

تابهحال برایتان پیش آمده که درباره یک ورزش جدید با دوستتان صحبت کنید یا در خلوتتان به آن فکر کنید و ناگهان اینستاگرام ویدیوها و پستهای همان ورزش را پیشنهاد دهد؟ صادقانه اعتراف کنم که این اتفاق بارها برای خودِ من افتاده است!
تحقیقات موسسههای معتبری مثل گارتنر نشان داده که نفوذ هوش مصنوعی به حریم خصوصی انسانها باعث ایجاد ترس و القای حس افسارگسیختگی شده است. حذف کامل این تکنولوژی مثل کنار گذاشتن گوشی و اینترنت غیرممکن است. پس باید ابعاد مختلف این موضوع را بشناسیم تا از دادهها و هویت آنلاینمان محافظت کنیم.
هوش مصنوعی واقعا چه چیزهایی را میداند؟
یک سوال از شما میپرسم و میخواهم اولین جوابی که به ذهنتان آمد را نگه دارید و بعد از اتمام خواندن همین مقاله، آن را در بخش نظرات بنویسید:
«هوش مصنوعی فقط ChatGPT، Gemini و دیپسیک است؟»
۳ ثانیه فرصت دارید به آن فکر کنید:
۱…
۲…
۳…
اگر جوابتان «بله» بود، سخت در اشتباهید! هوش مصنوعی در همهچیز و همهجا رخنه کرده است.
تصویر زیر را مرکز تحقیقاتی Pew در مقالهای با عنوان «آگاهی عمومی درباره حضور هوش مصنوعی در فعالیتهای روزمره» منتشر کرده است که نشان میدهد هوش مصنوعی در چه دستگاههایی وجود دارد:
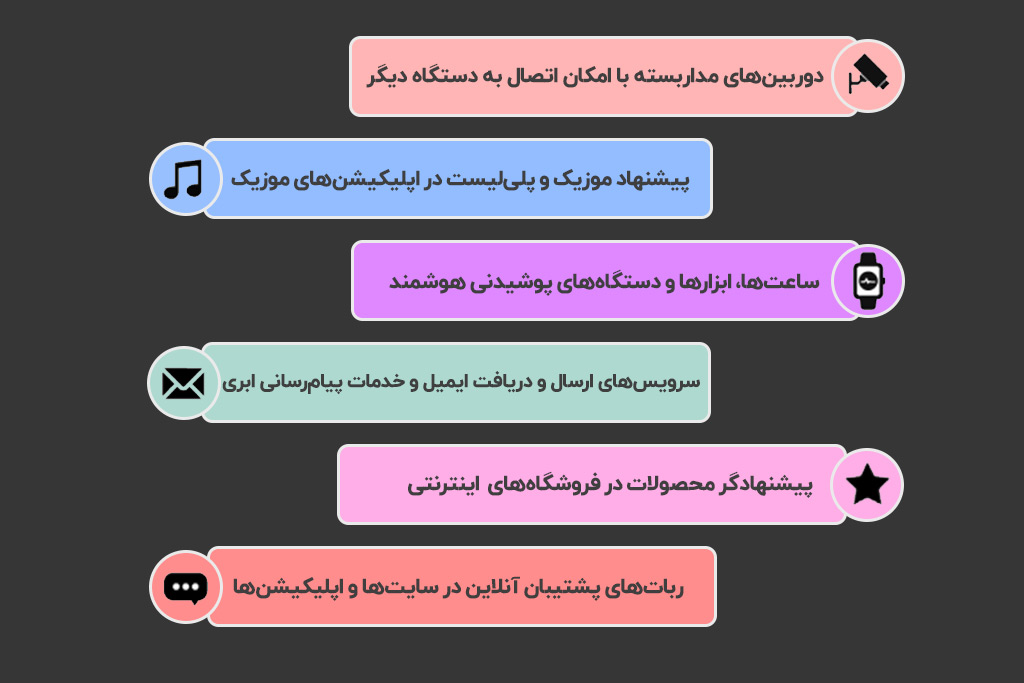
برای اینکه بدانیم هوش مصنوعی از چه چیزهایی سردرمیآورد، باید با ۳ لایه کلیدی که در دنیای آنلاین بهجا میگذاریم آشنا شویم.
لایه اول: دادههای خودآگاه
این لایه را خودمان میتوانیم کنترل کنیم و شامل اطلاعاتی میشود که بهصورت داوطلبانه منتشر میکنیم. مثلا هنگام استفاده از کامپیوتر، موبایل یا هر چیز دیگری که به اینترنت وصل است.
اطلاعات زیر همان دادههایی هستند که تقریبا از خودمان به هر سایت، پلتفرم و پیامرسانی میدهیم:
- نام کاربری
- نام واقعی
- عکس شخصی
- مخاطبان گوشی
- لایکها
- جستوجوها
- مخاطبان بلاکشده
خبر بد این است که حتی اگر بتوانید این لایه را با کارهایی مثل عدم استفاده از پلتفرم و پاک کردن تاریخچه جستوجو کنترل کنید، بازهم دو لایه دیگر وجود دارند که بدون آگاهی ساخته میشوند؛ صرفا به این دلیل که آنلاین هستید و فعالیتهای آنلاین دارید.
