

مدلهای انتشار (Diffusion Models) ابزارهایی قدرتمند در دنیای هوش مصنوعی هستند که برای خلق تصاویر و صداهای باکیفیت به کار میروند. این مدلها نوعی از مدلهای مولد هستند که میتوانند تصاویر یا صداهایی شبیه به دادههای واقعی تولید کنند. در مقایسه با مدلهای دیگر مثل شبکههای مولد تخاصمی (GAN)، مدلهای انتشار کیفیت بالاتری دارند، اما زمان بیشتری برای تولید خروجی نیاز دارند.
خودرمزگذارهای واریاسیونی (VAE)
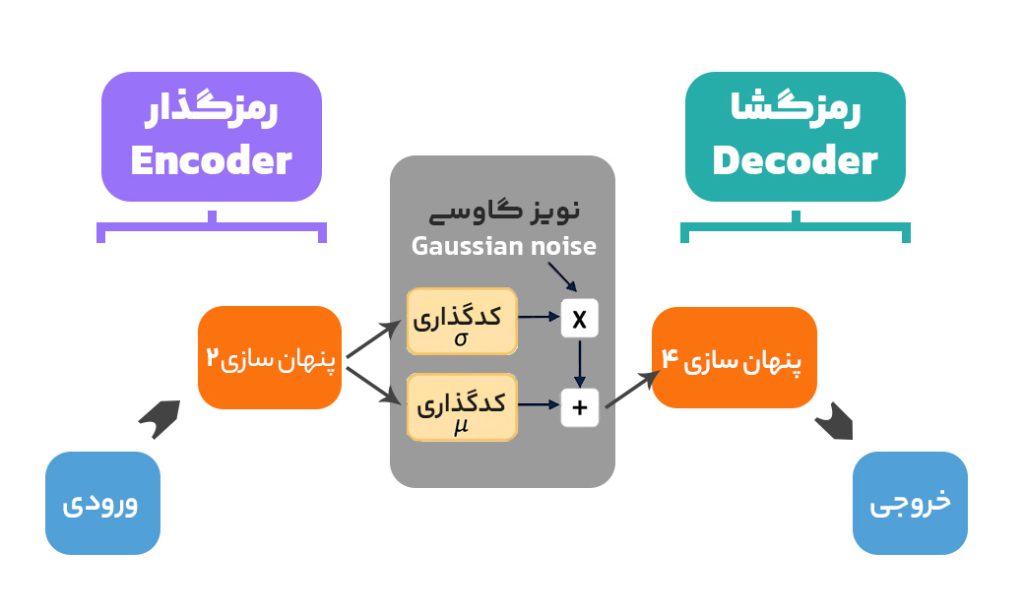
یکی دیگر از ابزارهای هوش مصنوعی، مدلهای خودرمزگذار واریاسیونی یا VAE هستند. این مدلها دادهها (مثل تصویر یا صدا) را فشرده کرده و سپس سعی میکنند همان داده را دوباره بسازند. این فرآیند شبیه به فشردهسازی و باز کردن یک فایل زیپ است.
ساختار VAE از دو بخش اصلی تشکیل شده:
- رمزگذار (Encoder): داده ورودی (مثل یک عکس) را به یک فرم فشرده تبدیل میکند.
- رمزگشا (Decoder): از فرم فشرده، داده اصلی را بازسازی میکند.
هدف VAE این است که دادههای اصلی را با دقت بازسازی کند و در عین حال بتواند دادههای جدید و مشابه تولید کند. این ویژگی باعث میشود VAE در تولید تصاویر یا صداهای متنوع بسیار مفید باشد.
مدلهای انتشار چگونه کار میکنند؟
تصور کنید یک نقاشی زیبا دارید و به تدریج روی آن رنگ میپاشید تا کاملاً محو شود و فقط یک صفحه سفید باقی بماند. حالا هدف این است که یاد بگیرید چگونه این رنگهای اضافی را پاک کنید تا نقاشی اصلی برگردد. مدلهای انتشار هم همینطور عمل میکنند: ابتدا در چندین مرحله نویز (شبیه به رنگهای اضافی) به یک تصویر اضافه میکنند تا کاملاً نویزی شود، سپس یاد میگیرند این نویز را مرحله به مرحله حذف کنند تا تصویر اصلی یا مشابه آن بازسازی شود.
