هوش مصنوعی در سالهای اخیر، بیشترین پیشرفت را به خود دیده است. این پیشرفت در زمان کم رخ داد و حالا هر روز شاهد اخبار جدید و بهروزرسانیهای متعدد هستیم. علیرغم تمام این پیشرفتها، یک مشکل همچنان پابرجا مانده است: هوش مصنوعی هنوز نمیتواند بهصورت مداوم از دادهها یاد بگیرد و آنها را فراموش نکند.
این مشکل را گوگل با رویکرد Hope در یادگیری ماشین حل کرده است. رویکردی که بعضی از کارشناسان میگویند مسیر رسیدن به AGI را هموار میکند و این تکنولوژی را به سرزمین جدیدی میبرد. بیایید با جزئیات این رویکرد بیشتر آشنا شویم و به دل آن برویم.
مشکل از کجا شروع شد؟
در یک دهه گذشته، مدلهای AI پیشرفتهای باورنکردنی در یادگیری ماشین (ML) به خود دیدند. این پیشرفتها بهلطف معماریهای قدرتمند شبکه عصبی و الگوریتمهای مورد استفاده برای آموزش مدلها رقم خوردهاند.
بااینحال، علیرغم موفقیت مدلهای زبانی بزرگ (LLM)، چند چالش اساسی همچنان پابرجا مانده است که دو مورد از برجستهترین آنها یادگیری مداوم، توانایی مدل برای کسب فعال دانش و مهارتهای جدید است؛ بدون آنکه این دانش در طول زمان محو شود و دانشهای قبلی به فراموشی سپرده شوند.
همانطور که میدانید، هوش مصنوعی شبیهسازی از هوش انسان است. پس میتوان برای دستیابی به رویکردی جدید و بهینه کردن عملکرد مدلها، از فرآیند یادگیری و تصمیمگیری مغز انسان الگو گرفت.
مغز ما میتواند با دادههای جدید سازگار شود و مسیرهای عصبی تازهای برای آنها بسازد. درواقع مغزمان با تکیه بر انعطافپذیری شناختی و عصبی خود، میتواند دانش جدید را بدون حذف قبلیها یاد بگیرد و در عمل آنها را پیاده کند.
بدون این توانایی، ما به زمینه فوری (مثل فراموشی پیشرونده) محدود میشویم که درحالحاضر LLMها درگیر آن هستند؛ به این معنی که دانش آنها به دو چیز محدود میشود:
۱. زمینه فوری پنجره ورودی
۲. اطلاعات استاتیکی که در طول فرآیند پیش آموزش یاد گرفتند.
رویکرد ساده برای حل مشکل فراموشی فاجعهبار
در حوزه هوش مصنوعی اصطلاحی با عنوان “Catastrophic Forgetting” داریم که در فارسی آن را «فراموشی فاجعهبار» ترجمه میکنیم.