لایه دوم: دادههای دادههای ما
لایه دوم در پروفایل دیجیتالمان، ردپاهایی از فعالیتهایمان در اینترنت است؛ دادههایی که درباره دادههای ما جمعآوری میشوند و به متادیتا (Metadata) معروف هستند. این لایه شامل اطلاعات زیر میشود:
- سایتهایی که باز میکنیم؛
- مکان فعلیمان
- اطلاعاتی مثل سرعت تایپ، تعداد اشتباههای تایپیمان، مدت زمان مکث روی یک ریلز اینستاگرامی، مسیر حرکتی موس زیردستمان و خریدهای آنلاین
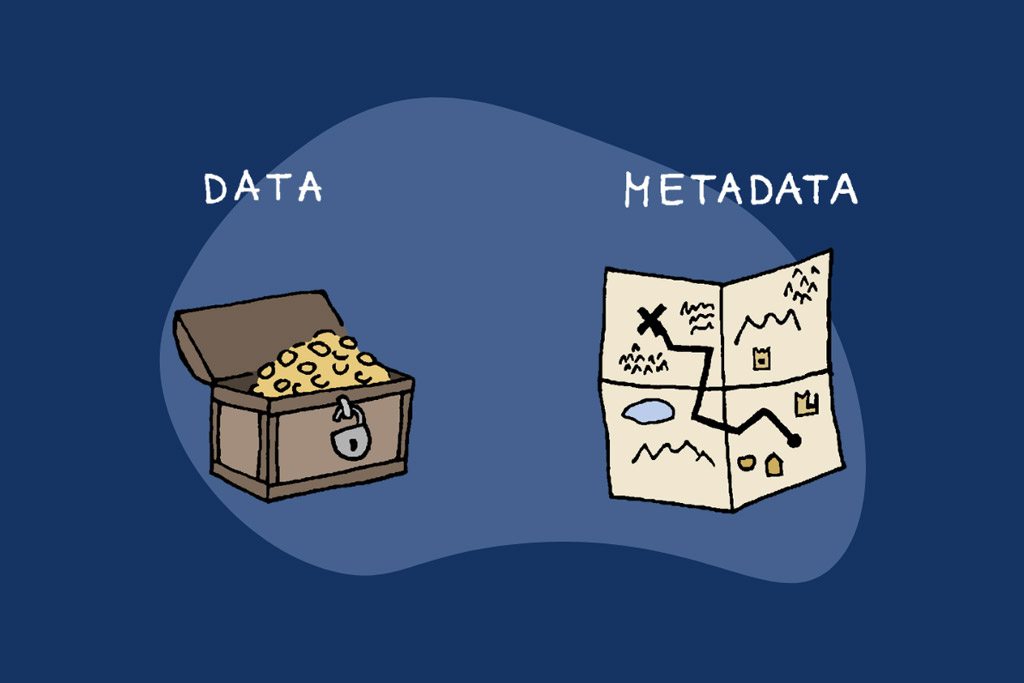
علاوهبر ۳ مورد بالا، این لایه هر نشانهای از فعالیتهای متصل ما را در خودش نگه میدارد. برای مثال اگر ساعت هوشمند به دستتان بستهاید و شب قبل فقط ۴ ساعت خوابیدهاید.
این اطلاعات در پروفایل دیجیتال فراموش و پاک نمیشوند. بنابراین جلوگیری از جمعآوری این نوع دادهها یا خارج شدن از چنین نظارت مستمر رفتاری، تقریبا غیرممکن است.
لایه سوم: دادههای استنتاجی
ترسناکترین لایه، لایه سوم است؛ چون دقیقا در همین لایه، هوش مصنوعی دادههایی که از لایههای ۱ و ۲ درباره ما جمع شده را با دادههایی که از دیگران بهدست آورده، مقایسه میکند. در نهایت نتیجه این فرآیند، شناسایی الگوهای موجود در این اطلاعات میشود.
سیستمهای هوش مصنوعی بر پایه آمار، فرضیات و پیشبینیهایی درباره ما میسازند و رفتارمان را به این شکل یاد میگیرند. درواقع آنها اطلاعاتی که از قبل درباره ما دارند را با چیزهایی که از دوستانمان یا افرادی شبیه ما جمع کردهاند، کنار هم میگذارند.
هدف AI از جمعآوری و تحلیل این دانش، رسیدن به اطلاعات هویتی و فردی مثل موارد زیر است:
- نژاد و آداب قومی
- کاندید سیاسی ایدهآلمان
- وضعیت تاهلمان
- علاقهمندیهایمان
- مبتلا بودنمان به بیماری روانی یا جسمی
اسم لایه سوم را «دادههای استنتاجی» گذاشتهاند که باارزشترین و مهمترین لایه برای شرکتهای توسعهدهنده هوش مصنوعی است. بر پایه این فرضیات و اطلاعات، شرکتهای بزرگ تصمیم میگیرند که چه تبلیغاتی نشانمان دهند و چه ویدیوهایی را از دسترسمان خارج کنند.
