبیهسازی کند.
وقتی عامل همزمان با یادگیری مسئول انتخاب اعمال است، باید بین ارزش تخمینی اقدامات و فرصت یادگیری اطلاعات جدید تعادل برقرار کند. یافتن راهحل دقیق برای مشکل کاوش (Exploration) دشوار است، اما قواعد سرانگشتی ساده عملکرد مناسبی دارند. همچنین، عامل کاوشگر باید مراقب باشد که بهطور زودهنگام «از بین نرود» یا شکست نخورد.
در محیطهایی با فضای حالت بسیار بزرگ، الگوریتمهای یادگیری تقویتی نمیتوانند برای هر حالت بهصورت جداگانه ارزش یا تابع Q را ذخیره کنند. در این شرایط، لازم است از نمایش تقریبی تابعی استفاده شود تا یادگیری بتواند بین حالتهای مختلف تعمیم پیدا کند. یکی از موفقترین رویکردها، یادگیری تقویتی عمیق است که در آن از شبکههای عصبی عمیق بهعنوان تقریبزننده تابع استفاده میشود. این روش در مسائل بسیار پیچیده و با تعداد زیاد حالات و اعمال، نتایج قابل توجهی داشته است.
برای یادگیری رفتارهای پیچیده، روشهایی مانند شکلدهی پاداش (Reward Shaping) و یادگیری تقویتی سلسلهمراتبی بسیار مفید هستند. این روشها مخصوصاً زمانی که پاداشها کم و فاصله طولانی بین اقدامات و پاداش وجود دارد، کاربردی هستند و باعث میشوند عامل بتواند مراحل پیچیدهای از رفتارها را بهتدریج یاد بگیرد.
روشهای جستجوی سیاست (Policy Search) مستقیماً روی نمایش سیاست عامل کار میکنند و با مشاهده عملکرد، آن را بهبود میبخشند. مشکل اصلی این روشها، نوسان عملکرد در محیطهای تصادفی است. در محیطهای شبیهسازیشده، میتوان با ثابت کردن بخش تصادفی، این مشکل را کاهش داد.
در مواردی که تعریف تابع پاداش درست دشوار است، یادگیری از استاد (Apprenticeship Learning) راهحل مناسبی است. در این رویکرد، عامل با مشاهده رفتار یک کارشناس، یاد میگیرد. یادگیری تقلیدی (Imitation Learning) مسئله را به شکل یادگیری نظارتشده از زوجهای حالت-عمل کارشناس بیان میکند. یادگیری معکوس تقویتی (Inverse Reinforcement Learning) تلاش میکند اطلاعات پاداش را از رفتار کارشناس استخراج کند.
یادگیری تقویتی یکی از فعالترین حوزههای پژوهش در یادگیری ماشین است. این روش ما را از نیاز به برنامهنویسی دستی رفتارها و برچسبگذاری مجموعه دادههای عظیم که برای یادگیری نظارتشده لازم است، رها میکند. کاربردهای آن در رباتیک بسیار ارزشمند هستند، زیرا رباتها باید بتوانند در محیطهایی با ابعاد بالا و بخشی قابل مشاهده، عملکرد موفق داشته باشند؛ محیطهایی که ممکن است شامل هزاران یا میلیونها اقدام پایه باشند.
تاکنون روشهای متنوعی برای یادگیری تقویتی ارائه شدهاند، زیرا هنوز یک روش واحد و برتر برای تمام مسائل وجود ندارد. بحث بین روشهای مبتنی بر مدل و بدون مدل، در واقع درباره بهترین شکل نمایش عملکرد عامل است. برخی معتقدند اگر داده کافی در دسترس باشد، روشهای بدون مدل میتوانند در هر حوزهای موفق شوند؛ اما در عمل، محیطها ممکن است آنقدر داده فراهم نکنند که این تئوری عملی شود. بهعنوان مثال، تصور اینکه چگونه میتوان با یک روش بدون مدل، پروژهای پیچیده مثل رصدگر امواج گرانشی «لیگو» را طراحی و اجرا کرد، دشوار است. تجربه نشان میدهد هرچه محیط پیچیدهتر شود، مزایای روشهای مبتنی بر مدل آشکارتر میشوند.