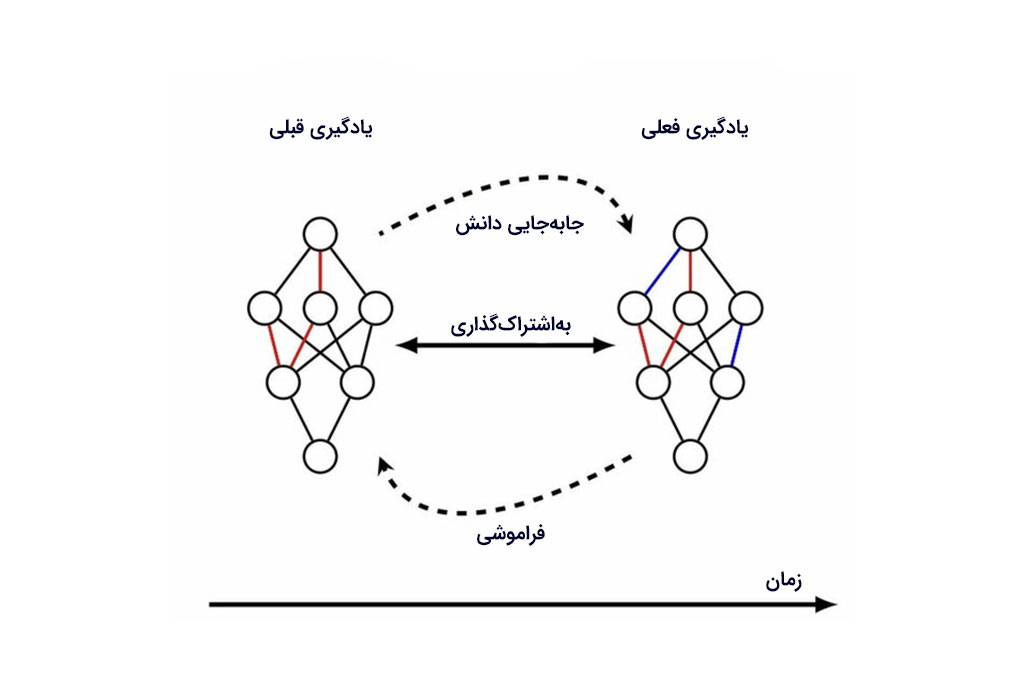
CF جایی است که مدل وظایف جدید را یاد میگیرد، اما مهارتش در انجام دادن وظایف قدیمی یا خیلی کمرنگ میشود، یا کاملا فراموش میشود. محققان یک روش ساده برای حل این چالش اجرا میکردند. آنها از ترفندهای معماری شبکه یا قوانین بهینهسازی بهتر بهره میبردند تا مدل از حداکثر تواناییاش برای یادگیری پارامترهای جدید استفاده کند.
گوگل چگونه به رویکرد Hope رسید؟
گوگل در وبسایت رسمی Research خود بهصورت واضح اعلام کرد که مدتهاست معماری مدل (ساختار شبکه) و الگوریتم بهینهسازی (قانون آموزش) را دو چیز جداگانه در نظر میگیرد. این غول فناوری معتقد است که دو فناوری موجود، مانع دستیابی به یک سیستم یادگیری یکپارچه و کارآمد میشود.
این نگرش متفاوت گوگل باعث تحقیق و ایجاد روش جدیدی شد که در مقالهای با عنوان “Nested Learning: The Illusion of Deep Learning Architectures”، مورد بحث قرار گرفت و در کنفرانس سالانه NeurIPS 2025 ارائه شد.
گوگل میگوید که Nested Learning یادگیری تودرتو است و به مدل کمک میکند تا ورودی را یک سیستم چندوجهی ببیند؛ یعنی ورودی یک فرآیند پیوسته و دنبالهدار نیست؛ بلکه سیستمی متشکل از دهها مسئله چند سطحی و بههم پیوسته است که مدل بهطور همزمان روی آنها کار میکند.