کنترل این ماشینها تقریبا غیرممکن است. حتی نمیتوانیم تصور کنیم این سیستمها درباره ما چه فکری میکنند و چه الگوریتمهایی برایمان ساختهاند.
هوش مصنوعی دقیقا چه چیزی را نمیداند؟
با وجود این حجم از داده و اطلاعاتی که AI از ما دارد، باید بگوییم که هنوز هم در یکسری موارد ناتوان است.
زندگی واقعی
هوش مصنوعی نمیداند وقتی چیزی را جستوجو میکنیم، به آن علاقه داریم یا صرفا یک کنجکاوی زودگذر را تجربه کردیم؟ حتی نمیداند که اطلاعاتی که از ما دارد حقیقت دارند یا نه.
اراده و شهود
هوش مصنوعی بر اساس احتمالات عمل میکند؛ درحالیکه انسانها گاهی کاملا غیرمنطقی و براساس شهود تصمیم میگیرند که هیچ الگوریتمی قادر به پیشبینی آن نیست.
بیشتر بخوانید: آیا هوش مصنوعی احساس دارد و میتواند درک کند؟
هوش مصنوعی چگونه ما را میشناسد؟
هوش مصنوعی با طی کردن ۵ مرحله زیر، میداند که ما چه علایق و سلیقهای داریم.
۱. به رفتار آنلاینمان نگاه میکند
هروقت که:
- چیزی را جستوجو میکنیم؛
- یک پست را لایک میکنیم؛
- ویدیویی میبینیم؛
- روی یک ریلز اینستاگرامی میمانیم
هوش مصنوعی همان پلتفرم این کارهای ریز ما را ضبط و آنها را به سیگنال تبدیل میکند.
مثلا اگر ۱۰ ویدیو درباره ورزش و سلامت جسم نگاه کنیم، هوش مصنوعی پیش خودش میگوید: «این فرد به موضوع سلامت اهمیت میدهد و علاقه دارد.»
۲. یک پروفایل از ما میسازد
هوش مصنوعی از تمام دادههای مرحله قبل یک پروفایل دیجیتال برایمان میسازد (که مثل شناسنامه میماند) و لیست زیر را به دادههای خام قبلی اضافه میکند:
- علایقمان
- عادتهایمان
- ترجیحاتمان
- الگوهایی مثل اینکه چه زمانی در چه پلتفرمی آنلاین میشویم یا وایفای گوشیمان را روشن میکنیم.

این سیستمهای هوشمند از اطلاعات موجود برای گروهبندی ما و افراد مشابهمان استفاده میکند که به آن بخشبندی یا Segmentation میگویند.
ما در این مرحله برای هوش مصنوعی دیگر یک فرد نیستیم؛ بلکه چنین شناسنامهای داریم:
«کاربر #7337: به تکنولوژی علاقه داره، شبها وایفای گوشیش رو روشن میکنه، مدام آنلاین خرید میکنه، به ورزش و لانجویتی علاقه داره.»
۳. انتخاب بعدیمان را پیشبینی میکند
این بخش عملکرد هوش مصنوعی، برق از سر انسان میپراند!
هوش مصنوعی فقط به کارهای قبلیمان نگاه نمیکند؛ بلکه میتواند رفتارمان را در آینده پیشبینی کند و حدس بزند که:
- روی چه گزینهای ممکن است کلیک کنیم؛
- چه چیزی را میخریم؛
- دوست داریم کدام ویدیو را ببینیم.
سیستمهای AI چنین فرآیندی را براساس الگوهایی که ما و افرادی با علایق مشابه ما در پروفایل دیجیتالمان بهجا گذاشتیم، یاد میگیرد و تکرار میکند.
این نقطه به ابتدای همین محتوا برمیگردد و پاسخ سوالمان را میدهد:
«چجوری اینستاگرام فهمید من درباره این ورزش با دوستم حرف زدم؟»
۴. از آدمهای اطرافمان چیزهای جدید یاد میگیرد
فقط ما نیستیم که در معاشرت با دیگر افراد، از آنها چیزهای جدید یاد میگیریم. هوش مصنوعی هم اینکار را انجام میدهد. این ماشین هوشمند حتی میتواند یکسری چیزها را براساس پارامترهای زیر درباره ما حدس بزند:
- دوستانمان
- همخانهمان
- افراد مشابه با ما
پس حتی اگر چیزی را جستوجو نکنیم، بازهم هوش مصنوعی میداند که چه میخواهیم و به ما پیشنهادش میدهد.
