
معماری MoE با بهینه و هوشمند کردن ساختار آموزش مدلهای هوش مصنوعی، تونسته چنان کارایی خوبی از خودش نشون بده که الان توی مدلهای بزرگ و معروفی مثل GPT-4، Gemini و DeepSeek میبینیمش. این معماری باعث بالا رفتن عملکرد هوش مصنوعی میشه؛ بدون اینکه مجبور به اضافه کردن منابع پردازشی یا صرف هزینه بیشتر باشیم.
معماری MoE اومده تا دغدغه مالی و پردازشی شرکتهای توسعهدهنده AI رو کمتر کنه؛ مثل هزینه دیتاسنترها و سختافزارها که اساس و پایه این مدلها هستن و البته خیلی گرون. این ساختار در کنار تمام خوبیهایی که داره، یهسری چالش هم داره که توی این مقاله درباره همهشون صحبت خواهم کرد.
Mixture of Experts چیست؟
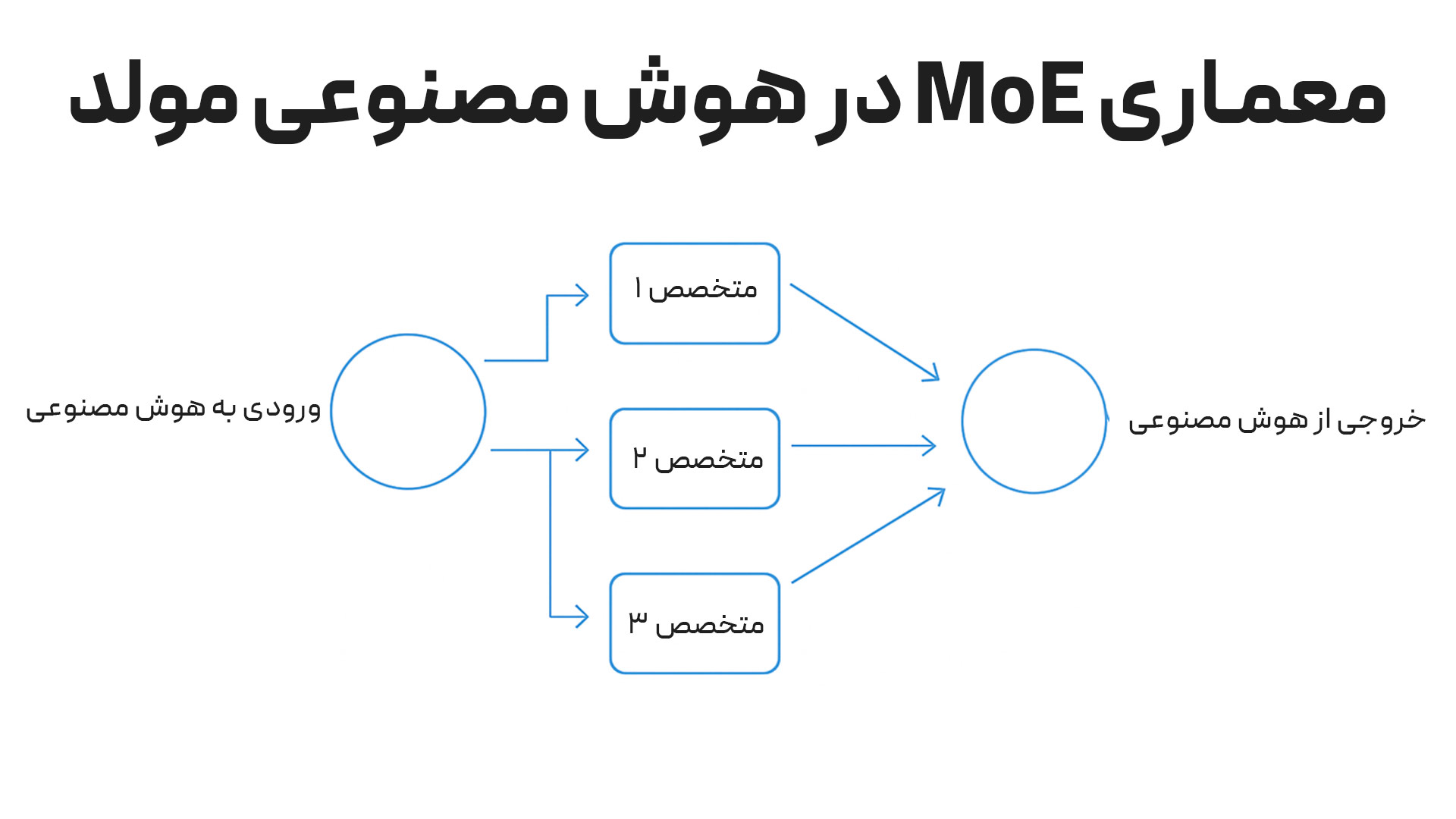
معماری MoE یه معماری یادگیری ماشین هست که از چند بخش کوچکتر برای انجام یه کار استفاده میکنه.