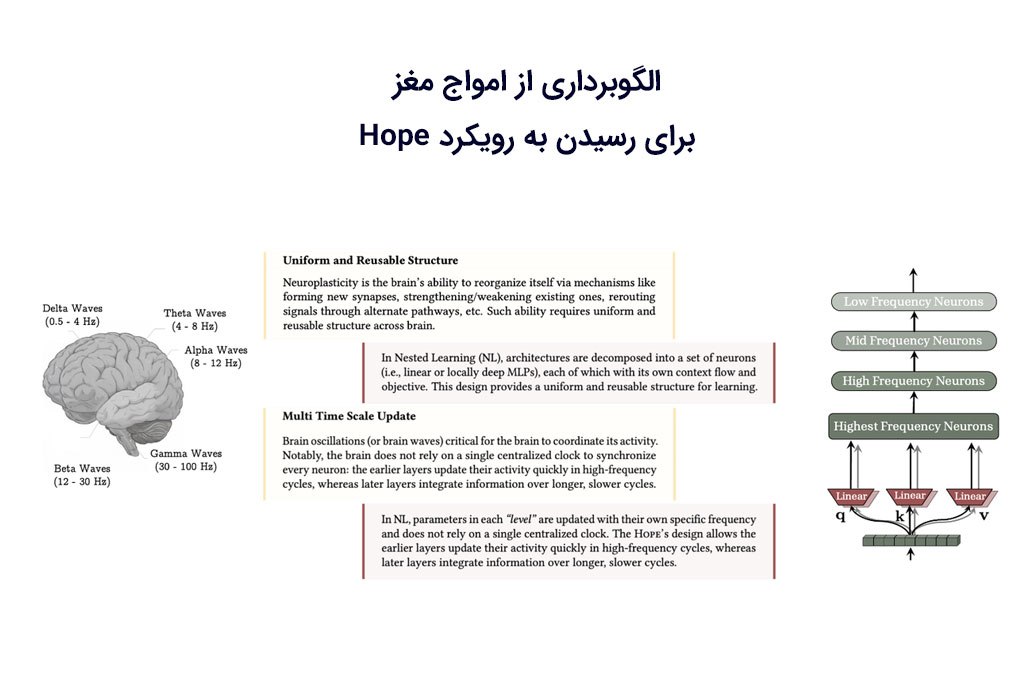
استدلال گوگل این است که معماری مدل و قوانین مورد استفاده برای آموزش آن (یعنی الگوریتم بهینهسازی) اساسا مفاهیم یکسانی هستند. از نظر این کمپانی ابرقدرتمند، الگوریتمهای بهینهسازی فقط سطوح مختلف بهینهسازی هستند که هرکدام جریان داخلی اطلاعات و نرخ بهروزرسانی خاص خود را دارند.
گوگل توانسته با تشخیص این ساختار ذاتی، یادگیری تودرتو را بسازد تا بُعد جدیدی به فرآیند طراحی هوش مصنوعی اضافه کند. با این رویکرد، متخصصان AI میتوانند اجزای یادگیری ماشین را با عمق بیشتر در محاسبات آموزش دهند.
این کمپانی پیشرو در تحقیقات AI، رویکرد Nested Learning خود را از طریق یک معماری خود-اصلاحگرِ اثبات مفهوم آزمایش و اعتبارسنجی میکند. نام این رویکرد “Hope” یا «امید» و مخفف “Hierarchical Optimizing Processing Ensemble” است.
طبق اظهار گوگل، معماری Hope در مدلسازی به سطح بالاترین عملکرد میرسد و مدیریت حافظه بلندمدت در آن نسبت به مدلهای پیشرفته موجود بهتر است.
چرا مدلهای LLM دانش قبلی خود را فراموش میکنند؟
اجازه دهید با یک مثال ساده، به شما بگوییم چگونه مدلهای LLM فعلی دانش قبلیشان را فراموش میکنند. سپس دلایل این چالش را بررسی میکنیم تا نحوه حل مسئله Hope را بهتر درک کنیم.
فرض کنید بهتازگی یک مهارت جدید را به فردی آموزش میدهید. در این فرآیند، یادگیرنده تمام چیزهایی که قبلا یاد گرفته و بلد بود را کاملا فراموش میکند. یعنی دانش جدید باعث پاک شدن دانش قبلی در حافظه او میشود.
این مشکل همان فراموشی فاجعهبار در مدلهای LLM و سایر سیستمهای هوش مصنوعی است.
یادگیری متوالی
فرآیند یادگیری دانش در مدلهای هوش مصنوعی بهشکل گامبهگام (متوالی) است. بنابراین وقتی مدل چیز جدیدی یاد میگیرد، تنظیمات داخلی – که به آنها وزن میگوییم – خود را برای تطبیق با اطلاعات جدید تغییر میدهد.