۵. خودش را مدام بهروز میکند
پروفایل دیجیتال ما ثابت نیست و مدام تغییر میکند. چگونه؟
با کارهای جدیدی که در اینترنت انجام میدهیم؛ مثلا:
- کلیکها
- جستوجوها
- رفتارها
- توقفها
بنابراین هوش مصنوعی مدام از خودش میپرسد: «آیا کاربر #7337 تغییری کرد؟»
مغز متفکر و تحلیلگر هوش مصنوعی چیست؟
برخلاف برنامههای کامپیوتری قدیمی که از دستورات مستقیم (اگر این شد، آن کار را بکن) پیروی میکردند، هوش مصنوعی مدرن بر پایه الگوها بنا شده است.
بیشتر بخوانید: هوش مصنوعی چند سال دارد و چگونه از ۱۹۵۶ تا امروز رشد کرد؟
این الگوها در طول تاریخ علوم کامپیوتر به تکامل رسیدند. بههمیندلیل رشته دانشگاهی هوش مصنوعی تلفیقی از چندین زیرشاخه آکادمیک است؛ مثل:
یادگیری ماشین
اساسیترین بخش مغز AI، علم یادگیری ماشین است که میخواهیم با یک مثال از دنیای واقعی آن را توضیح دهیم.

تصور کنید به یک کودک هزاران تصویر از گربه نشان میدهید، بدون اینکه به او بگویید «گربه چهار پا و دو گوش دارد.» کودک با دیدن تصاویر زیاد، خودش الگوی «گربه بودن» را کشف میکند.
یادگیری ماشین هم دقیقا بههمینشکل است؛ ماشین (یا همان سیستم کامپیوتری) با پردازش حجم عظیمی از دادهها، الگوها را شناسایی میکند.
مدلهای زبانی بزرگ
این مدلها (مثل چتباتهای معروف ChatGPT و Gemini) با یادگیری ماشین توسعه داده میشوند و نوع خاصی از هوش مصنوعی هستند. مدلهای زبانی بزرگ یاLarge Language Model، با هدف درک زبان انسان آموزش میبینند و از معماریهای مختلفی برای اینکار استفاده میکنند.
اساسوپایه هریک از این معماریها درک ارتباط بین کلمات در یک جمله طولانی است؛ مثلا بفهمد کلمه «آن» در انتهای جمله، به کدام اسم در ابتدای جمله برمیگردد.
بیشتر بخوانید: معماری MoE به زبون خیلی ساده
ChatGPT و ابزارهای مشابه چگونه ساخته شدند؟
تمام ابزارها و هوش مصنوعیهایی که میشناسیم (و بعضا نمیشناسیم!)، تمام فرآیندها و مراحلی که تااینجا بررسی کردیم را طی میکنند. فقط در یک نقطهای مسیرشان از سایر سیستمها (مثل سیستمهای توصیهگر در یوتیوب) جدا میشود تا به مشاور هوش مصنوعی و دستیاری برای ما تبدیل شوند.
تصور بسیاری از ما این است که ChatGPT، Gemini و هوش مصنوعی فارسی ویرا که به آنها چتبات هم میگوییم، فقط در لحظه جوابمان را میدهند. اما واقعیت این است که مکالمههای ما باAI به دو روش زیر ارزش افزوده برای هوش مصنوعی میسازند.
بیشتر بخوانید: انواع چتباتها و کاربردشان
بهبود در لحظه
در طول یک مکالمه، چتبات از همان پنجرهای که باز است (به آن پنجره متن یا Context Window میگوییم) استفاده میکند تا حرفهای قبلیمان را به یاد بیاورد و آنها را ادامه دهد. چتباتهای معروف جهان یک پنجره متن میلیونی دارند؛ یعنی میتوانند کل تاریخچه چند ماهه گفتوگوهای ما را در یک لحظه تحلیل کنند تا لحن و نیازمان را بشناسند.
آموزش دورهای
شرکتهای توسعهدهنده هوش مصنوعی مثل گوگل و OpenAI (مالک ChatGPT) از گفتوگوهای ناشناس که خودشان میسازند، با هدف آموزش مدلهایشان استفاده میکنند. یکی از این گفتوگوها همان بازخورد ما به جواب هوش مصنوعی است. این مکالمهها برای مرحلهای به نام «یادگیری تقویتی از بازخورد انسانی» بهکار میروند.