تصور کنین توی یه اتاق نشستین و ۱۰ نفر دیگه هم اونجا هستن. وقتی یه سوال درباره معادله ریاضی میپرسین همه جواب میدن. در این حالت کلی زمان هدر میره، توجهتون رو باید به تمام افراد بدین و در نهایت ممکنه به جوابتون نرسین.
حالا تصور کنین توی همون اتاق با ۱۰ نفر دیگه هستین. میدونین که کدوم فرد تو ریاضی قویتره. پس سوالتون رو مستقیم از اون میپرسین؛ نه کل افراد حاضر توی اتاق. به احتمال زیاد جواب درست رو هم میگیرین.
این دقیقا روش کار MoE هست. وقتی یه پرامپت مینویسیم و دکمه Enter رو میزنیم، هوش مصنوعی با معماری MoE به اجزای کوچک تقسیمش میکنه و هر بخش رو به متخصص اون کار میسپاره.
با معماری MoE مدل هوش مصنوعی مجبور نیست برای هر کار، کل پارامترهاش رو بیاره وسط و ازشون بخواد کار رو انجام بدن؛ بلکه پارامترهای خاصی رو فعال میکنه که هرکدومشون متخصصی تو یه زمینه هستن.
مثال واقعی و خیلی ساده از معماری MoE
سناریو زیر رو تصور کنین:
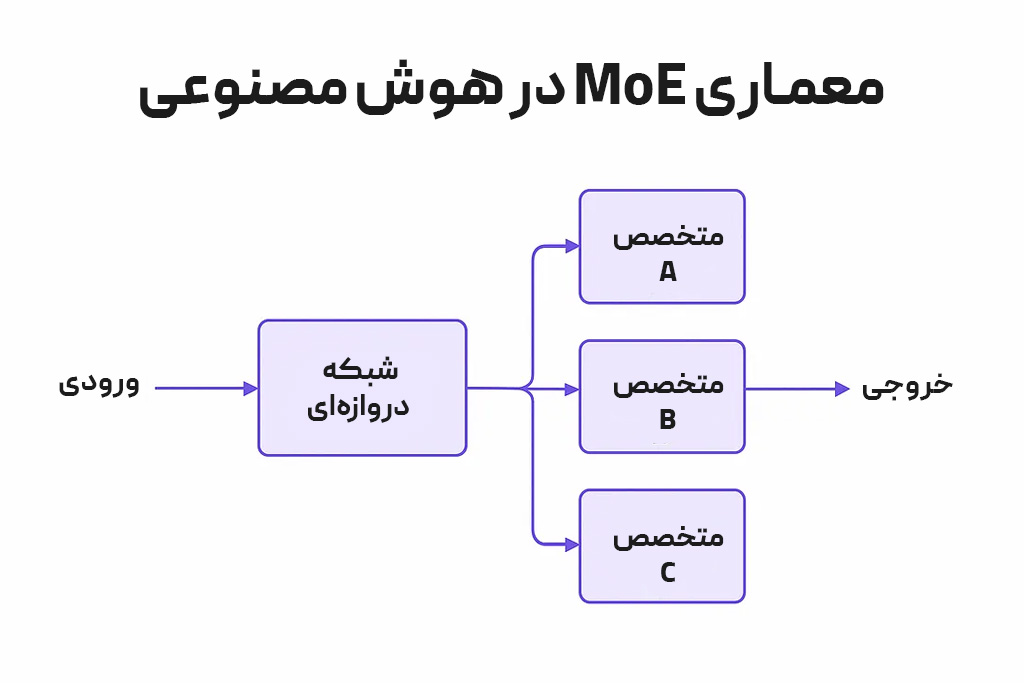
میخواین یه معلم با هوش مصنوعی بسازیم که به دانشآموزها توی درسهای مختلف کمک میکنه.