این موضوع یک مشکل بزرگ درست میکند: تغییر تنظیمات برای تطبیق با دانش جدید، تنظیمات قبلی را مختل میکند و باعث میشود مدل دادههای قدیمی را فراموش کند.
نحوه بهخاطر سپردن دادههای غیرایستا
در بسیاری از سناریوهای دنیای واقعی، توزیع دادهها با گذشت زمان تغییر میکند. وقتی یک مدل با توزیع جدیدی از دادهها مواجه میشود، معمولا یادگیری توزیع جدید را در اولویت قرار میدهد. این اولویت گذاشتن باعث فراموشی توزیع قبلی میشود.
بازنویسی حافظه
مجموعه دانش یک هوش مصنوعی در تنظیمات داخلی آن و با نام «وزن» یا “Weight” ذخیره میشود. وقتی دادههای جدید وارد دیتابیس میشوند، مدل LLM وزنهای قدیمی را بازنویسی میکند تا خطاها در کار جدید را بهحداقل برساند. این کار درست مثل ضبط یک ویدیوی جدید روی ویدیوی قدیمی و مهم است.
فقدان سیستم حافظه
برخلاف مغز انسان که روشهای پیچیده و لایهبندیشده برای ذخیره و بازیابی انواع مختلف خاطرات دارد، مدلهای استاندارد هوش مصنوعی به چنین سیستمهایی مجهز نیستند.
عدم وجود فضای کافی برای نگهداری تمام اطلاعات
اگر ظرفیت شبکه مدل کم باشد یا ساختار آن برای مدیریت همزمان چندین کار تنظیم نشده باشد، نمیتوان هم اطلاعات قدیمی و هم دانش جدید را ذخیره کرد. محدودیت فعلی LLMها مثل این است که بخواهید تعداد زیادی کتاب بزرگ را در یک قفسه کوچک جا بدهید. مسلما نمیتوانید همه کتابها را در همین قفسه جا بدهید و باید چندتای آنها را به کتابخانه دیگری ببرید.
سوگیری نسبت به دادههای اخیر
شبکههای عصبی ذاتا مایلند به جدیدترین دادههایی که براساس آنها آموزش دیدهاند، اهمیت بیشتری بدهند. این سوگیری نسبت به دادههای اخیر باعث میشود که شبکه، دانش قدیمیتر را بازنویسی کند؛ بهخصوص اگر دادههای جدید تفاوت قابل توجهی با دادههای قدیمیتر داشته باشند.
چگونه رویکرد Hope مشکل فراموشی فاجعهبار را حل میکند؟
سیستم Hope تقلیدی هوشمندانه از نوروپلاستیسیته در مغز انسان است. این اصطلاح در علوم نوروساینس رایج است و به انعطافپذیری مغز و ایجاد مسیرهای عصبی و رشدیافته جدید اشاره میکند.