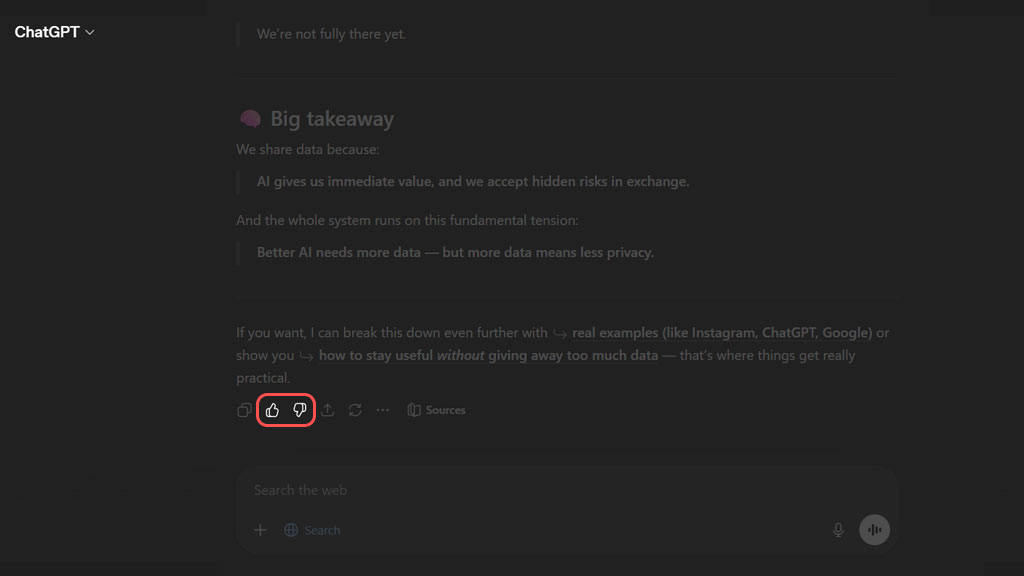
مثلا اگر به یکی از پاسخهای ChatGPT امتیاز منفی بدهیم یا جملهاش را اصلاح کنیم، این داده به سرور فرستاده میشود. در نهایت، مجموع بازخوردهای جدید در آپدیتهای بعدی ChatGPT لحاظ میشوند تا یاد بگیرد که دیگر آن اشتباه را تکرار نکند.
چرا ما داوطلبانه اطلاعاتمان را به AI میدهیم؟
پاسخ یک کلمه است: کارایی. هوش مصنوعی برای اینکه شخصیسازی شود، نیاز مکرر به بلعیدن دادههای ما دارد. ما به دو دلیل زیر، حاضریم چنین ریسکی را بپذیریم و درعوض از امکانات این سیستمها استفاده کنیم.
۱. رفاه و آسایش فردی در فضای آنلاین

درواقع ما وارد یک معامله با AI میشویم که در یک طرف آن «امنیت داده» و در طرف دیگر «رفاه دیجیتال» قرار دارد:
- ما ترجیح میدهیم اسپاتیفای یا یوتیوب دقیقا همان موزیک یا فیلمی را پیشنهاد دهند که دوست داریم؛ تا اینکه مجبور باشیم ۲۰ دقیقه جستوجو کنیم. این دقت، نتیجه مستقیم دسترسی AI به سلیقه، زمان تماشا و حتی خلقوخوی ما است؛
- استفاده از دستیارهای صوتی مثل Siri در آیفون، برای تماس گرفتن یا پخش موزیک، مستلزم این است که میکروفون گوشی همیشه در حالت آمادهباش بماند. در این موقعیت، رفاه تایپ نکردن بر ترس شنود شدن غلبه میکند؛
- وقتی از ChatGPT، Gemini یا دیپسیک میخواهیم متنی برای کپشن اینستاگرام یا مقاله بلاگ بنویسد، درواقع داریم لحن، محتوای پیام و احتمالا اطلاعاتی از خودمان و مخاطبان هدفمان را به ماشین میدهیم تا در زمان، انرژی و تمرکزمان صرفهجویی کنیم.
بیشتر بخوانید: تفاوت چت جی پی تی و دیپ سیک؛ مقایسه سرعت، هزینه و امنیت دادهها
۲. هزینه در برابر فرصت
طبق آمارهای منتشرشده در اوایل سال ۲۰۲۶، امروزه کاربران مایلند دادههای حساسشان را با هوش مصنوعی بهاشتراک بگذارند و این تمایل نسبت به دو سال گذشته، افزایش داشته است؛ مشروط بر اینکه خروجی هوش مصنوعی بهطور مستقیم در زمان آنها صرفهجویی کند.
اگر بخواهیم تحلیلی از هزینه بهخطر افتادن حریم خصوصی در برابر فرصت ایجادشده توسط AI انجام دهیم، به جدول زیر میرسیم:
| امنیتی که از دست میدهیم | رفاهی که بهدست میآوریم |
| محرمانگی مکان زندگی (GPS) | مسیریابی لحظهای و تخمین زمان رسیدن تا مقصد |
| تحلیل تاریخچه خرید و علایق | دریافت تخفیفهای شخصیسازیشده |
| ضبط الگوهای صوتی و رفتاری | تعامل طبیعی با دستیارهای صوتی و اپلیکیشنهای نصبشده روی گوشی |
| تحلیل متنها و گفتوگوهای ما با AI | دریافت جوابهای هدفمند از AI براساس چتهای قبلی و پیشبینی سلیقه شخصیمان در نوشتن و مکالمه |
آیا حریم خصوصی در برابر AI یک افسانه شده است؟
حریم خصوصی در سال ۲۰۲۶ دیگر بهمعنای پنهان کردن اطلاعات نیست (چون چنین چیزی تقریبا غیرممکن است)، بلکه بهمعنی کنترل بر نحوه استفاده از اطلاعات است. ما از عصر حق تنها ماندن به عصر حق آگاهی از پردازش داده کوچ کردهایم؛ یعنی هوش مصنوعی فقط دادههای ما را جمعآوری نمیکند، بلکه آنها را به سه روش زیر بازسازی میکند.