یه ابزار رو در نظر میگیریم که هرکدوم توی درسهای زیر خوب هستن:
۱. متخصص A: ریاضی
۲. متخصص B: تاریخ ایران
۳. متخصص C: دستور زبان فارسی
وقتی دانشآموز میپرسه:
«۷ × ۸ چند میشه؟»
هوش مصنوعی متخصص A (ریاضی) رو فعال میکنه.
حالا دانشآموز دیگهای میپرسه:
«اولین رئیس جمهور ایران کی بود؟»
AI متخصص B (تاریخ ایران) رو فرا میخونه.
دانشآموز سوم میپرسه:
«کدوم درسته؟ هضم یا هزم؟»
هوش مصنوعی متخصص C (دستور زبان فارسی) رو صدا میزنه تا جواب این دانشآموز رو بده.
اجزای معماری Mixture of Experts چیست؟
اول تصویر زیر رو ببینین تا مفهوم و روش کارکرد این معماری رو بهتر متوجه بشین:
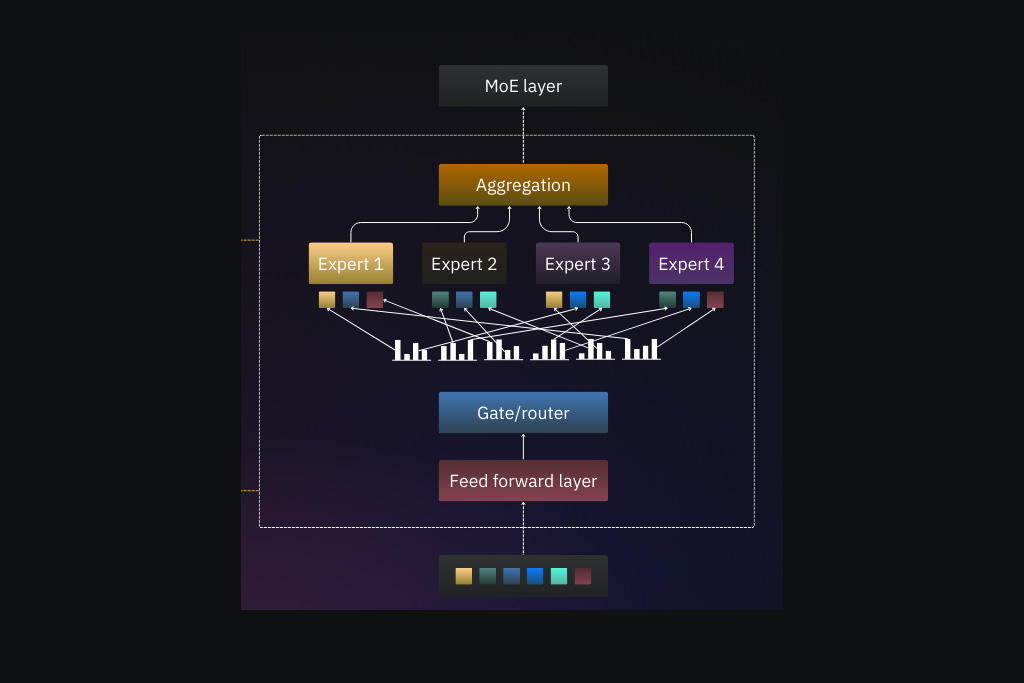
مدلهای MoE تعدادی متخصص رو انتخاب میکنن که هرکدومشون زیرشبکه خودشون رو توی یه شبکه عصبی بزرگتر دارن. این متخصصها دادهها رو پردازش میکنن و یه شبکه دروازهای (یا روتر) رو آموزش میدن. هدف از این آموزش اینهکه فقط متخصص یا متخصصهای مشخصی که برای یه ورودی معین مناسبتر هستن، فعال بشن؛ نه تمام متخصصها.
حالا بریم تا این لایهها رو باز کنیم و دقیق متوجه بشیم که معماری MoE در هوش مصنوعی چجوری کار میکنه.