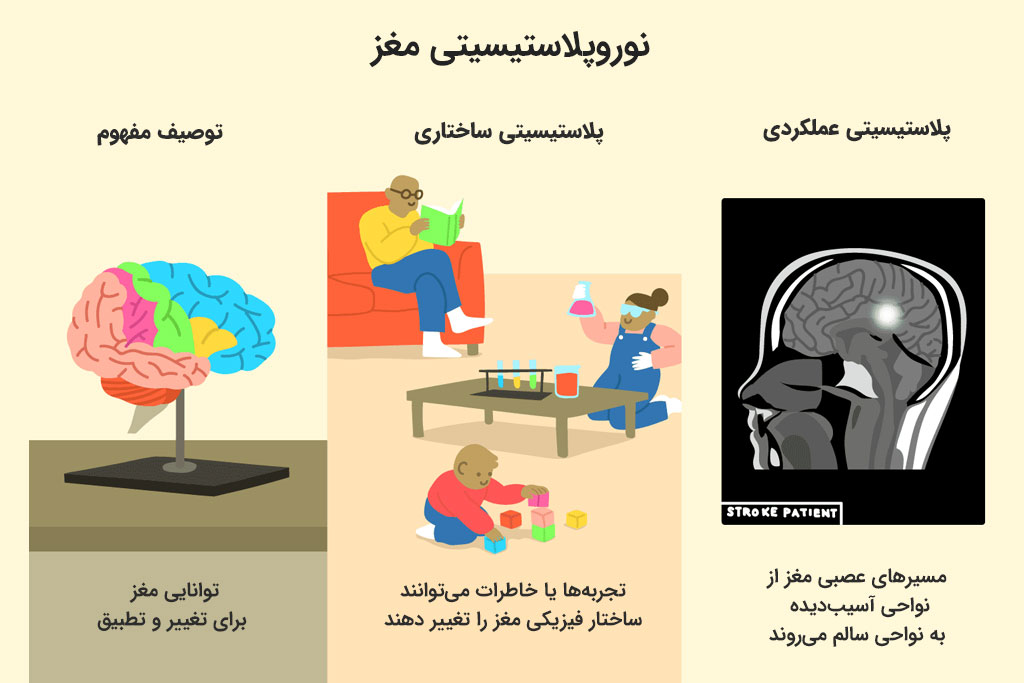
با الهام گرفتن از این انعطافپذیری، گوگل رویکرد یادگیری تودرتو در معماری Hope را معرفی کرد که در آن، کل مدل هوش مصنوعی یک سلسله مراتب از ماژولهای یادگیری بههم پیوسته است. این سلسله مراتب در مقیاس زمانی یا فرکانس منحصربهفرد خودش عمل کرده و بهروزرسانی میشود. در ادامه این بخش، جزئیات این رویکرد را بهطور مفصل توضیح میدهیم.
بهروزرسانی در چند بازه زمانی
Nested Learning معماری مدل (لایههای شبکه) و الگوریتم بهینهسازی آن (قوانین آموزشی) را در یک سیستم واحد و منسجم از مسائل بهینهسازی تودرتو متحد میکند.
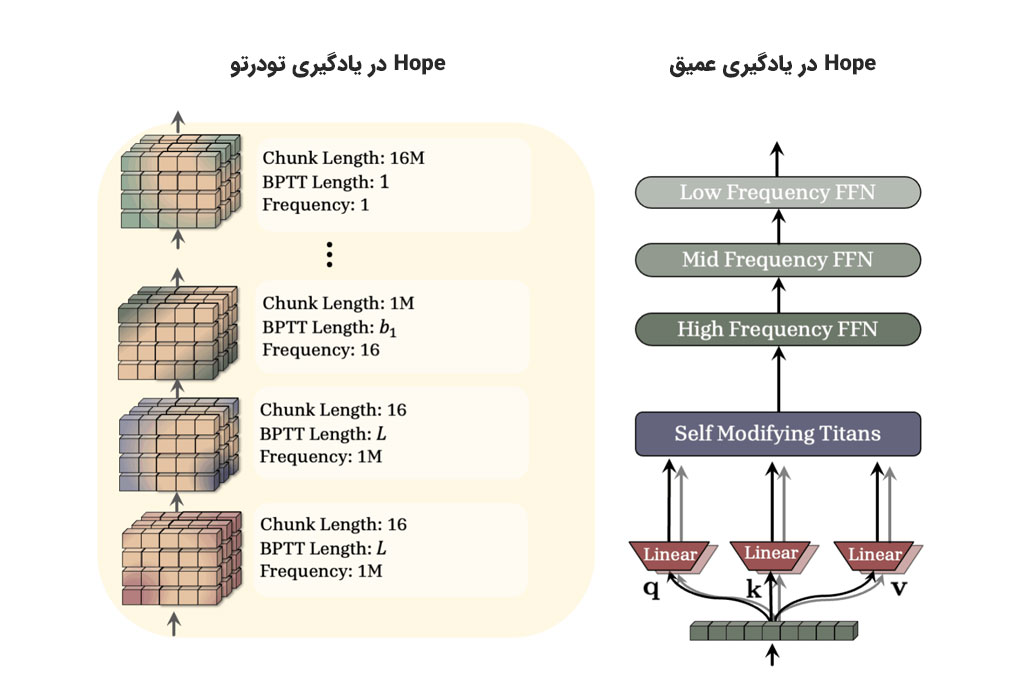
سپس در ساختار سلسله مراتبی، مدل از نظر مفهومی به سطوح یا اجزای مختلفی تقسیم میشود که روی هم انباشته شده و درعینحال به یکدیگر وصل هستند.