۱. بازشناسی هویت افراد
بسیاری از شرکتها ادعا میکنند که دادههای کاربران را ناشناسسازی یا Anonymization میکنند؛ یعنی نام و مشخصات افراد را از پایگاه داده مدلشان حذف میکنند.
اما هوش مصنوعی با قابلیتی به نام Data Stitching – که میتوانیم معنای تحتالفظی بخیه زدن دادهها را به آن نسبت دهیم – میتواند از میان میلیونها داده بینامونشان، هویت ما را پیدا کند.
درواقع، اثر انگشت دیجیتال ما از لابهلای نحوه حرکت انگشتمان روی صفحه گوشی، خرید و حتی الگوی تایپ کردنمان دیده و استخراج میشود.
۲. پروفایلهای سایه
حتی اگر آگاهانه تصمیم بگیریم که از هیچ ابزار هوش مصنوعی استفاده نکنیم و در هیچ شبکه اجتماعی عضو نشویم، باز هم AI به حضور ما پی میبرد. چگونه؟
از طریق دادههای ارتباطی. وقتی دوستان یا همکارانمان فهرست مخاطبانشان را با یک اپلیکیشن بهاشتراک میگذارند یا در چتهایشان درباره ما صحبت میکنند، هوش مصنوعی یک پروفایل سایه برایمان میسازد.
بنابراین AI بهخوبی میداند که با چه کسانی در ارتباط هستیم، به کدام مکانها رفتوآمد داریم و یکسری حدسها درباره سلیقه و ترجیحاتمان هم میزند؛ بدون اینکه حتی کلیکی کرده باشیم یا روحمان خبر داشته باشد.
۳. پیشبینیهای استنتاجی
این مورد ترسناکترین بخش افسانه بودن حریم خصوصی است. هوش مصنوعی برای دانستن اسرار ما، لزوما به دادهها نیاز ندارد.
برای مثال، یک مدل AI – که میتواند دستیار گوشی موبایل یا اپلیکیشن فیلم باشد – با تحلیل الگوی خرید مواد غذایی و تغییر در سرعت تایپ کردنمان، احتمال بروز بیماریهایی مثل دیابت یا پارکینسون را سالها قبل از تشخیص پزشک پیشبینی کند.
در سال ۲۰۲۶، الگوریتمهای پیشبینیگر بهقدری دقیق شدهاند که میتوانند تمایلات سیاسی یا وضعیت تاهل افراد را صرفا بر اساس لایک کردن چند پست غیرمرتبط تشخیص دهند.
راهکارهای محافظت از حریم خصوصی در برابر AI چیست؟
اگر حریم خصوصی را یک قلعه در نظر بگیریم، هوش مصنوعی از درِ پشتی آن وارد نمیشود؛ بلکه خودمان کلید را به آن میدهیم. بنابراین برای محافظت از دادهها در سال ۲۰۲۶، باید از محافظتهای پیشپاافتاده فراتر برویم و بهداشت دیجیتال را دریابیم.
مدیریت تنظیمات خروج
اکثر ابزارهای هوش مصنوعی مثل ChatGPT و Gemini بهصورت پیشفرض از گفتوگوهای ما برای آموزش مدلهای بعدیشان استفاده میکنند که میتوانیم با سه روش زیر، از اتفاق افتادن آن جلوگیری کنیم.