متخصصها
واحد دیجیتال مارکتینگ یه شرکت رو در نظر بگیرین که از واحدهای کوچکتر مثل بازاریابی محتوا، سئو و سوشال مدیا تشکیل شده. متخصصهای معماری MoE مثل این واحدهای کوچکتر هستن که به کارشون تسلط کافی دارن.
Experts زیرشبکههای مستقل هستن که هرکدمشون توی پردازش و مدیریت یهسری از وظایف تخصص دارن. درحالحاضر این متخصصها، MLP (مخفف “Multilayer Perceptron”) هستن. MLP نوعی یادگیری عمیق از نوع پیشخور هست که برای کارهایی مثل طبقهبندی و رگرسیون استفاده میشه.
پیشخورها توی شبکه عصبی مصنوعی، اطلاعات رو توی یه جهت واحد و روبهجلو هدایت میکنن. یعنی اطلاعات رو از لایه ورودی میگیرن، از طریق لایههای پنهان میفرستن به لایه خروجی؛ بدون اینکه حلقه یا بازخوردی بین این لایهها باشه. به عبارت دیگه، خروجی یه لایه بدون هیچ چرخهای به لایه بعدی منتقل میشه.
تو شبکههای پیشخور، مدل با تنظیم وزن اتصالها از طریق فرآیندی به اسم پسانتشار، پردازش و کار روی وروردیهای مختلف رو یاد میگیره.
دروازه یا روتر
Routing Network در MoE مثل مدیری هست که تصمیم میگیره کدوم متخصص برای هر بخش از ورودی مناسبتر هست. این واحد MoE به ورودی نگاه میکنه و تشخیص میده که کدوم Expert باید روی چه چیزی کار کنه.
این بخش – که با اسم Gating Network در MoE توی علوم کامپیوتر معروف هست – یه شبکه عصبی کوچک هست که یاد میگیره دادههای ورودی رو تجزیهوتحلیل کنه و مشخص کنه که کدوم متخصصها برای مدیریت اون مناسبتر هستن.
روتر این کار رو با اختصاص دادن یه وزن (Weight) یا امتیاز اهمیت (Importance Score) به هر متخصص و بر اساس ویژگیهای ورودی انجام میده. بعد از این فرآیند، متخصصهایی که بالاترین وزن رو بهدست آوردن برای پردازش دادهها انتخاب میشن.
مسیریابی
برای اینکه مناسبترین متخصص انتخاب بشه، روتر از روشهایی برای مسیریابی و رسیدن به متخصص برتر استفاده میکنه. به این روشها میگیم الگوریتمهای مسیریابی یا “Routing Algorithms” که سه مورد از متداولترین اونها، روشهای زیر هستن:
۱. مسیریابی Top-k: این روش سادهترین روش هست. شبکه دروازهای، “k” متخصص برتر رو با بالاترین امتیاز انتخاب میکنه و دادههای ورودی رو برای اونها میفرسته.
۲. مسیریابی انتخاب متخصص: توی این روش Routing، بهجای اینکه دادهها متخصصها رو انتخاب کنن، خودِ متخصصها تصمیم میگیرن که کدوم دادهها رو میتونن به بهترین شکل مدیریت کنن. هدف این استراتژی دستیابی به بهترین تعادل بار هست تا نگاشت دادهها به متخصصها بهشکل متنوعی پیش بره.
۳. مسیریابی پراکنده: این رویکرد رو معماری Sparse Models هم میگیم که فقط چند متخصص رو برای هر قطعه داده فعال میکنه و یه شبکه پراکنده میسازه. مسیریابی پراکنده در مقایسه با مسیریابی متراکم – که همه متخصصها برای هر قطعه داده فعال میشن – از قدرت محاسباتی کمتری استفاده میکنه.
معماری MoE چجوری کار میکنه؟
ساختار Mixture of Experts برپایه دو مرحله جلو میره:
۱. مرحله آموزش
۲. مرحله استنتاج
هرکدوم از این مراحل بخشهای کوچکتری دارن که در ادامه باهاشون آشنا میشین.
مرحله آموزش
مشابه مدلهای دیگه یادگیری ماشین، شروع کار معماری MoE با آموزش روی یه مجموعه داده استارت میخوره. تنها تفاوت با معماریهایی مثل مدل ترنسفورمر اینهکه فرآیند آموزش روی کل مدل اعمال نمیشه؛ بلکه روی اجزای اون و بهصورت جداگانه انجام میشه.