به هر سطح از این ساختار لایهای، یک نرخ فرکانس بهروزرسانی متمایز اختصاص داده میشود.
لایههای سریع و داخلی
ماژولهای سطحی بهصورت مکرر بهروز میشوند. مثلا هر چند مرحله یکبار یا برای هر داده ورودی جدید، این بهروزرسانی انجام میشود. این ماژولهای داخلی مسئول حافظه کوتاهمدت و سازگاری سریع هستند. نمونه آن در دنیای واقعی و تعاملات انسانی، همان یادگیری سبک مکالمه در یک جلسه کاری است که ما خیلی سریع خودمان را با آن تطبیق میدهیم.
لایههای کند و بیرونی
این ماژولها خیلی کمتر از ماژولهای سطحی بهروز میشوند و هر چند هزار مرحله، یکبار بهروزرسانی صورت میگیرد. این ماژولها مسئول حافظه بلندمدت هستند و فقط پایدارترین، ماندگارترین و بنیادیترین دانش را ذخیره میکنند؛ مثل قوانین دستور زبان یا مفاهیم اصلی یک حوزه تخصصی.
جلوگیری از فراموشی
حالا مدل میتواند سرعتهای یادگیری را جدا کند. پس بهروزرسانیهای سریع و ضروری را برای یادگیری یک کار جدید، به ماژولهای سطحی واگذار میکند.
این توزیع از تداخل یا بازنویسی وزنهای پایدار در لایههای کند جلوگیری میکند؛ لایههایی که مسئول مهارتهای بنیادی مدل هستند.
سیستم حافظه پیوسته (CMS)
Hope بهجای تقسیم ساده بین حافظه کوتاه مدت (توجه) و بلند مدت (پیشخور)، طیفی از ماژولهای حافظه به نام “Continuum Memory System” یا “CMS” را در خود جا داده است. این سیستم چندین بلوک پیشخور را به یکدیگر وصل میکند که هرکدام با فرکانس بهروزرسانی خاص و متفاوت خود پیکربندی شدهاند.
CMS سیستم حافظهای غنیتر و موثرتری برای مدلهای LLM است که میتواند اطلاعات را در بازههای زمانی مختلف مدیریت کند.
معماری خود-اصلاحکننده
این معماری، یک ساختار بهینهسازی آموختهشده است. درواقع مدلی که با هوش مصنوعی Hope ساخته میشود، به یک معماری بازگشتی مجهز است و میتواند یاد بگیرد چگونه حافظه خود را بهروزرسانی کند.
بنابراین مدل فقط به یک قانون بهینهسازی خارجی ثابت مثل Adam یا SGD متکی نیست؛ بلکه قوانین بهروزرسانی بهینه خود را در لحظه یاد میگیرد. این فرآیند خودارجاعی، توانایی بالقوه و نسبتا نامحدودی را برای یادگیری درونزمینهای امکانپذیر میکند.
ادعاهای گوگل درباره عملکرد بهینه Hope
مجدد برمیگردیم به صفحه رسمی Google Research و اینبار گفتههای گوگل درباره اثربخشی این رویکرد را بیان میکنیم.