بخش ۲۴: پردازش زبان طبیعی
در پردازش زبان طبیعی، یکی از پایهایترین ابزارها مدلهای زبانی احتمالاتی مبتنی بر n-gram هستند. این مدلها قادرند حجم قابلتوجهی از اطلاعات مربوط به یک زبان را بازیابی کنند و میتوانند در طیف گستردهای از وظایف، از شناسایی زبان گرفته تا اصلاح املایی، تحلیل احساسات، دستهبندی ژانر و شناسایی موجودیتهای نامدار، عملکرد مناسبی ارائه دهند. نکته مهم این است که چنین مدلهایی ممکن است میلیونها ویژگی داشته باشند، بنابراین پیشپردازش دادهها و اعمال تکنیکهای هموارسازی برای کاهش نویز ضروری است.
در طراحی یک سیستم زبانی آماری، بهتر است مدلی ایجاد شود که بتواند به شکل بهینه از دادههای موجود استفاده کند، حتی اگر در نگاه اول ساده به نظر برسد. بهبود نمایش کلمات با استفاده از روشهایی مانند word embeddings، امکان نشان دادن شباهتهای معنایی و کاربردی بین کلمات را فراهم میآورد و تصویر غنیتری از زبان ارائه میدهد.
برای درک ساختار سلسلهمراتبی زبان، دستورهای مبتنی بر ساختار عبارات بهویژه دستورهای بدون زمینه (context-free grammar) مفید هستند. فرمالیسم دستور احتمالاتی بدون زمینه (PCFG) و همچنین دستور وابستگی (dependency grammar) در این زمینه بسیار کاربرد دارند. جملات در یک زبان بدون زمینه میتوانند با الگوریتمهای پارسینگ مانند CYK، در زمان O(n³) تحلیل شوند؛ این الگوریتمها نیازمند تبدیل قواعد دستوری به فرم نرمال چامسکی هستند. با کمی کاهش دقت، میتوان زبانهای طبیعی را در زمان O(n) با استفاده از جستجوی پرتو یا پارسر shift-reduce تحلیل کرد.
منابعی مانند treebank برای یادگیری پارامترهای دستور PCFG بسیار ارزشمند هستند. همچنین گسترش دستورها برای مدیریت مسائلی مانند توافق فعل و فاعل، حالت ضمایر و نمایش اطلاعات در سطح کلمات به جای صرفاً دستههای دستوری، کاربرد فراوان دارد. حتی تفسیر معنایی نیز میتواند با استفاده از دستورهای گسترشیافته انجام شود؛ برای مثال، میتوان از یک مجموعه پرسش و پاسخ یا فرمهای منطقی مرتبط با پرسشها، دستور معنایی را یاد گرفت.
طبیعت زبان انسان پیچیده است و به همین دلیل، توصیف کامل آن در قالب یک دستور رسمی دشوار است. مدلها و تکنیکهایی که ارائه شد، تلاش میکنند تا هرچند بهطور تقریبی، این پیچیدگی را در پردازش کامپیوتری بازنمایی کنند.
بخش ۲۵: یادگیری عمیق برای پردازش زبان طبیعی
در پردازش زبان طبیعی، یکی از پیشرفتهای کلیدی، استفاده از نمایشهای پیوستهی کلمات یا همان تعبیههای کلمه (Word Embeddings) است. برخلاف نمایشهای اتمی و گسسته که هر کلمه را به صورت یک نماد مستقل نشان میدهند، تعبیههای کلمه، کلمات را به صورت بردارهایی در یک فضای چندبعدی نمایش میدهند. این بردارها به گونهای یادگیری میشوند که کلمات با معانی مشابه، بردارهای نزدیکی در فضا داشته باشند. نکته مهم این است که این بردارها میتوانند با استفاده از دادههای متنی بدون برچسب آموزش ببینند و به همین دلیل برای مدلهای پردازش زبان بسیار پایدارتر و انعطافپذیرتر هستند.
