


تو چند سال اخیر یه چیز خیلی مهم تو دنیای هوش مصنوعی اومده که بهش میگن مدلهای بنیادی یا همون Foundation Models. این مدلها کلی داده رو از اینترنت جمع میکنن، بعد یه مدل خیلی بزرگ و همهفنحریف آموزش میدن که تقریباً هر کاری ازش برمیاد، اونم بدون اینکه نیاز باشه برای هرکار خاص از اول آموزش ببینه!
دو تا از معروفترین نمونههاش: CLIP و SAM هستن. هر کدوم تو یه بخش خاص خیلی قویان، اولی تو درک تصویر از طریق متن، دومی تو جدا کردن بخشهای مختلف تصویر.
۱. CLIP: مدل چندکاره برای فهم تصویر و متن
CLIP یه مدل ترکیبیه. یعنی هم عکس میفهمه، هم متن. بعدشم میتونه بگه این دوتا به هم مربوطان یا نه.
ماجرا اینجوریه: CLIP رو با ۴۰۰ میلیون جفت عکس و متن آموزش دادن. یعنی مثلاً یه عکس از یه سگ، کنارش یه جمله مثل “یه سگ پشمالو توی پارک” بوده. مدل یاد گرفته از روی متن بفهمه عکس چی نشون میده.

چرا CLIP مهمه؟
خب ببین، مدلهای دیگهی بینایی ماشین (مثل تشخیص اشیاء) معمولاً با کلی دادهی برچسبخورده آموزش میدیدن. یعنی آدم باید مینشست میگفت تو این عکس یه ماشین هست، یه گربه هست، فلان. این کار خیلی وقتگیره. ولی CLIP با دادههای اینترنتی آموزش دیده، اونم بدون اینکه حتماً یکی بهش بگه چی چیه!
از اون مهمتر: CLIP میتونه بدون آموزش دوباره روی یه کار جدید، همون اول بره و اون کار رو انجام بده. به این میگن Zero-Shot. یعنی انگار مدل اصلاً اون کارو ندیده، ولی بلده انجامش بده.
ساختار CLIP چطوریه؟
مدل دو تا بخش داره: یه رمزگذار متن (که همون ترنسفورمره) و یه رمزگذار تصویر (که میتونه ResNet یا ViT باشه). هردوشون خروجیشون رو میدن به یه سیستم که میگه چقدر متن و عکس به هم میخورن. شبیه اینه که بگی: “این جمله چقدر به این عکس میخوره؟”

یه نکته باحال: مدل CLIP با ۵۹۲ تا کارت گرافیک قوی به مدت ۱۸ روز آموزش دیده! یعنی اگه میخواستی با یه کارت گرافیک عادی آموزش بدی، باید بیشتر از ۲۹ سال وقت میذاشتی!
حالا اینا چه فایدهای داره؟
مثلاً فرض کن میخوای یه مدل داشته باشی که بگه این عکس مربوط به «دوچرخه» یا «اسب»ه. مدلهای معمولی باید با برچسب خاص آموزش ببینی. ولی CLIP فقط لازمه بدونی دنبال چیای، بعد یه جمله مثل «یه عکس از دوچرخه» بهش بدی، خودش میفهمه.
این یعنی خیلی راحت میتونی کلاسهای جدید تعریف کنی، فقط با نوشتن یه جمله! لازم نیست مدل رو از اول آموزش بدی.
عملکردش چطوره؟
محققها اومدن CLIP رو با مدلهایی که اختصاصی آموزش دیده بودن مقایسه کردن، نتیجه هم جالب بود: CLIP حتی بدون تنظیم خاص، به همون خوبی کار میکرد. جالبه که عملکردش حتی با استفاده از فقط ۴ نمونه آموزشی، برابر بوده با مدلهایی که کلی آموزش دیده بودن!
۲. SAM: مدل «هرچی دیدی جدا کن!»
SAM یه مدل فوقالعاده برای جداسازی بخشهای مختلف عکسهاست. مثلاً میخوای فقط ماشین تو عکس رو جدا کنی؟ یا یه قسمت خاص از چهره؟ این مدل این کارو میتونه با گرفتن یه اشاره کوچیک (مثل یه نقطه یا یه ماسک) انجام بده.