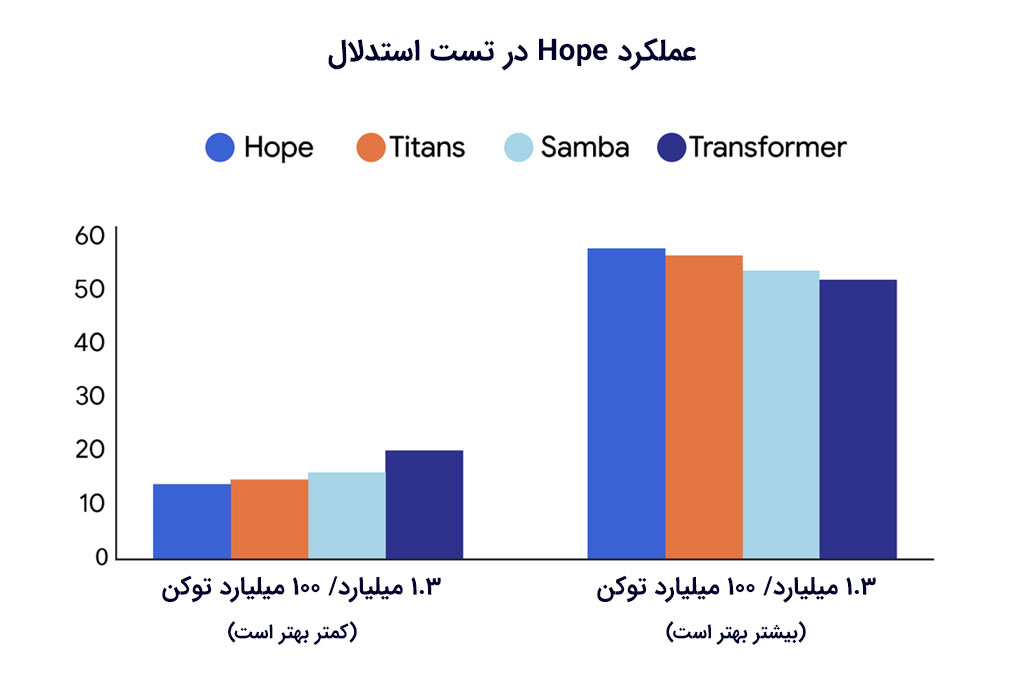
گوگل نتایج بهدستآمده در وظایف مدلسازی زبان عمومی و استدلال را با سه معماری Hope، مدلهای بازگشتی مدرن و ترانسفورماتورهای استاندارد مقایسه کرده و میگوید که هوش مصنوعی Hope پیچیدگی کمتر و دقت بالاتری داشته است.
همچنین در تست Needle-In-Haystack با ابزار هوش مصنوعی Hope، این رویکرد توانست عملکرد بهینهتری نسبت به معماریهای Titan، TTT و Mamba2 از خود نشان دهد.