یکی از چالشهای اصلی در پردازش زبان طبیعی، درک متن در بافت خود است. مدلهای شبکههای عصبی بازگشتی (Recurrent Neural Networks یا RNNs) این امکان را فراهم میکنند که اطلاعات مرتبط از کلمات پیشین در متن حفظ شده و برای پیشبینی کلمات بعدی یا تحلیل جمله استفاده شود. به این ترتیب، RNNها میتوانند هم بافتهای محلی و هم بافتهای دوردست متن را مدل کنند.
برای مسائل پیچیدهتری مانند ترجمه ماشینی یا تولید متن خودکار، مدلهای سلسلهبهسلسله (Sequence-to-Sequence) کاربرد دارند. این مدلها ورودی را به یک نمایش میانی تبدیل میکنند و سپس بر اساس آن، خروجی را تولید میکنند. این رویکرد باعث میشود که مدل بتواند رابطه بین جملات طولانی و وابستگیهای معنایی پیچیده را یاد بگیرد.
یکی دیگر از نوآوریهای مهم، مدلهای ترنسفورمر (Transformer) هستند که به کمک مکانیزم توجه خودی (Self-Attention) قادرند هم بافتهای محلی و هم بافتهای دوردست متن را به شکل مؤثری مدل کنند. این مدلها از عملیات ضرب ماتریس به شکلی بهینه استفاده میکنند و به همین دلیل در پردازش متنهای طولانی و بزرگ مقیاس بسیار کارآمد هستند.
در نهایت، تکنیک یادگیری انتقالی (Transfer Learning) در پردازش زبان طبیعی تحول بزرگی ایجاد کرده است. با استفاده از تعبیههای کلمهی پیشآموزشدیده، مدلها میتوانند از مجموعههای بسیار بزرگ متن بدون برچسب بهره ببرند و سپس برای وظایف خاص مانند پاسخ به سؤال یا تحلیل روابط متنی، با دادههای هدف بهینهسازی شوند. به عبارت دیگر، مدلهایی که برای پیشبینی کلمات گمشده پیشآموزش دیدهاند، با کمی تنظیم میتوانند در طیف وسیعی از وظایف زبانی عملکرد خوبی داشته باشند.
بخش ۲۶: رباتیک
روباتیک علمی است که با عاملهای فیزیکی سر و کار دارد؛ این عاملها توانایی تغییر وضعیت دنیای واقعی را دارند. رایجترین انواع رباتها، بازوهای مکانیکی و رباتهای متحرک هستند. این رباتها دارای حسگرهایی برای درک محیط و عملگرهایی برای ایجاد حرکت هستند که در نهایت از طریق افکتورها بر جهان اثر میگذارند.
یکی از چالشهای اصلی در روباتیک این است که محیط و حرکات ربات اغلب غیرقطعی و ناقص قابل مشاهده هستند. برای مثال، یک ربات نمیتواند همه چیز را به طور کامل ببیند و باید بر اساس اطلاعات محدود تصمیم بگیرد. به همین دلیل از مدلهای ریاضی مانند فرآیندهای تصمیمگیری مارکوف (MDP) و نسخههای جزئی مشاهدهپذیر آنها (POMDP) استفاده میشود. علاوه بر این، رباتها معمولاً در محیطهای پیوسته و با ابعاد بالا عمل میکنند و در دنیای واقعی که خطاها میتواند باعث آسیب واقعی شود، هیچ قابلیت «بازگشت به عقب» وجود ندارد.
در حالت ایدهآل، یک ربات میتواند کل مسئله را یکباره حل کند: اطلاعات خام حسگرها وارد میشوند و حرکت مناسب از طریق موتورها اعمال میشود. در عمل، این کار بسیار پیچیده است، بنابراین متخصصان روباتیک معمولاً مسئله را به بخشهای مختلف تقسیم کرده و هر بخش را جداگانه بررسی میکنند.