آموزش متخصصها
هر جز از MoE تحت آموزش، روی یه زیرمجموعه خاص از دادهها یا وظایف قرار میگیره. هدف اینهکه این اجزا بتونن روی جنبه خاصی از یه مسئله گستردهتر تمرکز کنن.
این تمرکز با ارائه دادههای مربوط به وظیفه محولشده به هر جز ممکن میشه. مثلا برای کاری مثل پردازش زبان طبیعی و ترجمه متنها، یه جز ممکنه روی قواعد زبانی و جز دیگه روی معناشناسی تمرکز کنه.
آموزش شبکه دروازهای
وظیفه شبکه دروازهای اینهکه یاد بگیره مناسبترین متخصص رو برای یه ورودی مشخص انتخاب کنه.
توی فرآیند آموزش شبکه دروازهای، متخصصهای آموزشدیده هم حضور دارن. درواقع Gating Network در MoE همون ورودیای رو میگیره که متخصصها گرفته بودن و از این ورودی یاد میگیره که توزیع احتمال رو روی متخصصها پیشبینی کنه. این توزیع نشون میده که کدوم متخصص برای مدیریت ورودی فعلی مناسبتر هست.
آموزش مشترک
توی مرحله آموزش مشترک، کل سیستم MoE که از مدلهای خبره و شبکه دروازهای تشکیل شده، باهم آموزش داده میشن.
این استراتژی تضمین میکنه که هم شبکه دروازهای و هم متخصصها، برای یه کار واحد هماهنگ و بهینه شدن.
مرحله استنتاج
استنتاج (Inference) مرحلهای هست که خروجیها تولید میشن. این خروجی ترکیبی از عملکرد کلی شبکه دروازهای، درک اون از زمینه ورودی و جوابهای متخصصها هست.
مسیریابی ورودی
بعد از دریافت ورودی، شبکه دروازهای اون رو ارزیابی میکنه و یه توزیع احتمال رو توی تمام متخصصها میسازه. در نهایت ورودی رو به سمت مناسبترین متخصصها هدایت میکنه و از الگوهای آموختهشده در طول مرحله آموزش کمک میگیره.
انتخاب متخصص
فقط چند متخصص برای پردازش هر ورودی انتخاب میشن. این انتخاب هم توسط شبکه دروازهای، براساس احتمالات اختصاص دادهشده به هر Expert انجام میشه.
انتخاب تعداد محدودی از متخصصها برای هر ورودی، اجازه میده که هوش مصنوعی با معماری MoE از منابع محاسباتی بهصورت بهینهای استفاده کنه و درعینحال، از دانش عمیق هر Expert سود میبره.
ترکیب خروجی
آخرین مرحله توی فرآیند استنتاج، ادغام خروجی متخصصهای منتخب هست. معمولا برای ترکیب خروجیها، Gating Network در MoE از یه روش میانگینگیری استفاده میکنه. میانگینگیری نشون میده که شبکه دروازهای به هر Expert چهقدر اهمیت داده و خروجی اون رو معتبر میدونه.
البته توی سناریوهای خاص، روشهای جایگزین مثل رایگیری یا تکنیکهای ترکیبی آموختهشده برای ادغام خروجیهای Experts بهکار میره.
مزایای معماری Mixture of Experts چیست؟
مزیت اصلی رویکرد MoE اینهکه با اعمال پراکندگی ورودی روی شبکه متخصصها بهجای فعال کردن کل شبکه عصبی، ظرفیت مدل رو بالا میبره و هزینههای محاسباتی رو ثابت نگه میداره.
افزایش عملکرد
ساختار Mixture of Experts جوریه که بهشکل گزینشی پیش میره. یعنی فقط متخصصهای مرتبط رو برای یه کار مشخص فعال میکنه. بنابراین محاسبات غیرضروری انجام نمیشه و سرعت مدل AI بالا میره. در کنار این مزایا، مصرف منابع پردازشی هم کمتر میشه.
انعطافپذیری در برابر کارهای مختلف
همونطور که توضیح دادم، متخصصها بهصورت جداگونه آموزش داده میشن. پس میشه گفت که هر متخصص کارش رو بهخوبی یاد میگیره و باعث میشه که انعطاف مدل MoE خیلی بالا بره.