- خاموش کردن گزینه Chat History
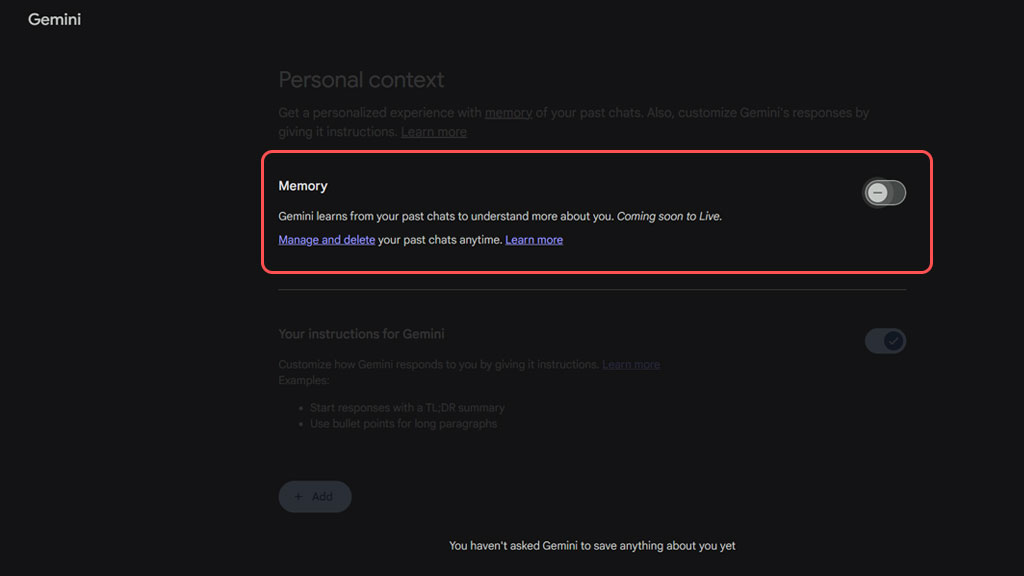
در تنظیمات (Settings) هرکدام از هوش مصنوعیها، گزینه استفاده از داده برای آموزش (Training) را غیرفعال کنید. با این کار، مکالمههایتان پس از مدتی حذف شده و در مخزن یادگیری ماشین قرار نمیگیرند.
- استفاده از حالت Temporary Chat
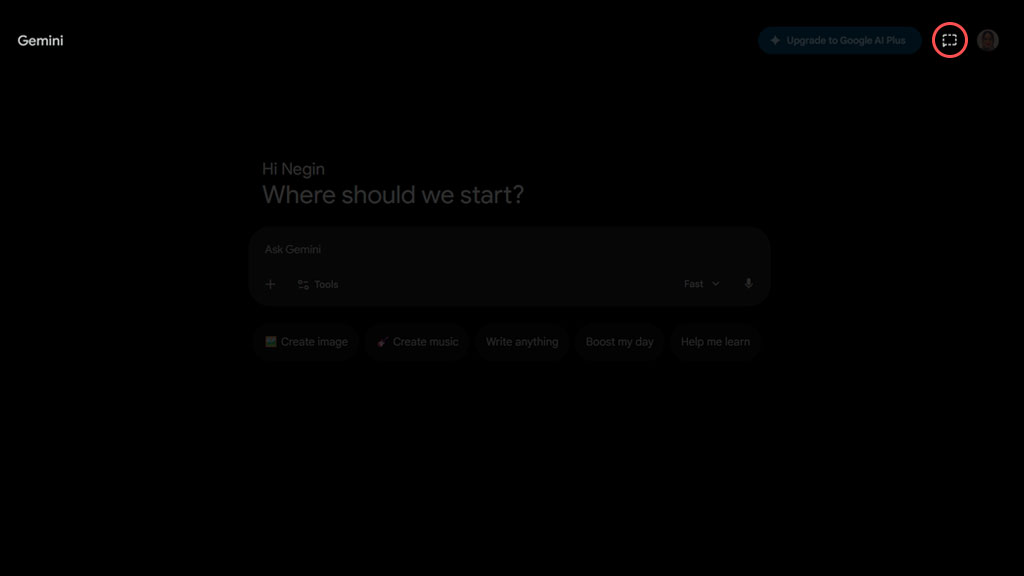
این حالت مثل Incognito در مرورگرها است که از ذخیره شدن ردپای گفتوگوهایمان با هوش مصنوعی جلوگیری میکند.
- تکنیک مخدوش کردن داده و ایجاد نویز در آن
اگر خیلی به حریم خصوصیتان حساس هستید و کمی کار با کامپیوتر را بلدید، پیشنهاد میکنیم از این روش پیشرفته استفاده کنید.
یکی از راهها، نصب افزونههای مخدوشکننده داده است که یکسری جستوجوهای تصادفی و بیربط در پسزمینه مرورگر انجام میدهند. بههمیندلیل، الگوریتمهای پیشبینیگر نمیتوانند پروفایل دقیقی از علایق واقعی ما بسازند.
راه دیگر محدودسازی دسترسیهای اپلیکیشن است که در سیستمعاملهای iOS 19 و Android 16 امکانپذیر است. به این شکل که باید دسترسی به اطلاعات حساس یا Sensitive Data را فقط به زمان استفاده از اپلیکیشن محدود و گزینه Tracking را خاموش کنید.
- نصب هوش مصنوعی روی سیستم شخصی
آخرین راه برای حفظ حریم خصوصی در برابر هوش مصنوعی، استفاده از AI محلی است که روی دستگاه خودمان نصب میشود. این سیستمها دادههایمان را به سرورهای ابری – جاییکه تمام اطلاعاتمان ذخیره میشود – نمیفرستند.
بنابراین میتوانیم برای کارهای حساس، از مدلهای متنباز مثل Llama 3 یا Mistral بهصورت آفلاین استفاده کنیم تا هیچ دادهای از دستگاهمان خارج نشود.