بخش اول، درک محیط است. رباتها برای تشخیص اطراف خود از بینایی ماشین استفاده میکنند، اما این فقط یک بخش از مسئله است. آنها همچنین باید موقعیت خود را در محیط شناسایی کرده و نقشهای از محیط بسازند. برای این کار، از الگوریتمهای فیلترینگ احتمالاتی مانند فیلتر کالمن یا فیلتر ذرهای استفاده میشود. این الگوریتمها وضعیت باور ربات، یعنی توزیع احتمال وضعیتهای ممکن، را بهروز میکنند.
بخش دوم، تولید حرکت است. برای تولید حرکت، ربات از مفهوم «فضای پیکربندی» استفاده میکند؛ نقطهای در این فضا مشخص میکند که هر بخش از ربات در کجا قرار دارد. بهعنوان مثال، برای یک بازوی رباتی با دو مفصل، پیکربندی شامل دو زاویه مفصل است. تولید حرکت معمولاً به دو بخش تقسیم میشود: برنامهریزی حرکت، که مسیر حرکت را طراحی میکند، و کنترل مسیر، که ورودیهای عملگرها را برای دنبال کردن مسیر محاسبه میکند.
برای برنامهریزی حرکت میتوان از جستجوی گراف، الگوریتمهای نمونهگیری در فضای پیوسته یا بهینهسازی مسیر استفاده کرد. پس از یافتن مسیر، ربات با استفاده از کنترلکنندههای اصلاح خطا، مانند PID یا کنترل گشتاور محاسبهشده، مسیر را دنبال میکند. روشهای پیشرفتهتر، مانند کنترل بهینه، برنامهریزی و دنبال کردن مسیر را با هم ترکیب میکنند و بهترین مسیر را مستقیماً بر اساس ورودیهای کنترلی محاسبه میکنند.
مسئله روباتیک وقتی چالشبرانگیزتر میشود که رباتها با انسانها تعامل داشته باشند. در این شرایط، ربات باید بتواند اقدامات خود را با حرکات انسان هماهنگ کند و حتی از رفتار انسانها یاد بگیرد. یکی از روشها، یادگیری از طریق مشاهده و تقلید رفتار انسان یا استفاده از بازخورد و دستور زبان طبیعی برای درک اهداف انسان است.
به طور کلی، روباتیک ترکیبی از درک محیط، برنامهریزی حرکت، کنترل دقیق و تعامل هوشمند با جهان واقعی و انسانهاست. این حوزه به ما اجازه میدهد ماشینهایی بسازیم که نه تنها وظایف فیزیکی را انجام دهند، بلکه در محیطهای پیچیده و تغییرپذیر بهطور خودکار تصمیم بگیرند و با انسانها همکاری کنند.
بخش ۲۷: بینایی رایانهای
در نگاه اول، درک و فهم محیط برای انسانها کاری ساده و بدیهی به نظر میرسد، اما در واقع این فرآیند نیازمند محاسبات بسیار پیچیده و دقیق است. هدف اصلی بینایی، استخراج اطلاعاتی است که برای انجام وظایفی مانند دستکاری اشیاء، هدایت در محیط و شناسایی اجسام ضروری است.
مبانی هندسه و اپتیک شکلگیری تصویر به خوبی شناخته شدهاند. اگر توصیفی از یک صحنه سهبعدی داشته باشیم، میتوانیم بهراحتی تصویری از آن از هر زاویه دوربین دلخواه تولید کنیم؛ این همان مسأله گرافیک است. اما مسأله معکوس، که در حوزه بینایی کامپیوتری مطرح میشود، دشوارتر است: گرفتن یک تصویر و تبدیل آن به توصیف سهبعدی صحنه.
نمایشهای تصویری، اطلاعاتی درباره لبهها، بافتها، جریان نوری و نواحی مختلف تصویر ارائه میدهند. این اطلاعات به ما کمک میکنند تا مرزهای اشیاء را شناسایی کرده و رابطه بین تصاویر مختلف را پیدا کنیم.