در واقع اتفاقی که میافته اینهکه با هر ورودی، شبکه دروازهای Expertهایی با قابلیتهای خاص رو صدا میزنن. نتیجه میشه موفقیت مدل MoE توی طیف وسیعی از وظایف.
تحمل بالای خطا
رویکرد تقسیم و حل (Divide and Conquer) معماری MoE در مدلهای زبانی بزرگ، روشی هست که توی اون وظایف بهشکل جداگونه اجرا میشن. بنابراین انعطافپذیری مدل در برابر شکستها افزایش پیدا میکنه و اگر یه متخصص با مشکلی مواجه بشه، روی عملکرد کل مدل تاثیر نمیذاره.
مقیاسپذیری گسترده
تجزیه مشکلات پیچیده به وظایف کوچکتر و قابل مدیریتتر، به مدلهای MoE کمک میکنه تا ورودیهای پیچیدهتر رو بهراحتی مدیریت کنن. در آینده هم اگر شرکتهای توسعهدهنده AI بخوان این معماری رو بهینهتر و پیشرفتهتر کنن، کافیه برای آموزش دقیقتر این متخصصها وقت بذارن؛ نه روی کل معماری.
معایب معماری MoE چیست؟
معماری MoE در هوش مصنوعی برای سناریوهایی که به توان عملیاتی بالا و متشکل از چندین ماشین نیاز دارن، عملکرد خوبی ارائه میدن. بااینحال، مدلهای پراکنده برای اینکه کارشون رو خوب انجام بدن به حافظه زیادی نیاز دارن؛ چون همه متخصصهای این معماری باید توی حافظه ذخیره بشن. این چالش یه محدودیت جدی توی سیستمهایی با VRAM کم هست.
معایب MoE موارد دیگهای هم هستن که در ادامه اونها رو توضیح میدم.
پیچیدگی آموزش
آموزش مدلهای MoE پیچیدهتر از آموزش یه مدل واحد هست. دلیل این پیچیدگی موارد زیر هستن.
سختی در هماهنگی شبکهها
توی معماری MoE به یه شبکه دروازهای واحد نیاز هست تا یاد بگیره چجوری ورودیها رو بهشکل درستی به سمت متخصصهای مناسب هدایت کنه؛ درحالیکه هر متخصص به زمینهها و دادههای مختلف تسلط کافی داره. متعادل کردن این موضوع گاهی سخت و پرهزینه میشه.
بهینهسازی کند
تابع زیانی که تو مرحله آموزش مشترک بهکار میره، باید عملکرد متخصصها و شبکه دروازهای رو متعادل کنه. این موضوع فرآیند بهینهسازی مدل رو پیچیده میکنه و باعث میشه که در طولانی مدت، امکان عیبیابی بخشهای مدل زمان زیادی ببره.
چالش در تنظیم ابرپارامتر
مدلهای MoE ابرپارامترهای (Hyperparameter) بیشتری دارن. مثلا دوتا از این ابرپارامترها تعداد متخصصها و معماری شبکه دروازهای هستن. تنظیم درست و اصولی این ابرپارامترها زمانبر و پیچیده هست.
کارایی استنتاج
استنتاج توی معماری MoE به عوامل زیر بستگی داره که در مجموع باعث افت کارایی مدل میشن.
محاسبات اضافی توسط شبکه دروازهای
ازاونجاییکه شبکه دروازهای باید برای هر ورودی اجرا بشه تا متخصصهای مناسب رو مشخص کنه، محاسبات اضافی و بعضا غیرضروری روی دوش منابع پردازشی میافته.
فرآیند زمانبر انتخاب و فعالسازی متخصص
درسته که برای هر ورودی فقط زیرمجموعهای از متخصصها فعال میشه، اما انتخاب و فعالسازی اونها معادل سربار اضافی روی منابع هستن که زمان استنتاج رو بیجهت بالا میبرن.
موازیسازی پرچالش
اجرای چندین متخصص بهصورت موازی چالشبرانگیزه؛ بهخصوص توی محیطهایی که منابع محاسباتی محدودی دارن. موازیسازی موثر نیاز به برنامهریزی کاملا اصولی و مدیریت درست منابع داره.
