

سلام! امروز میخوام درباره یک مدل تبدیل متن به گفتار (TTS) به نام زونوس (Zonos) صحبت کنم که اخیراً توجهم رو جلب کرده. این مدل توسط استارتاپ زایفرا (Zyphra) توسعه داده شده و ادعا میشه که یکی از بهترین مدلهای موجود در این حوزه است. در ادامه، سعی میکنم به زبانی ساده و روان، قابلیتهای این مدل رو توضیح بدم. لینک معرفی مدل رو هم در انتهای مطلب قرار دادم.
Zonos: یک مدل پیشرفته برای سنتز گفتار
مدلهای TTS طی سالهای اخیر پیشرفت زیادی داشتن و مدلهایی مثل Coqui TTS، VITS، FastSpeech، OpenVoice و غیره تلاش کردن علاوه بر تولید صدای طبیعی، ویژگیهایی مثل کنترل لحن و احساسات رو هم بهبود بدن. حالا Zonos معرفی شده که طبق ادعای توسعهدهندهها، پیشرفتهترین مدل در این حوزه است.
یکی از مهمترین قابلیتهای Zonos ویس کلونینگ (Voice Cloning) هست. یعنی میتونید با ۵ تا ۳۰ ثانیه نمونه صوتی از یک گوینده، مدل رو طوری تنظیم کنید که همون صدای ورودی رو برای خواندن متنهای مختلف استفاده کنه. این ویژگی توی مدلهای دیگه هم دیده شده، اما به نظر میرسه که Zonos دقت بالاتری داره.
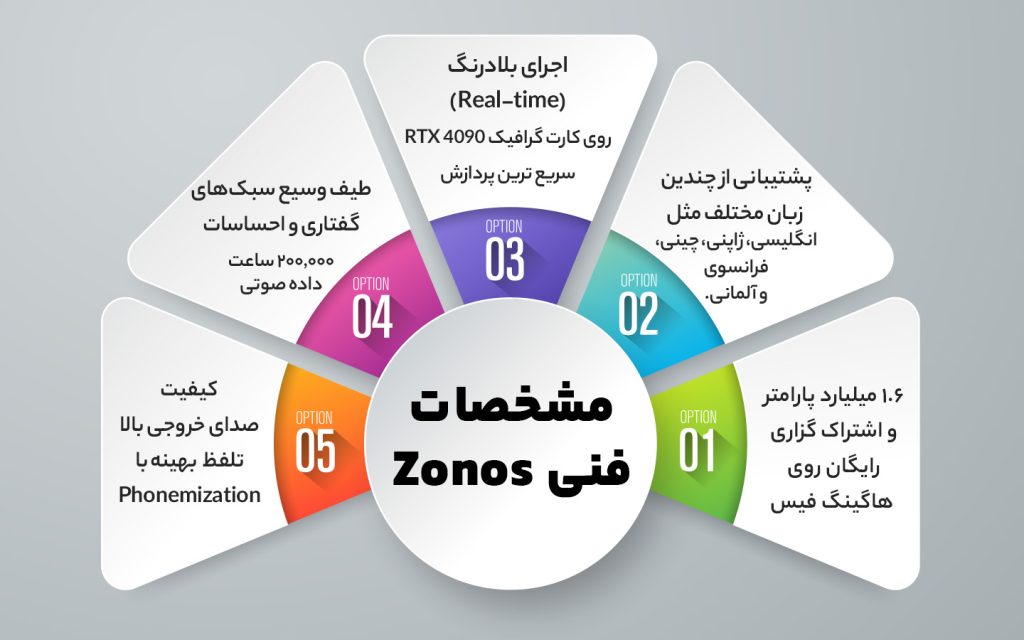
مشخصات فنی Zonos
- این مدل حدود ۱.۶ میلیارد پارامتر داره و روی هاگینگ فیس (Hugging Face) بهصورت رایگان منتشر شده، پس هر کسی میتونه ازش استفاده کنه.
- از چندین زبان مختلف پشتیبانی میکنه، از جمله انگلیسی، ژاپنی، چینی، فرانسوی و آلمانی.
- میتونه در زمان واقعی (Real-time) اجرا بشه، ولی این بستگی به سختافزار داره. روی کارت گرافیک RTX 4090 گفته شده که یکی از سریعترین مدلهای TTS موجوده، ولی عملکردش روی پردازندههای معمولی (CPU) مشخص نیست.
- مدل با ۲۰۰,۰۰۰ ساعت داده صوتی آموزش داده شده که شامل طیف وسیعی از سبکهای گفتاری و احساسات مختلفه.
- کیفیت صدای خروجی بالاست و مدل از Phonemization استفاده میکنه تا تلفظ کلمات رو بهینهتر کنه. برای این کار، از مدل Open-Source به نام eSpeak کمک گرفته شده.
کنترل لحن و احساسات
یکی از ویژگیهای جالب Zonos اینه که میتونه لحن و احساسات مختلف رو شبیهسازی کنه. شما میتونید بر اساس ورودی صوتی یا کلیدواژههایی که به مدل میدید، احساساتی مثل خوشحالی، غم، عصبانیت، ترس و لذت رو تنظیم کنید.