شبکههای عصبی کانولوشنی قادرند دستهبندیکنندههای تصویری دقیقی تولید کنند که از ویژگیهای یادگرفته شده استفاده میکنند. بهطور تقریبی، این ویژگیها الگوهایی از الگوها هستند. پیشبینی اینکه این دستهبندیکنندهها در چه شرایطی عملکرد خوبی خواهند داشت دشوار است، زیرا دادههای آزمایشی ممکن است از دادههای آموزشی تفاوتهای مهمی داشته باشند. با این حال، تجربه نشان میدهد که اغلب دقت آنها برای کاربردهای عملی کافی است.
دستهبندیکنندههای تصویری میتوانند به شناساییکنندههای اشیاء تبدیل شوند. یک دستهبندیکننده، جعبههای تصویر را از نظر احتمال وجود شی بررسی میکند و دستهبندیکننده دیگری تصمیم میگیرد که آیا شی در آن جعبه وجود دارد و اگر وجود دارد، چه شیئی است. روشهای شناسایی اشیاء کامل نیستند، اما برای طیف گستردهای از کاربردها قابل استفاده هستند.
با داشتن بیش از یک نما از یک صحنه، امکان بازسازی ساختار سهبعدی صحنه و روابط بین نماها وجود دارد. در بسیاری از موارد، حتی میتوان هندسه سهبعدی را از یک نما نیز بازیابی کرد.
روشهای بینایی کامپیوتری امروزه در حوزههای مختلف بسیار گسترده و کاربردی شدهاند.
بخش ۲۸: فلسفه، اخلاق و ایمنی هوش مصنوعی
هوش مصنوعی، شاخهای از علوم کامپیوتر است که به بررسی توانایی ماشینها در انجام کارهایی میپردازد که معمولاً نیازمند هوش انسانی هستند. در این حوزه، فیلسوفان تمایزی میان «هوش مصنوعی ضعیف» و «هوش مصنوعی قوی» قائل میشوند. هوش مصنوعی ضعیف به این فرضیه اشاره دارد که ماشینها میتوانند رفتارهایی هوشمندانه از خود نشان دهند، بدون آنکه ذهن واقعی داشته باشند. در مقابل، هوش مصنوعی قوی به این ایده اشاره دارد که چنین ماشینهایی ممکن است ذهن واقعی داشته باشند، نه صرفاً ذهنی شبیهسازیشده.
آلن تورینگ، از پیشگامان این حوزه، پرسش سنتی «آیا ماشینها میتوانند فکر کنند؟» را کنار گذاشت و به جای آن آزمونی رفتاری طراحی کرد تا رفتار هوشمندانه ماشینها را ارزیابی کند. او پیشاپیش بسیاری از اعتراضها به امکان «تفکر ماشینی» را پیشبینی کرده بود. امروزه بسیاری از پژوهشگران هوش مصنوعی توجه کمی به آزمون تورینگ دارند و تمرکز خود را بر عملکرد عملی سیستمها در حل مسائل واقعی میگذارند، نه بر توانایی ماشین در تقلید رفتار انسانی.
با این حال، خودآگاهی همچنان یک معمای عمیق باقی مانده است. هوش مصنوعی فناوری قدرتمندی است و همین قدرت میتواند خطراتی نیز به همراه داشته باشد؛ از جمله استفاده از سلاحهای خودمختار مرگبار، تهدیدهای امنیتی و نقض حریم خصوصی، پیامدهای ناخواسته، خطاهای غیرعمدی و سوءاستفادههای مخرب. کسانی که در زمینه هوش مصنوعی فعالیت میکنند، مسئولیتی اخلاقی دارند تا این خطرات را بهطور مسئولانه کاهش دهند.
سیستمهای هوش مصنوعی باید توانایی نشان دادن رفتار منصفانه، قابل اعتماد و شفاف را داشته باشند. عدالت در هوش مصنوعی جنبههای متعددی دارد و نمیتوان همزمان تمام آنها را به حداکثر رساند؛ بنابراین، گام نخست تعیین این است که چه چیزی بهعنوان «منصفانه» محسوب میشود.