افزایش اندازه مدل
مدلهای MoE از چندین Expert تشکیل شدن و معمولا بزرگتر از مدلهای تکی هستن. چالشهای این ویژگی که مزیتش بود رو در ادامه میخونین.
نیاز به فضای ذخیرهسازی بیشتر
ذخیره چندین شبکه متخصص و شبکه دروازهای، نیاز کلی به منابع ذخیرهسازی رو افزایش میده. اگر محیطی محدودیت ذخیرهسازی داشته باشه، نمیتونه از این معماری استفاده کنه.
استفاده بیشازحد از حافظه
آموزش و استنتاج مدل Mixture of Experts به حافظه بیشتری نیاز داره؛ چون چندین Expert باید همزمان توی حافظه بارگذاری و نگهداری بشن.
هزینه بسیار زیاد برای استقرار معماری
استقرار مدلهایی که از معماری MoE استفاده میکنن، دشوارتر از مدلهای تکی هست؛ چراکه MoE به فضای ذخیرهسازی، سختافزارهای قوی و بیشتری نیاز داره.
راهکارهای گوگل برای حل چالشهای MoE
توی سیستمهای MoE یه چالشی هست که باعث میشه عملکرد مدل به مرور زمان افت کنه؛ چون تعادل مناسبی برای استفاده از شبکه Expert وجود نداره و اینجوری یهسری از متخصصها به زمینه خودشون مسلط میشن و یهسریهای دیگه بلااستفاده میمونن. این چالش توی زمان طولانی کارایی و تعمیم کلی مدل رو کاهش میده.
مقاله GShard گوگل
برای حل این چالش، سال ۲۰۲۰ گوگل مقالهای با عنوان “GShard” ارائه کرد که نشون میداد این رویکرد، مسیریابی کارآمد و متعادل رو بین متخصصها تضمین میکنه.
- مسیریابی بهشکل تصادفی انجام بشه؛ طوریکه متخصص دوم بهصورت نیمهتصادفی انتخاب بشه تا بیشبرازش قطعی بهوجود نیاد.
- روی ظرفیت هر متخصص محدودیت مشخصی اعمال بشه؛ یعنی تعداد توکنهایی که هر متخصص برای حفظ تعادل شبکه پردازش میکنه، محدود بشه.
مقاله Switch Transformers گوگل برای حل چالش Routing در MoE
رویکرد کلاسیک مسیریابی MoE (که آقای Noam Shazeer و همکاران ارائه داده بودن)، از یه سیستم Top-k که برپایه تابع Softmax بود استفاده میکرد.
روش Top-K اینطوریه که برای هر ورودی، شبکه گیت پیشبینی میکنه که کدوم Experts مناسبترین انتخاب هستن و فقط k متخصص برتر از بین اونها رو فعال میکنه.
مثلا Mixtral از مسیریابی top-2 (k=2) استفاده میکنه؛ یعنی فقط ۲ متخصص از ۸ متخصص موجود برای هر ورودی انتخاب میشه.
مقاله Switch Transformers (Fedus و همکاران، سال ۲۰۲۱) گفت که مسیریابی سخت (k=1) میتونه عملکرد بهتری ارائه بده. به این صورت که فقط بهترین متخصص برای هر توکن فعال میشه.
گوگل توی این مقاله گفت: «برای حل چالش انتخاب Expertهای یکسان برای هر ورودی، میشه از تعدادی مکانیسم دروازهای استفاده کرد؛ چون عملکرد Routing Network برای کارایی بهینه مدل خیلی مهمه. اگه استراتژی مسیریابی ضعیف باشه، آموزش ناکافی یا حضور بیشازحد یه متخصص برای هر ورودی باعث میشن که اثربخشی کل شبکه افت کنه.»
این راهکار خیلی ساده هست؛ اما مقیاسپذیری گسترده و عملکرد خیرهکنندهای رو به مدلها میده.
جالبه بدونین که گوگل این روش رو روی مدل T5 خودش پیاده کرد. به این شکل که اومد لایههای استاندارد پیشخور رو با ۱۲۸ متخصص جایگزین کرد و از مسیریابی پراکنده استفاده کرد.
نتیجه؟
تونستن مقیاس این مدل رو به یک تریلیون پارامتر افزایش بدن و سرعت آموزش اون رو تا ۴۰۰ درصد سریعتر کنن.