مدل از چی تشکیل شده؟
SAM هم سه بخش داره:
- رمزگذار تصویر: تصویر رو به یه حالت قابل فهم برای مدل تبدیل میکنه.
- رمزگذار Prompt: هر نوع ورودی کاربر (متن، نقطه، جعبه، ماسک) رو پردازش میکنه.
- رمزگشای ماسک: از ترکیب اطلاعات بالا، یه ماسک خروجی میده که نشون میده کدوم بخش از تصویر منظوره.
نکته اینجاست که اگه فقط یه نقطه به مدل بدی، ممکنه مدل ندونه دقیقاً منظورت چیه. برای همین همیشه سه تا ماسک مختلف میده: یکی برای کل شیء، یکی برای بخش اصلی، یکی برای زیرمجموعهها.
مجموعه دادهی عظیم SAM
تیم سازندهی SAM یه مجموعه داده درست کردن به اسم SA-1B که توش ۱۱ میلیون عکس هست و بالای ۱ میلیارد ماسک! یعنی یه منبع عظیم برای تمرین و آزمایش.
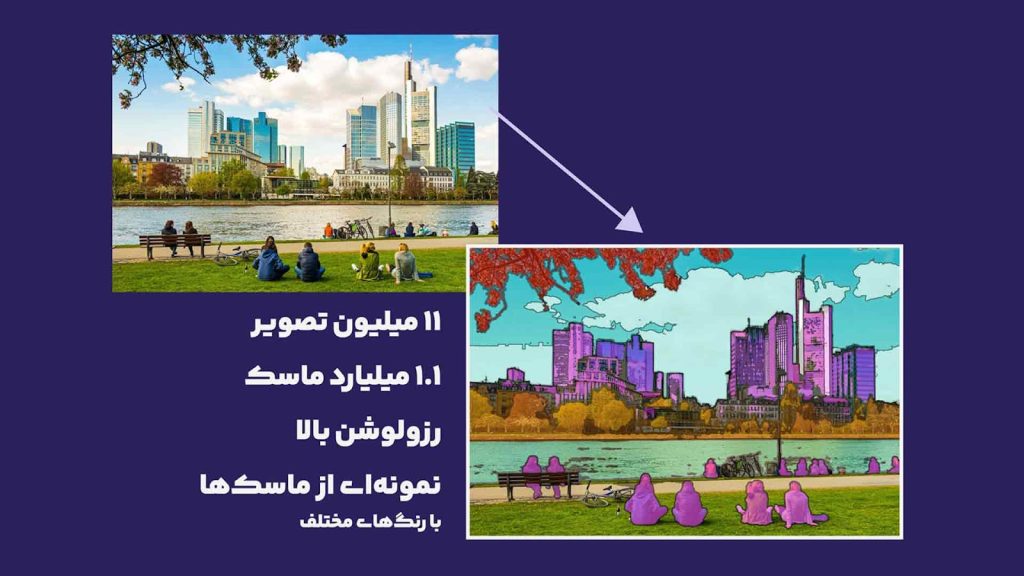
این دادهها تو سه مرحله تولید شدن:
- نیمهدستی: آدمها با کمک مدل اولیهی SAM شروع کردن به برچسبگذاری.
- نیمهخودکار: مدل خودش ماسک اولیه رو میداد، آدمها اصلاح میکردن.
- خودکار کامل: مدل با یه شبکه نقطهای روی عکسها، خودش بهتنهایی ماسک تولید میکرد.
آزمایشهای SAM
مهمترین ویژگی SAM اینه که بتونه با ورودی کم، جداسازی دقیق انجام بده. برای همین آزمایشهاش بیشتر حول همون Zero-Shot بودنشه.

- تو آزمایش با یه نقطه، SAM تو ۱۶ تا از ۲۳ مجموعه داده، از RITM بهتر بود.
- تو حالتی که بهترین ماسک انتخاب میشه (مثل حالت آرمانی)، تو همهی مجموعهها بهتر عمل کرد.

یه ویژگی باحال دیگه اینه که SAM میتونه با متن هم کار کنه. مثلاً اگه بهش بگی “چراغ جلوی ماشین”، دقیقاً همون بخشو جدا میکنه. البته این قابلیت هنوز تو کد رسمیشون فعال نیست، ولی تو مقاله نشون دادن که شدنیه.
تو یه آزمایش دیگه، SAM یه شبکه نقطهای ۱۶ در ۱۶ روی تصویر گذاشت، بعد از اون ماسک ساخت، بعد هم لبههای تصویر رو استخراج کرد. نتیجه؟ SAM جزئیات خیلی بیشتری نسبت به مدلهای دیگه گرفت.
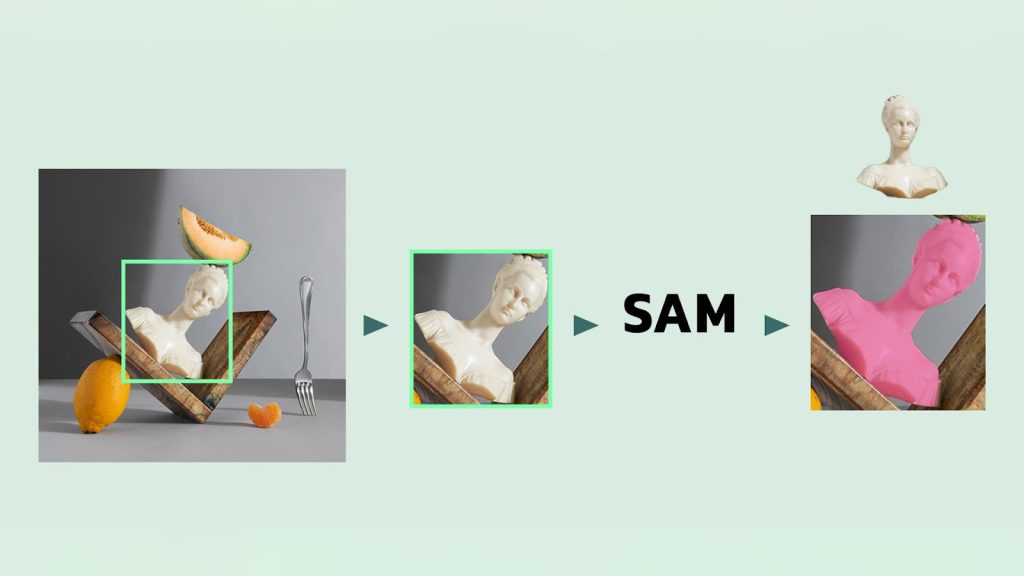
اینجا اول یه مدل دیگه مثل ViTDet جعبه دور شیء رو مشخص میکنه، بعد SAM با کمک همون جعبه، ماسک نهایی رو تولید میکنه.
تهش چی شد؟
مدلهای CLIP و SAM، نشون دادن که میشه بدون نیاز به دادهی خیلی خاص یا آموزش طولانی، کارهای پیچیدهای مثل درک تصویر یا جداسازی رو انجام داد. این یعنی دنیای هوش مصنوعی داره میره به سمتی که مدلها همهکاره و آمادهی استفاده باشن — فقط کافیه یه اشاره بهشون بدی.







واقعا این سرویس هایی که میتونن با پرامپت تصویر رو ویرایش کنن جالبن