هوش مصنوعی همچنین در حال تغییر شکل کار و اشتغال انسانهاست. به عنوان جامعه، لازم است با این تغییرات کنار بیاییم و راهبردهایی برای مدیریت آنها تدوین کنیم.
بخش ۲۹: آیندهٔ هوش مصنوعی
هوش مصنوعی را میتوان بهطور ساده بهعنوان طراحی «عاملهای تقریباً عقلانی» تعریف کرد؛ یعنی سیستمهایی که بتوانند تصمیمهایی بگیرند و کاری را انجام دهند که به اهدافشان نزدیک باشد، حتی اگر کامل و بیخطا نباشد. این عاملها میتوانند به شکلهای مختلفی طراحی شوند: از عاملهای واکنشی ساده که فقط به محیط پاسخ میدهند، تا عاملهای پیشرفتهای که بر اساس دانش و نظریه تصمیمگیری عمل میکنند، و یا شبکههای عصبی عمیقی که با استفاده از یادگیری تقویتی رفتار میآموزند.
برای ساخت این عاملها، فناوریهای مختلفی به کار میروند. برخی از آنها مبتنی بر منطق و استدلال صریح هستند، برخی دیگر از احتمالات و مدلهای آماری استفاده میکنند و برخی هم بر شبکههای عصبی و یادگیری ماشین مبتنی هستند. نمایش وضعیتها نیز میتواند متفاوت باشد: گاهی به شکل ساده و اتمی، گاهی با تجزیه و تحلیل اجزای مسئله و گاهی با ساختارهای پیچیده و سلسلهمراتبی. علاوه بر این، الگوریتمهای یادگیری متنوعی وجود دارند که از دادههای مختلف بهره میگیرند و عاملها را قادر میسازند تا تجربه بیاموزند. نهایتاً، حسگرها و محرکها امکان تعامل عاملها با دنیای واقعی را فراهم میکنند.
کاربردهای هوش مصنوعی نیز گسترده است: در پزشکی، امور مالی، حملونقل، ارتباطات و بسیاری حوزههای دیگر. در همه این زمینهها پیشرفت علمی و فناوری قابل توجه بوده و هر ساله ابزارهای دقیقتر و کارآمدتری به دست آمده است. بیشتر متخصصان بر این باورند که پیشرفتها ادامه خواهد داشت؛ برخی برآوردها نشان میدهد که در طول ۵۰ تا ۱۰۰ سال آینده، امکان دستیابی به هوش مصنوعی با سطحی نزدیک به انسان در طیف وسیعی از وظایف وجود دارد. حتی در دهه پیش رو، پیشبینی میشود که هوش مصنوعی سالانه میلیاردها دلار به اقتصاد جهانی اضافه کند.
با این حال، دیدگاههای متفاوتی وجود دارد. برخی منتقدان بر این باورند که هوش مصنوعی عمومی هنوز قرنها با واقعیت فاصله دارد. علاوه بر این، نگرانیهای اخلاقی درباره عدالت، برابری و قابلیتهای آسیبرسان این فناوری بسیار جدی است. بنابراین، پرسشی که مطرح میشود این است: مسیر آینده هوش مصنوعی کجاست و چه موانع و چالشهایی باید پشت سر گذاشته شوند؟ پاسخ به این سؤال مستلزم بررسی دقیق اجزا، معماریها و اهداف سیستمهای هوش مصنوعی است تا اطمینان حاصل شود این فناوری میتواند به نفع بشریت و با کمترین آسیب به کار گرفته شود.
جمعبندی
هوش مصنوعی شاخهای علمی است که هدف آن طراحی سیستمهایی با توانایی انجام وظایفی است که معمولاً به هوش انسانی نیاز دارند. به زبان ساده، هوش مصنوعی یعنی ساخت ماشینهایی که بتوانند بفهمند، یاد بگیرند و تصمیم بگیرند. این حوزه بر پایه مفاهیم بنیادی مانند عاملهای هوشمند، جستوجو، استدلال منطقی و برنامهریزی شکل گرفته و در عین حال توانایی یادگیری و تعامل با محیط را فراهم میآورد.