کدوم هوش مصنوعیها از MoE استفاده میکنن؟
مدلهای معروفی مثل Gemini 1.5 و GPT-4 از ساختار Mixture of Experts استفاده میکنن؛ اما گوگل و OpenAI اطلاعاتی درباره تعداد کل پارامترها فاش نکردن؛ ولی یهسری منابع براساس حدسیات گفتن که GPT-4 از ۱.۷ تا ۱.۸ تریلیون پارامتر استفاده میکنه.
ولی شرکتهای سازنده مدلهای زیر، با شفافیت اعلام کردن که این معماریشون از چه تعداد پارامتر بهره میبره.
LLaMA 4
مدلهای LLaMA 4 متا که هوش مصنوعی متن به عکس و متن به متن هستن، بهطور گستردهای از MoE استفاده میکنن:
- LLaMA 4 Scout که از ۱۶ متخصص استفاده میکنه که توی هر ورودی، حداکثر دوتای اونها توی یه زمان فعال میشن؛
- LLaMA 4 Maverick که از ۱۲۸ متخصص استفاده میکنه و همچنان دوتای اونها بهطور همزمان میتونن کار کنن.
DeepSeek R1
DeepSeek یه هوش مصنوعی چینی هست که ۱۲۸ Expert داره. تعداد کل پارامترهای دیپ سیک ۶۷۱ میلیارد هست؛ اما در طول استنتاج فقط ۳۷ میلیارد اونها فعال میشن.
مقایسه پارامترهای کلی و پارامترهای فعال در مدلهای MoE
به جدول زیر دقت کنین. توی این جدول به وضوح میبینیم که مدلهای مبتنی بر MoE چند پارامتر دارن و چندتا رو در طول استنتاج فعال میکنن:
| مدل | تعداد کل پارامترها | تعداد پارامترهای فعال در طول استنتاج |
| DeepSeek MoE 145B | ۱۴۴.۶ میلیارد | ۲۲.۲ میلیارد |
| Mixtral | ۴۷ میلیارد | ۱۳ میلیارد |
معماری MoE خوبه؛ اما
MoE در مدلهای زبانی بزرگ یه معماری قوی هست که میتونه هوش مصنوعیهای آینده رو کارآمد و تخصصیتر از نسخههای فعلیشون کنه؛ اما این معماری فعلا فقط محدود به مدلهای بزرگ مثل LLaMA، Gemini 2.5 و GPT-4 شده و دلیلش هم واضحه: منابع پردازشی زیادی میخواد و به حافظههای عظیم متکیه. یهسری منابع گفتن که با چه شرایطی میشه این چالشها رو برطرف کرد. اگر این راهکارها پیاده بشن، معایب MoE برطرف میشه و به مرور شاهد سیستمهای قویتر و دقیقتری خواهیم بود.
سوالات متداولی که شما میپرسین
یه معماری که بعد از مدل ترنسفورمر اومد و با استفاده از شبکهای از متخصصها، سعی میکنه هر ورودی رو به بخشهای کوچکتر تقسیم کنه و بسپاره به متخصصها.
متخصصها، دروازه یا روتر و شیوه مسیریابی.
سختی در هماهنگی شبکهها، محاسبات اضافی توسط شبکه دروازهای، نیاز به فضای ذخیرهسازی بیشتر و استفاده بیشازحد از حافظه چالشهای فعلی MoE هستن.





شبکه MoEمعرفی شده که یک شبکه دروازه بان است ،نحوه پردازش در لایه های پنهان و پردازش به صورت تخصصی در بلوک های مجزا به این طریق امکان پذیر نبوده و متاسفانه برخی کارشناسان هم این نوع پردازش را تأیید میکنند.نادرملکی ،مخترع شبکه نورومورفیک دونیمکره ای
باسلام ،مدل معرفی شده شرکت گوگل MoEکپی برداری از اختراع اینجانب به نام شبکه نورومورفیک دو نیمکره ای به شماره PCT/IR2025/050026اختراع بنده پردازش مجزا ،هماهنگ، همزمان و خروجی یکپارچه است .در مدل گوگل که دور زدن اختراع را شامل میشود،در فلوچارت ورودی را به سه بخش متخصص تقسیم بندی میکند، و خروجی یکپارچه ارائه میدهد،جالبه که همچین چیزی امکان ندارد،از نظر علمی