با یاد گرفتن این هدف، مدلهای پراکندگی میتوانند هر تصویر کاملاً نویزی—مثل یک صفحهی سفید یا ماتریسی از نویز تصادفی—را بهتدریج به یک تصویر با جزئیات واقعی و منسجم تبدیل کنند. در شبکههای عصبی معمول، ورودی یکسان همیشه خروجی یکسان تولید میکند؛ یعنی اگر مداوماً صفحه سفید به شبکه بدهیم، خروجی همواره همان تصویر یکسان خواهد بود. برای ایجاد تنوع در نتایج، در فرآیند پیشرو (forward diffusion) بهصورت گامبهگام نویز تصادفی از توزیع گاوسی به دادهها اضافه میکنیم تا در انتها تنها یک نمونهی خالص از نویز باقی بماند. سپس در فرآیند معکوس (denoising) یک شبکهی عصبی آموزشدیده، در هر گام، الگوی کاهش نویز را پیشبینی و با کمینهسازی خطای بازسازی، نویز را حذف میکند. با تغییر نمونهی اولیه (بذر تصادفی) برای شروع فرآیند یا نمونهبرداری مجدد از توزیع گاوسی، میتوانیم تصاویر متنوع اما واقعگرایانه تولید کنیم.
برای اعمال کنترل دقیقتر روی ویژگیهای خروجی، میتوان مدل پراکندگی را شرطیسازی (conditioning) نمود: ابتدا مشخصات مورد نظر (مثلاً برچسبهای موضوعی یا بردارهای ویژگی استخراجشده از متون تخصصی) را بهعنوان ورودی کمکی در هر گام معکوس وارد مدل میکنیم. این روش تضمین میکند که تصویر نهایی دقیقاً مطابق با ساختار و ویژگیهای مورد انتظار ما شکل گیرد و همزمان از خلاقیت ذاتی فرآیند پراکندگی بهره ببرد.
بنابراین این فرآیند شامل دو مرحله است:
- فرآیند پیشرو: تصویر اصلی به تدریج با نویز ترکیب میشود تا کاملاً نویزی شود.
- فرآیند معکوس: مدل یاد میگیرد از تصویر نویزی، تصویر اصلی را بازسازی کند.

تفاوتهای مدلهای انتشار و VAE
هر دو مدل انتشار و VAE برای تولید دادههای جدید (مثل تصویر یا صدا) استفاده میشوند، اما روش کارشان متفاوت است:
- VAE
این مدل دادههای ورودی را به یک نمایش فشرده (latent) تبدیل میکند و سپس در یک مرحله از آن نمایش برای بازسازی یا تولید دادهی جدید استفاده میکند. مزیت اصلی VAE سرعت بالای نمونهسازی و استفاده بهینه از منابع محاسباتی است، اما خروجیهای آن گاهی محو و با جزئیات کمتر بهنظر میرسند. دلیل این محوشدگی، تقریب گوسی در فضای latent و خلاصهسازی همهی جزئیات در یک بردار است. - مدلهای انتشار
در این روش، تبدیل از نویز کامل به تصویر نهایی در چندین گام انجام میشود: ابتدا نویز تصادفی به داده اضافه میشود (forward diffusion) و سپس یک شبکهی عصبی در هر گام معکوس (denoising) پیشبینی میکند که چگونه نویز را کاهش دهد. این فرآیند چندمرحلهای باعث میشود هر بار جزئیات جدید به تصویر افزوده شود و در نتیجه کیفیت نهایی بسیار بالا و واقعیتر باشد. اما هزینهی زمانی و محاسباتی نمونهسازی (sampling) در مدلهای انتشار بیشتر است.