چگونه سواد هوش مصنوعیمان را بالا ببریم و آگاه بمانیم؟
آگاهی، مطمئنترین سپر در برابر نظارت و نقض امنیت دیجیتال است. پس برای اینکه شکار الگوریتمها نشویم باید:
- همیشه از خودمان بپرسیم این ابزار چرا رایگان است؟ اگر علتش را نمیدانستیم، به این معنی است که هزینه استفاده از آن، دادههای خودمان است؛
- استفاده از هوش مصنوعیهای معروفی مثل ChatGPT و ویرا، امنیت ما را بهخطر نمیاندازد. اما اگر خیلی محافظهکار و حساس هستیم، باید سایتها و رسانههای خبری فعال در حوزه امنیت هوش مصنوعی را دنبال کنیم؛
- بدانیم که حذف هوش مصنوعی یا ردپای دیجیتال غیرممکن است. هرکدام از ما – حتی پدربزرگ و مادربزرگهایمان – حداقل یکبار در گوگل جستوجویی انجام دادهایم. حضور فعال در شبکههای اجتماعی و استفاده از پیامرسانها که دیگر جای خود دارد. برای حفاظت از حریم خصوصیمان، رعایت همان نکات بخش «راهکارهای محافظت از حریم خصوصی در برابر AI چیست؟» کفایت میکند؛
- همیشه از ابزارهای معروف که شرکتهای مطرح پشتوانه آنها هستند استفاده کنیم و درباره ابزارهای ناشناس کنجکاوی نکنیم؛
- اگر در انتخاب هوش مصنوعی ایرانی شک داریم یا از امنیت دادههایمان در این ابزارها مطمئن نیستیم، حتما میزان رضایت کاربران، بازخورد آنها و امتیاز ابزار را در مارکتپلیسهای پراستفاده مثل بازار و مایکت چک کنیم.
چکلیست بهداشت دیجیتال در سال ۱۴۰۵
در نهایت با تمام این تفاسیر، به یک چکلیست میرسیم تا بتوانیم با پیروی از آن در عصر AI، از حریم خصوصیمان تا حد امکان نهایت حفاظت را داشته باشیم.
- هرگز اطلاعات هویتی (کد ملی، رمز عبور، آدرس محل سکونت) را در چتباتها وارد نکنید؛
- برای تست ابزارهای جدید، از ایمیلهایی غیر از ایمیل اصلیتان استفاده کنید؛
- عکس تمامقد یا پرتره از خودتان و اعضای خانوادهتان را در هوش مصنوعیهای ناشناس آپلود نکنید؛
- از مرورگرهای متمرکز بر حریم خصوصی (مثل Brave یا DuckDuckGo) استفاده کنید که ردیابهای هوش مصنوعی را بلاک میکنند و اجازه دسترسی به اطلاعات سیستم را از آنها میگیرند.
جمعبندی
هوش مصنوعی از ما اطلاعات زیادی دارد؛ اما ما را بهشکل مجموعهای از نقاط داده میبیند. اگر بخواهیم صادقانه این جمله را تفسیر کنیم، باید بگوییم که هوش مصنوعی از «منِ دیجیتالمان» تقریبا همهچیز میداند، اما از «من حقیقیمان» که پشت مانیتور نشسته، فقط سایهای را میشناسد. درست است که سیستمهای مدرن امروزی عادات، ترجیحات و الگوهای انتخابی ما را میشناسند، اما نمیدانند که چه افکاری در سرمان داریم، تمایلاتمان چیست و شخصیتمان از چه ویژگیهایی ساخته شده است. پس ریلکس باشید و از حضور و خدمات این سیستمها نهایت استفاده را ببرید.
سوالات متداولی که شما میپرسید
۱. هوش مصنوعی چگونه اطلاعات ما را جمعآوری میکند؟
با ردیابی تمام فعالیتهای آنلاینمان مثل کلیکها، سرعت تایپ، لایکها و ویدیوهایی که در شبکههای اجتماعی و سایر پلتفرمها میبینیم.
۲. چگونه از حریم خصوصیمان در کار با AI محافظت کنیم؟
گزینه Chat History ابزارها را خاموش کنید تا چتها ذخیره نشوند. همچنین میتوانید از حالت Temporary Chat استفاده کنید که همینکار را انجام میدهد. برای محافظت بیشتر از دادهها، افزونههای مخدوشکننده داده و نویزساز را روی دستگاهتان نصب و اجرا کنید.
۳. هوش مصنوعی چه چیزهایی از ما نمیداند؟
این سیستمها شخصیت واقعی، اراده و شهود ما را نمیشناسند و هر آن چیزی که میدانند صرفا دادههای خام از ردپای دیجیتال ما است. این ماشینها روی همین اطلاعات خام یکسری پیشبینی انجام میدهند و به حدس و گمان خودشان میرسند تا بتوانند در امور روزمره کمکمان کنند.





مقاله بسیار خوبی بود خانم فاتحی. موضوع جذاب و آگاهیبخشی رو به اشتراک گذاشتین. درود بر شما.