عاملهای هوشمند هستهٔ اصلی این فناوری هستند؛ آنها با محیط تعامل میکنند و رفتارشان بر اساس عقلانیت تعریف میشود. طراحی الگوریتمهای جستوجو و حل مسئله، از سادهترین روشها تا جستوجوی پیشرفته در بازیها و مسائل بهینهسازی، نمونههایی از کاربرد این اصول در عمل هستند. هوش مصنوعی همچنین با بازنمایی دانش و استدلال منطقی، امکان تصمیمگیری خودکار و مدیریت پیچیدگیهای محیط را فراهم میکند.
در شرایط واقعی که همواره با عدم قطعیت و اطلاعات ناقص مواجه هستیم، استدلال احتمالاتی، شبکههای بیزی، مدلهای مارکوف پنهان و تصمیمگیری چندعاملی ابزارهایی قدرتمند برای انتخاب رفتار بهینه هستند. یادگیری ماشین و یادگیری عمیق نیز قلب هوش مصنوعی مدرن را تشکیل میدهند و به سیستمها اجازه میدهند از دادهها یاد بگیرند، الگوها را تشخیص دهند و عملکرد خود را بهبود دهند. کاربردهای عملی این فناوریها شامل پردازش زبان طبیعی، رباتیک و بینایی رایانهای میشود.
این مقاله در آینده بروزرسانی خواهد شد: تصاویر و نمودارهای بیشتری اضافه خواهند شد، توضیحات عمیقتری ارائه خواهد شد و در صورت نیاز برای هر بخش، مقالهای جداگانه و مفصل نوشته خواهد شد. ما بسیار دوست داریم نظر شما را هم اکنون پای همین مقاله فعلی بشنویم؛ دیدگاهها و پیشنهادهای شما به بهبود این مطلب کمک خواهد کرد.
آرزوی موفقیت داریم در مسیر یادگیری هوش مصنوعی و امیدواریم این مقاله نقطهٔ شروعی الهامبخش برای شما باشد.





ما اخیرا مدل جدیدی از شبکههای عصبی رو طراحی کردیم.بدون نیاز به سخت افزار خاص، بدون جعبه سیاه، بدون توهم و حتی 1درصد خطا در خروجی، قابلیت خلاقیت واقعی، context نامحدود، قابلیت کنترل سخت افزار و خیلی مزیتهای دیگه هم داره.هم از الگوریتم در تولید متن میشه استفاده کرد و هم تولید تصویر.تصور کنید هوش مصنوعی بتونه بجای ساختن یه عکس، یه فایل لایه باز خروجی بده! اما مدتهاست درگیر یه ارتباط ساده با دنیا هستیم.این خودش بیانگر خیلی از معانی هست.
ما هنوز به هوش مصنوعی نرسیدیم.هوش مصنوعی تا امروز نه چالشی رو حل کرده، نه یه فرمول ریاضی کشف کرده و نه حرف جدیدی زده. مشابه موتورهای جستجو، هوش مصنوعی صرفا جستجوگر کلمات مرتبط با الگوهای شبیه بهم هست.دلیلش هم خیلی ساده هست که چرا هرگز هوش مصنوعی واقعی ساخته نخواهد شد.به این دلیل که مزیت رقابتی تمام غولهای فناوری،نظامی و تحقیقاتی از بین میره و تعادل بازار و دولتها بهم میخوره.بنابراین شایسته نیست به این سیستم های طوطیوار لفظ هوش مصنوعی بدیم.دستیار مصنوعی یا AA بهتره به نظرم.
ارسطو (Aristotle)، فیلسوف یونانی، از اولین کسانی بود که سعی کرد «تفکر درست» رو به شکل قوانین مشخصی تعریف کنه – یعنی فرایندهای استدلالی که غیرقابلانکار هستن. قیاسهای منطقی ارسطو الگوهایی برای ساختار استدلال ارائه دادن که همیشه، با فرض درستی مقدمات، به نتایج درست میرسن
اطلاعات جالبی داشت ، ممنون