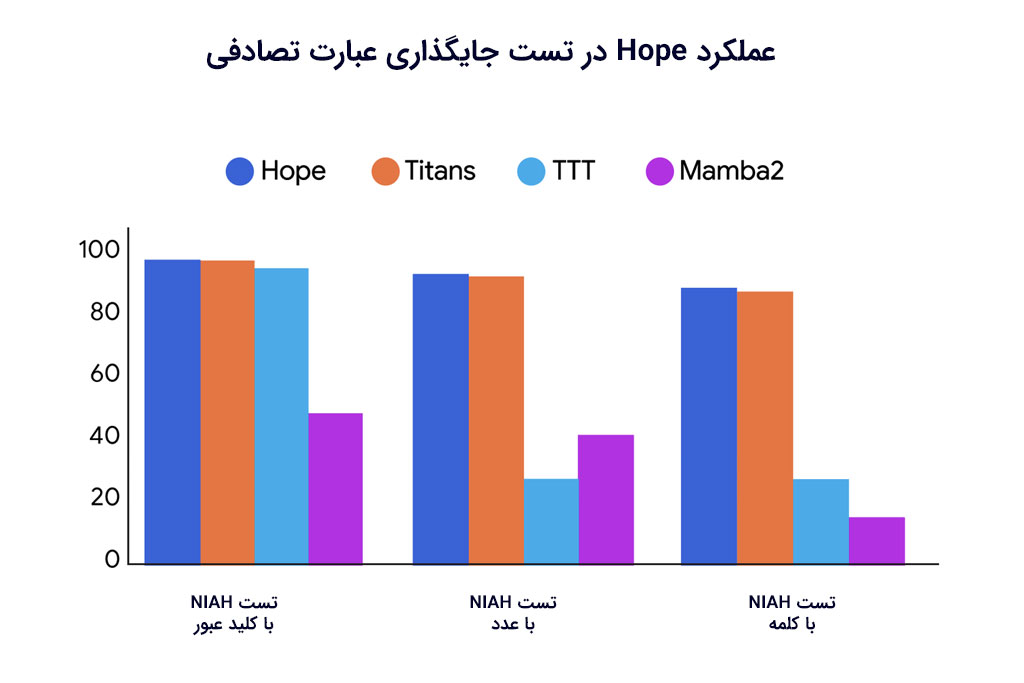
همانطور که در تصویر بالا مشاهده کردید، هوش مصنوعی Hope حافظه را بهتر از سایر معماریها در وظایف مختلف با زمینه طولانی مدیریت کرد. این نتیجه ثابت میکند که CMSها روشی کارآمدتر و موثرتر برای مدیریت توالیهای طولانی اطلاعات هستند.
تست NIAH، میزان توانایی یک LLM را در شناسایی دقیق اطلاعات یک پنجره متنی میسنجد. در این تست، یک عبارت تصادفی (معروف به “Needle”) در یک متن طولانی (“Haystack”) جا داده میشود و مدل را وادار میکنند که عبارت را بازیابی کند.
نتیجهگیری؛ آیا Hope ما را به AGI میرساند؟
متخصصان میگویند بله؛ رسیدن به AGI با ساختن هوش مصنوعی Hope و معماری MoE خیلی نزدیک است؛ اما برخی دیگر از کارشناسان و رهبران AI میگویند که همچنان محدودیتهای سختافزاری و منابع محاسباتی، مشکلات بزرگتری در مسیر رسیدن به AGI هستند که با این رویکرد هم حل نمیشود.
با تمام این اوصاف، حالا میدانیم که گوگل با آزمایشگاه هوش مصنوعی و واحد DeepMind خود، تلاش دارد مدال طلای پیشروی در AI را دستش بگیرد و روی سکوی اول بایستد. درحالحاضر هم توانسته با مدالش روی این سکو بماند. اما چه کسی میداند مسیر AGI با چه فرازونشیبها و احتمالا چالشهای عمدی مواجه میشود؟ شاید رویکرد Hope هم نتواند موانع را بردارد و همچنان نزدیک به یک دهه با AGI فاصله داشته باشیم.
سوالات متداول
ابزار هوش مصنوعی Hope به مدلها اجازه میدهد که بهصورت مداوم – احتمالا مادامالعمر – دانش جدید را یاد بگیرند؛ بدون اینکه دانش قبلی را فراموش کنند.
هوش مصنوعی Hope یک رویکرد جدید و معرفیشده توسط گوگل است که مشکل فراموش شدن دانش قبلی را در مدلهای LLM حل میکند.
خیر. AGI توانایی هوش مصنوعی در حل مسائل و استدلال، نزدیک به توانایی مغز انسان است؛ درحالیکه Hope یک رویکرد ساختهشده توسط گوگل است که مشکل فراموشی دانش در مدلهای کنونی را برطرف میکند.