مدل برای تنظیم احساسات، برخلاف برخی روشهای قدیمی، از پریفیکس صوتی استفاده میکنه. یعنی اگر یک نمونه صوتی با لحنی خاص (مثلاً زمزمه) وارد مدل بشه، خروجی هم با همون لحن تولید میشه. این باعث میشه که تقلید احساسات خیلی طبیعیتر و واقعیتر باشه.
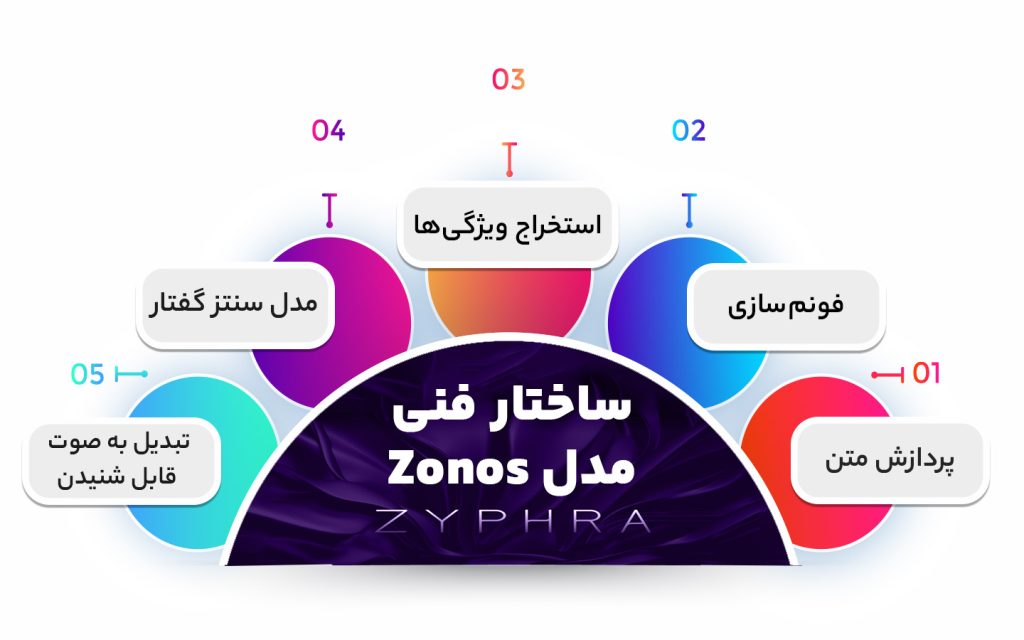
ساختار فنی مدل
Zonos برای پردازش ورودی و تولید صوت، چندین مرحله داره:
- پردازش متن (Text Preprocessing): متن ورودی استاندارد میشه. مثلاً اعداد به حروف تبدیل میشن و متن یکدست میشه.
- فونمسازی (Phonemization): متن ورودی به شکل تلفظی (فونمها) تبدیل میشه، مشابه چیزی که در دیکشنریهای انگلیسی میبینیم.
- استخراج ویژگیها:
- ویژگیهای گوینده (Speaker Embedding): مشخص میشه که صدای خروجی چه جنسی داشته باشه (مثلاً مردانه یا زنانه).
- ویژگیهای احساسی (Emotion Embedding): مشخص میکنه که گفتار چه احساسی داشته باشه.
- فرکانس صدا (Pitch): گام صدای خروجی تعیین میشه (صدای نازک یا بم).
- مدل سنتز گفتار: مدل دو مسیر پردازشی داره:
- Transformer-based: از معماری Transformer با تغییرات خاصی استفاده شده.
- Hybrid-based: علاوه بر بلاکهای Transformer، از Mamba Blocks هم استفاده شده که باعث میشه احساسات و لحن گفتار بهتر کنترل بشه.
- تبدیل به صوت قابل شنیدن: خروجی نهایی پردازش شده و به یک فایل صوتی تبدیل میشه که میتونید گوش بدید.
جمعبندی
Zonos یک مدل TTS پیشرفتهست که قابلیتهایی مثل ویس کلونینگ (تقلید صدا)، کنترل احساسات، چندزبانه بودن و سرعت بالا داره. اگر سختافزار قدرتمندی داشته باشید، میتونید خروجیهای بسیار باکیفیتی از این مدل بگیرید. از اونجایی که مدل روی Hugging Face منتشر شده، هر کسی میتونه بهصورت رایگان ازش استفاده کنه.
اینکه Zonos در مقایسه با سایر مدلهای TTS چقدر عملکرد بهتری داره، نیاز به تستهای بیشتری داره، ولی مشخصاتش نشون میده که یکی از جدیترین مدلهای این حوزهست. اگر علاقهمند به پردازش گفتار هستید، پیشنهاد میکنم که این مدل رو امتحان کنید!
لینک معرفی مدل: https://www.zyphra.com/post/beta-release-of-zonos-v0-1
نظر شما چیه؟ آیا تا حالا از مدلهای TTS مثل Zonos استفاده کردید؟