مدلهای انتشار معمولاً از شبکههای پیچیدهتری مثل U-Net استفاده میکنند، در حالی که VAE از ساختارهای سادهتر بهره میبرد. انتخاب بین این دو به نیاز پروژه بستگی دارد: اگر سرعت مهم باشد، VAE مناسبتر است؛ اما اگر کیفیت اولویت دارد، مدلهای انتشار بهتر هستند.
مدل U-Net
مدل U-Net قلب مدلهای انتشار است. این مدل مثل یک فیلتر عمل میکند که نویز را از تصاویر حذف میکند. U-Net از دو بخش تشکیل شده:
- بخش رمزگذار: ویژگیهای مهم تصویر (مثل شکلها و رنگها) را استخراج میکند.
- بخش رمزگشا: با استفاده از این ویژگیها، تصویر تمیز را بازسازی میکند.
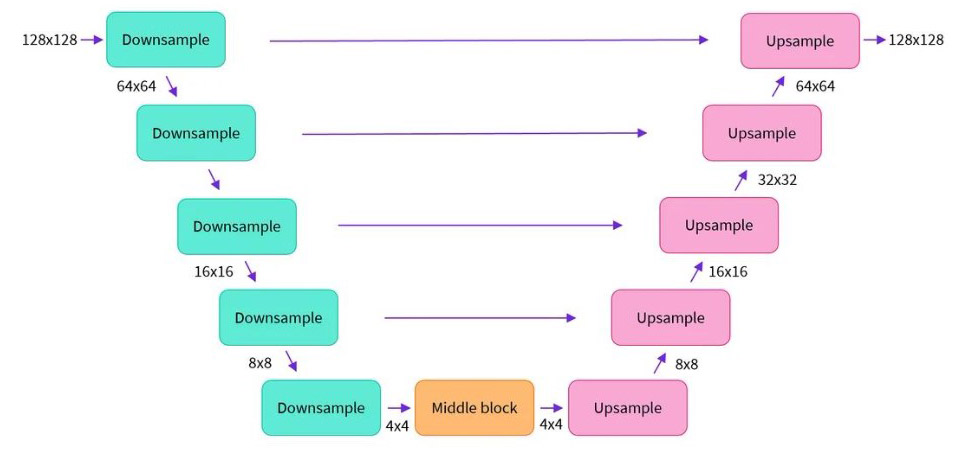
اتصالهای کوتاه بین رمزگذار و رمزگشا کمک میکنند تا جزئیات کوچک تصویر مثل لبهها و بافتها حفظ شوند. این ساختار باعث میشود U-Net بتواند تصاویری با کیفیت بسیار بالا تولید کند.
کاربردهای مدلهای انتشار
مدلهای انتشار در زمینههای مختلفی استفاده میشوند. در ادامه چند نمونه را معرفی میکنیم:
- DALL·E 2: این مدل از متن (مثل «یک گربه با کلاه جادوگری») تصاویر خلاقانه تولید میکند. ابتدا متن را به یک کد مفهومی تبدیل میکند و سپس با فرآیند انتشار، تصویر نهایی را میسازد.
- Imagen گوگل: مشابه DALL·E 2، اما با استفاده از مدلهای زبانی قویتر، تصاویری با جزئیات دقیقتر تولید میکند. این مدل به سختافزار قدرتمند نیاز دارد.
- DiffWave و WaveGrad: این مدلها برای تولید صدا استفاده میشوند. DiffWave صداهای واضح و طبیعی تولید میکند، در حالی که WaveGrad سریعتر عمل میکند بدون افت کیفیت.
- Grad-TTS: برای تبدیل متن به گفتار با کنترل دقیق روی لحن و سرعت استفاده میشود.
- AudioLDM: صداهای متنوعی مثل موسیقی یا افکتهای محیطی تولید میکند.
- DiffSinger: برای تولید آواز طراحی شده و میتواند ملودی و صدای خواننده را با دقت بازسازی کند.







واقعا یکی لز مزایایی اصلی VAE سرعت بالای نمونهسازی و استفاده بهینه از منابع محاسباتیه